 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatérn Noise for Triangulation-Agnostic Flow Matching on Meshes
May 19, 2026This paper tackles the task of learning to generate signals over triangle meshes in a triangulation-agnostic manner, meaning the trained model can be applied to different meshes and triangulations effectively. Practically, the paper adapts the flow matching (FM) paradigm to a mesh-based, triangulation-agnostic setting. Theoretically, it proposes a specific noise distribution which is triangulation agnostic, to be used inside the FM model's denoising process. While noise distributions are usually trivial to devise for, e.g., images, devising a triangulation-agnostic distribution proves to be a much more difficult task. We formulate a mathematical definition of triangulation agnosticism of distributions, via their spectrum. We then show that a discretization of a specific Gaussian random field called a Matérn process holds these desired properties, and provides a simple and efficient sampling algorithm. We use it as our noise model, and adapt FM to the triangulation-agnostic setting by using a state-of-the-art approach for learning signals on meshes in the gradient domain -- PoissonNet -- as the denoiser. We conduct experiments on elaborate tasks such as sampling elastic rest states, and generating poses of humanoids. Our method is shown to be capable of producing highly realistic results for meshes of over one million triangles, significantly exceeding the state-of-the-art in quality and diversity.
PoissonNet: A Local-Global Approach for Learning on Surfaces
Oct 15, 2025Many network architectures exist for learning on meshes, yet their constructions entail delicate trade-offs between difficulty learning high-frequency features, insufficient receptive field, sensitivity to discretization, and inefficient computational overhead. Drawing from classic local-global approaches in mesh processing, we introduce PoissonNet, a novel neural architecture that overcomes all of these deficiencies by formulating a local-global learning scheme, which uses Poisson's equation as the primary mechanism for feature propagation. Our core network block is simple; we apply learned local feature transformations in the gradient domain of the mesh, then solve a Poisson system to propagate scalar feature updates across the surface globally. Our local-global learning framework preserves the features's full frequency spectrum and provides a truly global receptive field, while remaining agnostic to mesh triangulation. Our construction is efficient, requiring far less compute overhead than comparable methods, which enables scalability -- both in the size of our datasets, and the size of individual training samples. These qualities are validated on various experiments where, compared to previous intrinsic architectures, we attain state-of-the-art performance on semantic segmentation and parameterizing highly-detailed animated surfaces. Finally, as a central application of PoissonNet, we show its ability to learn deformations, significantly outperforming state-of-the-art architectures that learn on surfaces.
Explorable Mesh Deformation Subspaces from Unstructured Generative Models
Oct 11, 2023



Exploring variations of 3D shapes is a time-consuming process in traditional 3D modeling tools. Deep generative models of 3D shapes often feature continuous latent spaces that can, in principle, be used to explore potential variations starting from a set of input shapes. In practice, doing so can be problematic: latent spaces are high dimensional and hard to visualize, contain shapes that are not relevant to the input shapes, and linear paths through them often lead to sub-optimal shape transitions. Furthermore, one would ideally be able to explore variations in the original high-quality meshes used to train the generative model, not its lower-quality output geometry. In this paper, we present a method to explore variations among a given set of landmark shapes by constructing a mapping from an easily-navigable 2D exploration space to a subspace of a pre-trained generative model. We first describe how to find a mapping that spans the set of input landmark shapes and exhibits smooth variations between them. We then show how to turn the variations in this subspace into deformation fields, to transfer those variations to high-quality meshes for the landmark shapes. Our results show that our method can produce visually-pleasing and easily-navigable 2D exploration spaces for several different shape categories, especially as compared to prior work on learning deformation spaces for 3D shapes.
Learning Transferable 3D Adversarial Cloaks for Deep Trained Detectors
Apr 22, 2021
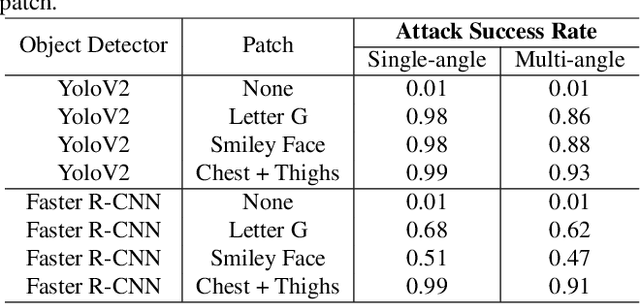
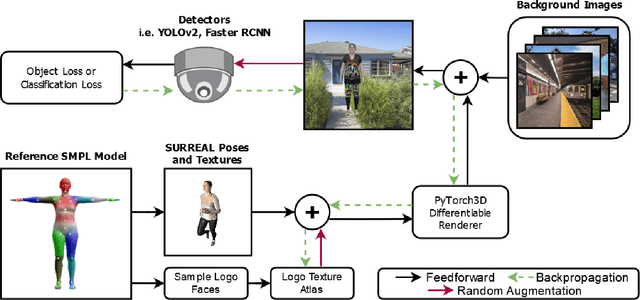
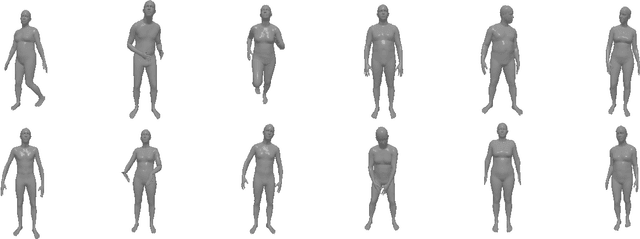
This paper presents a novel patch-based adversarial attack pipeline that trains adversarial patches on 3D human meshes. We sample triangular faces on a reference human mesh, and create an adversarial texture atlas over those faces. The adversarial texture is transferred to human meshes in various poses, which are rendered onto a collection of real-world background images. Contrary to the traditional patch-based adversarial attacks, where prior work attempts to fool trained object detectors using appended adversarial patches, this new form of attack is mapped into the 3D object world and back-propagated to the texture atlas through differentiable rendering. As such, the adversarial patch is trained under deformation consistent with real-world materials. In addition, and unlike existing adversarial patches, our new 3D adversarial patch is shown to fool state-of-the-art deep object detectors robustly under varying views, potentially leading to an attacking scheme that is persistently strong in the physical world.
Playing Chess with Limited Look Ahead
Jul 04, 2020
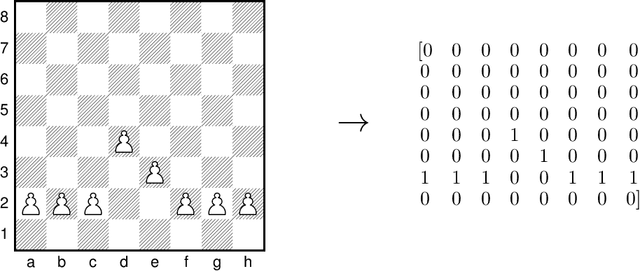
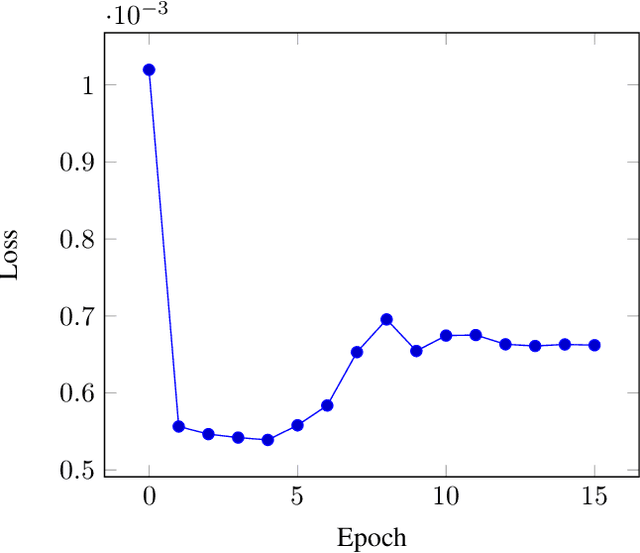
We have seen numerous machine learning methods tackle the game of chess over the years. However, one common element in these works is the necessity of a finely optimized look ahead algorithm. The particular interest of this research lies with creating a chess engine that is highly capable, but restricted in its look ahead depth. We train a deep neural network to serve as a static evaluation function, which is accompanied by a relatively simple look ahead algorithm. We show that our static evaluation function has encoded some semblance of look ahead knowledge, and is comparable to classical evaluation functions. The strength of our chess engine is assessed by comparing its proposed moves against those proposed by Stockfish. We show that, despite strict restrictions on look ahead depth, our engine recommends moves of equal strength in roughly $83\%$ of our sample positions.