 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2D: Selective Spectral Decay for Quantization-Friendly Conditioning of Neural Activations
Feb 16, 2026Activation outliers in large-scale transformer models pose a fundamental challenge to model quantization, creating excessively large ranges that cause severe accuracy drops during quantization. We empirically observe that outlier severity intensifies with pre-training scale (e.g., progressing from CLIP to the more extensively trained SigLIP and SigLIP2). Through theoretical analysis as well as empirical correlation studies, we establish the direct link between these activation outliers and dominant singular values of the weights. Building on this insight, we propose Selective Spectral Decay ($S^2D$), a geometrically-principled conditioning method that surgically regularizes only the weight components corresponding to the largest singular values during fine-tuning. Through extensive experiments, we demonstrate that $S^2D$ significantly reduces activation outliers and produces well-conditioned representations that are inherently quantization-friendly. Models trained with $S^2D$ achieve up to 7% improved PTQ accuracy on ImageNet under W4A4 quantization and 4% gains when combined with QAT. These improvements also generalize across downstream tasks and vision-language models, enabling the scaling of increasingly large and rigorously trained models without sacrificing deployment efficiency.
Surgical Feature-Space Decomposition of LLMs: Why, When and How?
May 17, 2024



Low-rank approximations, of the weight and feature space can enhance the performance of deep learning models, whether in terms of improving generalization or reducing the latency of inference. However, there is no clear consensus yet on \emph{how}, \emph{when} and \emph{why} these approximations are helpful for large language models (LLMs). In this work, we empirically study the efficacy of weight and feature space decomposition in transformer-based LLMs. We demonstrate that surgical decomposition not only provides critical insights into the trade-off between compression and language modelling performance, but also sometimes enhances commonsense reasoning performance of LLMs. Our empirical analysis identifies specific network segments that intrinsically exhibit a low-rank structure. Furthermore, we extend our investigation to the implications of low-rank approximations on model bias. Overall, our findings offer a novel perspective on optimizing LLMs, presenting the low-rank approximation not only as a tool for performance enhancements, but also as a means to potentially rectify biases within these models. Our code is available at \href{https://github.com/nyunAI/SFSD-LLM}{GitHub}.
Rethinking Compression: Reduced Order Modelling of Latent Features in Large Language Models
Dec 12, 2023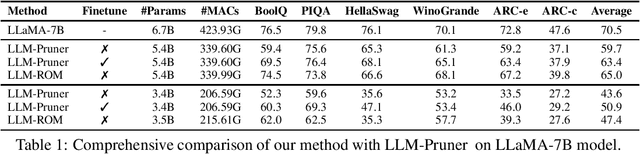

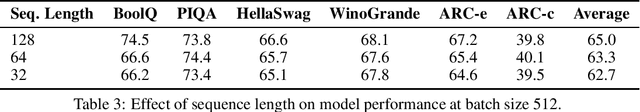
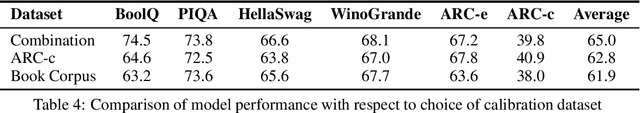
Due to the substantial scale of Large Language Models (LLMs), the direct application of conventional compression methodologies proves impractical. The computational demands associated with even minimal gradient updates present challenges, particularly on consumer-grade hardware. This paper introduces an innovative approach for the parametric and practical compression of LLMs based on reduced order modelling, which entails low-rank decomposition within the feature space and re-parameterization in the weight space. Notably, this compression technique operates in a layer-wise manner, obviating the need for a GPU device and enabling the compression of billion-scale models within stringent constraints of both memory and time. Our method represents a significant advancement in model compression by leveraging matrix decomposition, demonstrating superior efficacy compared to the prevailing state-of-the-art structured pruning method.