 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding for Tomorrow: Assessing the Temporal Persistence of Text Classifiers
May 19, 2022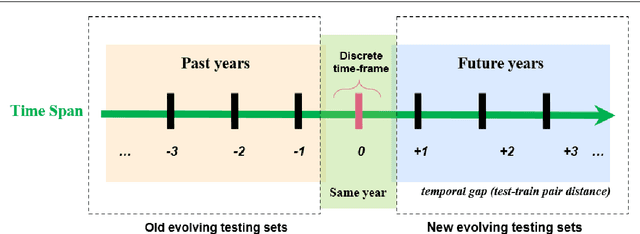
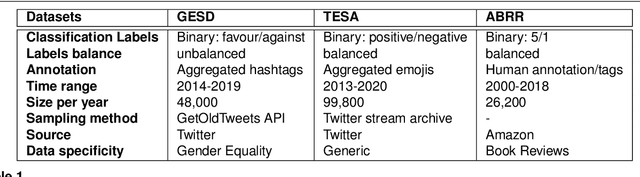
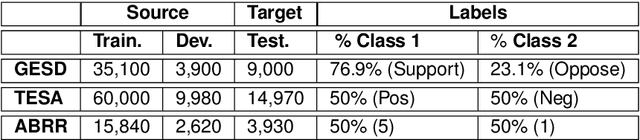
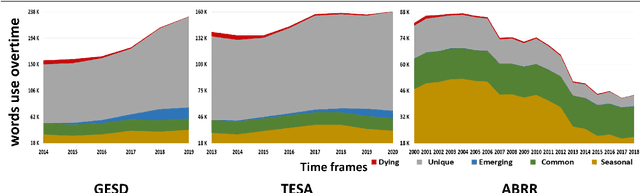
Where performance of text classification models drops over time due to changes in data, development of models whose performance persists over time is important. An ability to predict a model's ability to persist over time can help design models that can be effectively used over a longer period of time. In this paper, we look at this problem from a practical perspective by assessing the ability of a wide range of language models and classification algorithms to persist over time, as well as how dataset characteristics can help predict the temporal stability of different models. We perform longitudinal classification experiments on three datasets spanning between 6 and 19 years, and involving diverse tasks and types of data. We find that one can estimate how a model will retain its performance over time based on (i) how well the model performs over a restricted time period and its extrapolation to a longer time period, and (ii) the linguistic characteristics of the dataset, such as the familiarity score between subsets from different years. Findings from these experiments have important implications for the design of text classification models with the aim of preserving performance over time.
Aggregating Pairwise Semantic Differences for Few-Shot Claim Veracity Classification
May 11, 2022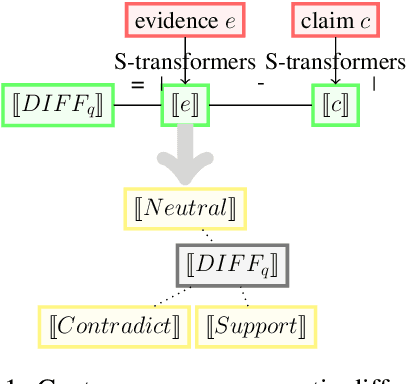
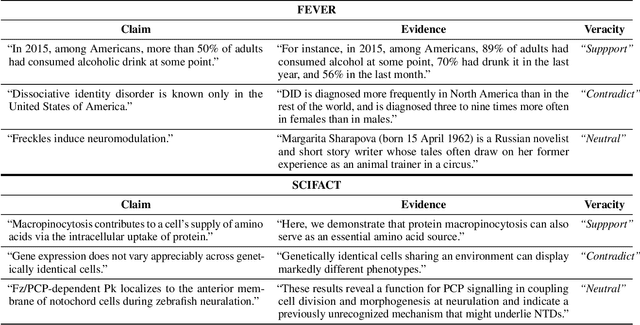
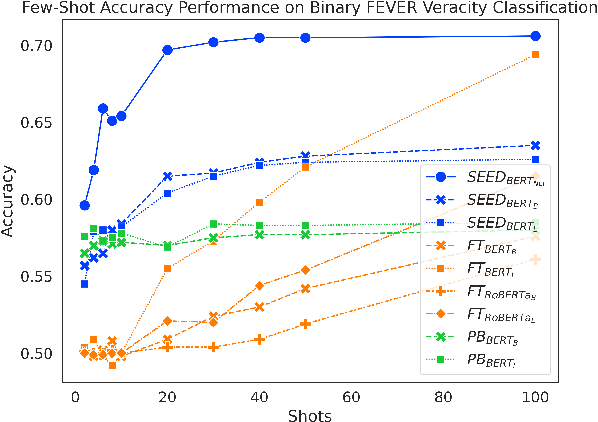
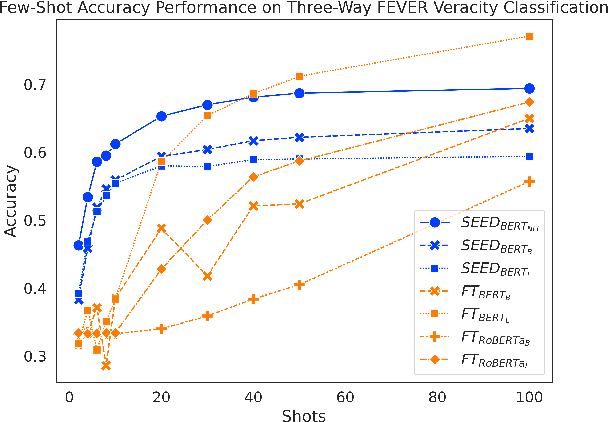
As part of an automated fact-checking pipeline, the claim veracity classification task consists in determining if a claim is supported by an associated piece of evidence. The complexity of gathering labelled claim-evidence pairs leads to a scarcity of datasets, particularly when dealing with new domains. In this paper, we introduce SEED, a novel vector-based method to few-shot claim veracity classification that aggregates pairwise semantic differences for claim-evidence pairs. We build on the hypothesis that we can simulate class representative vectors that capture average semantic differences for claim-evidence pairs in a class, which can then be used for classification of new instances. We compare the performance of our method with competitive baselines including fine-tuned BERT/RoBERTa models, as well as the state-of-the-art few-shot veracity classification method that leverages language model perplexity. Experiments conducted on the FEVER and SCIFACT datasets show consistent improvements over competitive baselines in few-shot settings. Our code is available.
Natural Language Inference with Self-Attention for Veracity Assessment of Pandemic Claims
May 05, 2022
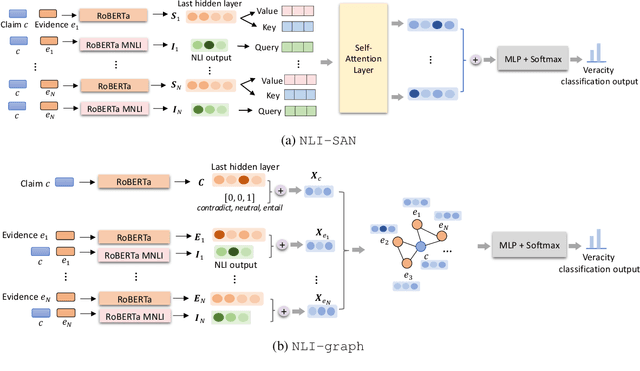

We present a comprehensive work on automated veracity assessment from dataset creation to developing novel methods based on Natural Language Inference (NLI), focusing on misinformation related to the COVID-19 pandemic. We first describe the construction of the novel PANACEA dataset consisting of heterogeneous claims on COVID-19 and their respective information sources. The dataset construction includes work on retrieval techniques and similarity measurements to ensure a unique set of claims. We then propose novel techniques for automated veracity assessment based on Natural Language Inference including graph convolutional networks and attention based approaches. We have carried out experiments on evidence retrieval and veracity assessment on the dataset using the proposed techniques and found them competitive with SOTA methods, and provided a detailed discussion.
Hidden behind the obvious: misleading keywords and implicitly abusive language on social media
May 03, 2022
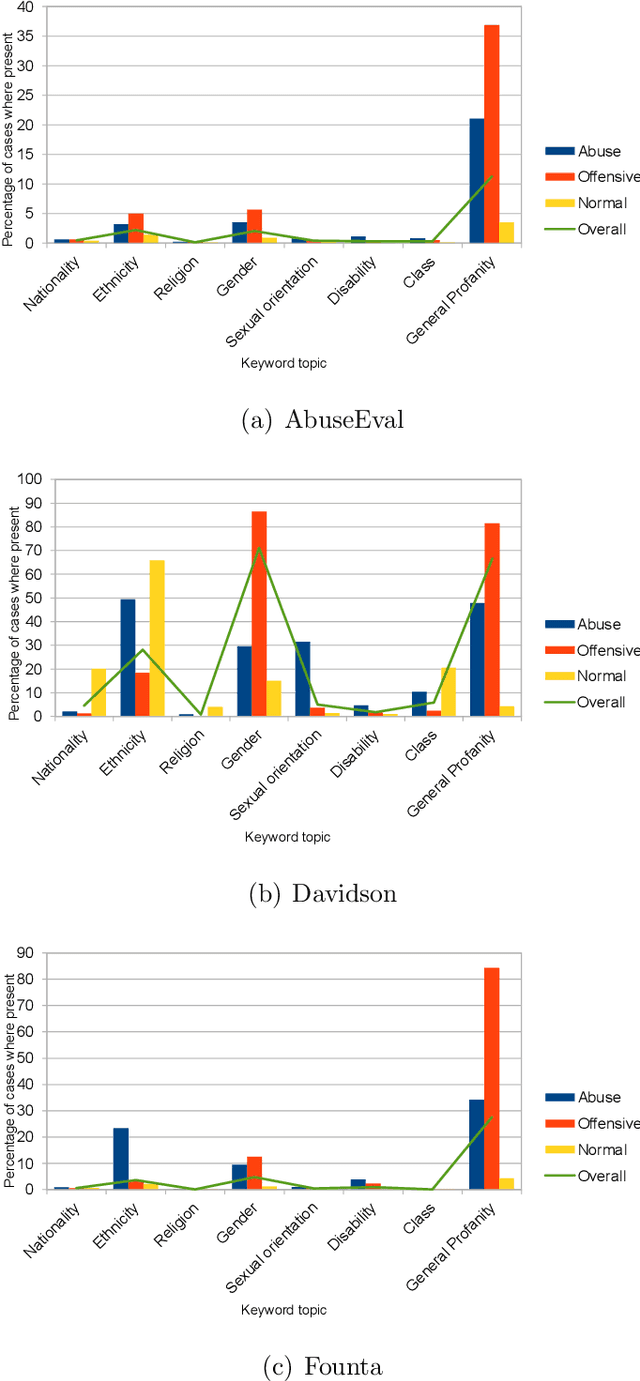
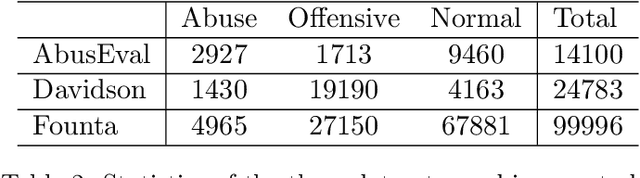
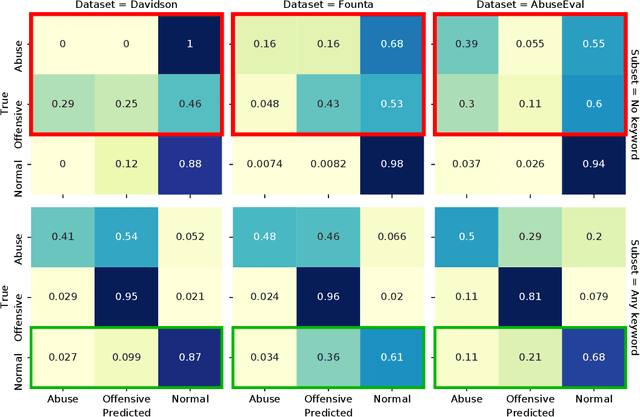
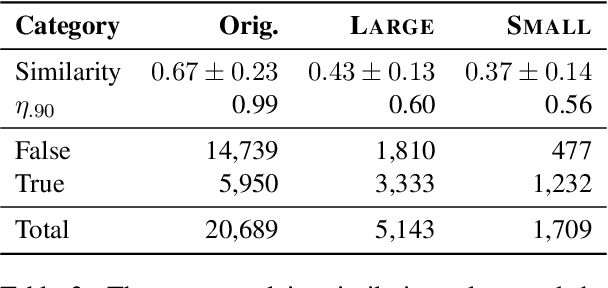
While social media offers freedom of self-expression, abusive language carry significant negative social impact. Driven by the importance of the issue, research in the automated detection of abusive language has witnessed growth and improvement. However, these detection models display a reliance on strongly indicative keywords, such as slurs and profanity. This means that they can falsely (1a) miss abuse without such keywords or (1b) flag non-abuse with such keywords, and that (2) they perform poorly on unseen data. Despite the recognition of these problems, gaps and inconsistencies remain in the literature. In this study, we analyse the impact of keywords from dataset construction to model behaviour in detail, with a focus on how models make mistakes on (1a) and (1b), and how (1a) and (1b) interact with (2). Through the analysis, we provide suggestions for future research to address all three problems.
Cyberbullying detection across social media platforms via platform-aware adversarial encoding
Apr 01, 2022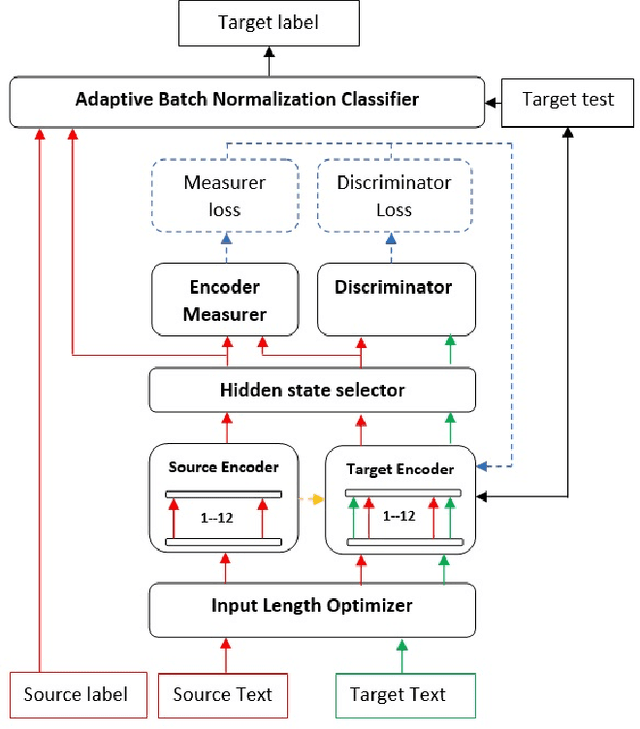

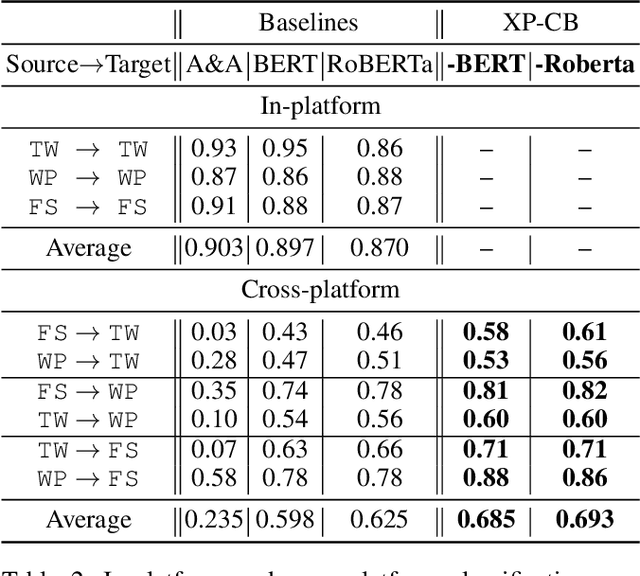

Despite the increasing interest in cyberbullying detection, existing efforts have largely been limited to experiments on a single platform and their generalisability across different social media platforms have received less attention. We propose XP-CB, a novel cross-platform framework based on Transformers and adversarial learning. XP-CB can enhance a Transformer leveraging unlabelled data from the source and target platforms to come up with a common representation while preventing platform-specific training. To validate our proposed framework, we experiment on cyberbullying datasets from three different platforms through six cross-platform configurations, showing its effectiveness with both BERT and RoBERTa as the underlying Transformer models.
Sexism Identification in Tweets and Gabs using Deep Neural Networks
Nov 05, 2021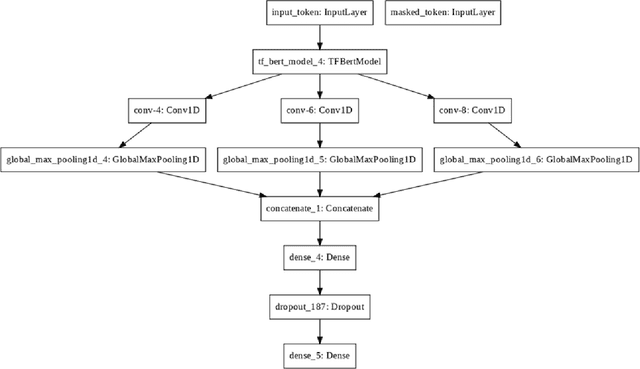
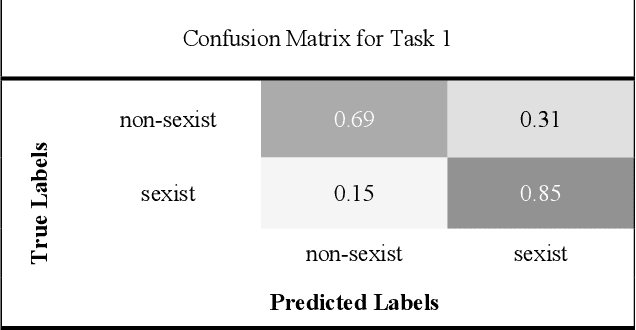

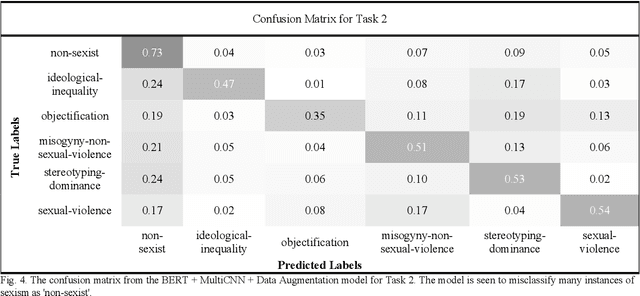
Through anonymisation and accessibility, social media platforms have facilitated the proliferation of hate speech, prompting increased research in developing automatic methods to identify these texts. This paper explores the classification of sexism in text using a variety of deep neural network model architectures such as Long-Short-Term Memory (LSTMs) and Convolutional Neural Networks (CNNs). These networks are used in conjunction with transfer learning in the form of Bidirectional Encoder Representations from Transformers (BERT) and DistilBERT models, along with data augmentation, to perform binary and multiclass sexism classification on the dataset of tweets and gabs from the sEXism Identification in Social neTworks (EXIST) task in IberLEF 2021. The models are seen to perform comparatively to those from the competition, with the best performances seen using BERT and a multi-filter CNN model. Data augmentation further improves these results for the multi-class classification task. This paper also explores the errors made by the models and discusses the difficulty in automatically classifying sexism due to the subjectivity of the labels and the complexity of natural language used in social media.
Cross-lingual Hate Speech Detection using Transformer Models
Nov 01, 2021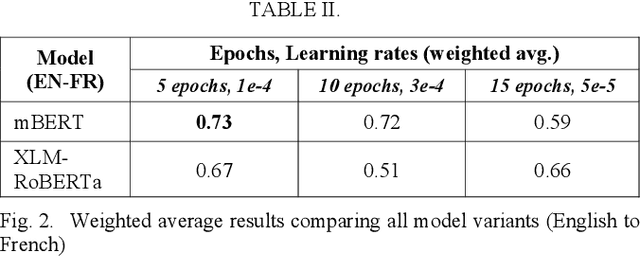
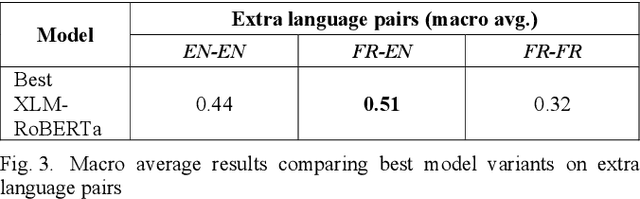
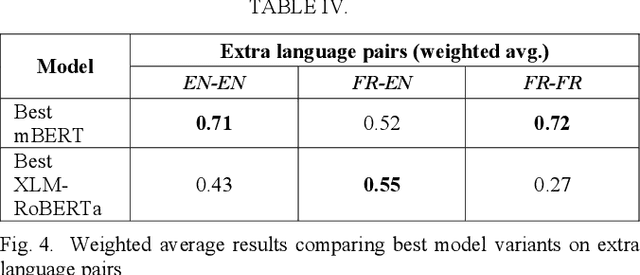
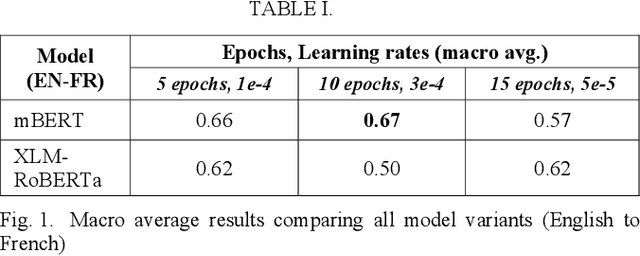
Hate speech detection within a cross-lingual setting represents a paramount area of interest for all medium and large-scale online platforms. Failing to properly address this issue on a global scale has already led over time to morally questionable real-life events, human deaths, and the perpetuation of hate itself. This paper illustrates the capabilities of fine-tuned altered multi-lingual Transformer models (mBERT, XLM-RoBERTa) regarding this crucial social data science task with cross-lingual training from English to French, vice-versa and each language on its own, including sections about iterative improvement and comparative error analysis.
Automated Fact-Checking: A Survey
Sep 23, 2021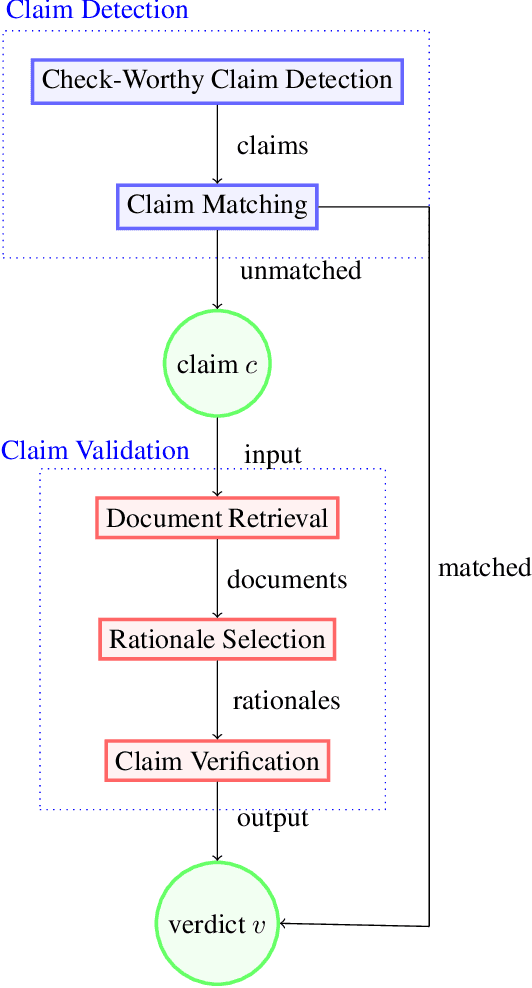
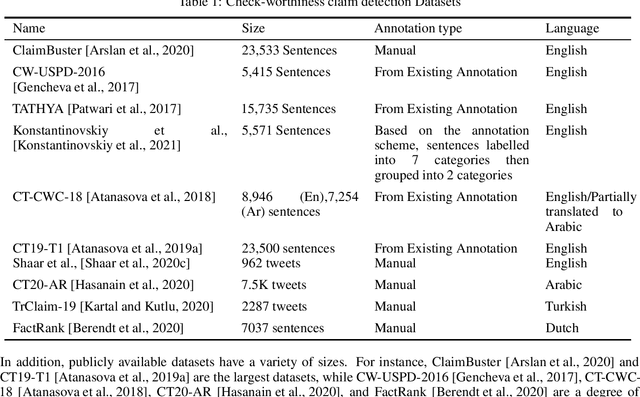
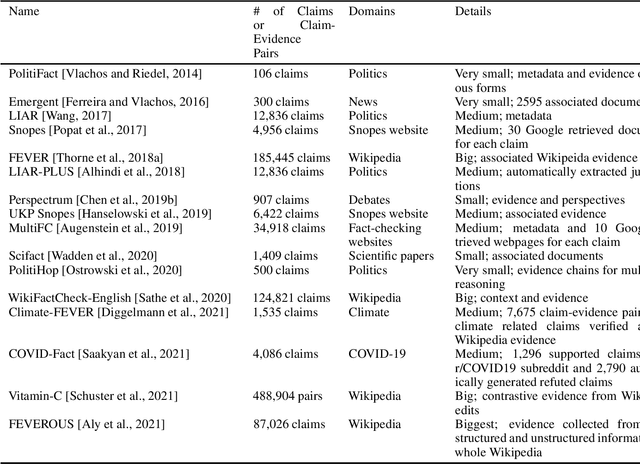
As online false information continues to grow, automated fact-checking has gained an increasing amount of attention in recent years. Researchers in the field of Natural Language Processing (NLP) have contributed to the task by building fact-checking datasets, devising automated fact-checking pipelines and proposing NLP methods to further research in the development of different components. This paper reviews relevant research on automated fact-checking covering both the claim detection and claim validation components.
A Longitudinal Multi-modal Dataset for Dementia Monitoring and Diagnosis
Sep 03, 2021
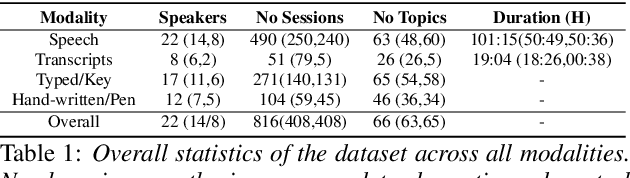
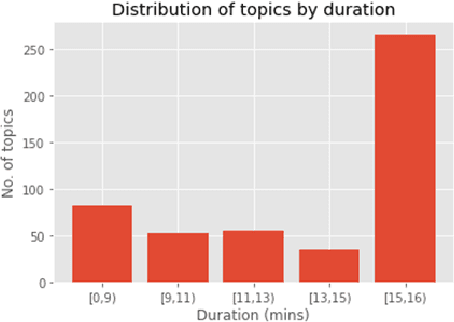
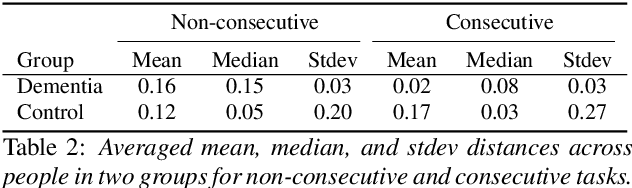
Dementia is a family of neurogenerative conditions affecting memory and cognition in an increasing number of individuals in our globally aging population. Automated analysis of language, speech and paralinguistic indicators have been gaining popularity as potential indicators of cognitive decline. Here we propose a novel longitudinal multi-modal dataset collected from people with mild dementia and age matched controls over a period of several months in a natural setting. The multi-modal data consists of spoken conversations, a subset of which are transcribed, as well as typed and written thoughts and associated extra-linguistic information such as pen strokes and keystrokes. We describe the dataset in detail and proceed to focus on a task using the speech modality. The latter involves distinguishing controls from people with dementia by exploiting the longitudinal nature of the data. Our experiments showed significant differences in how the speech varied from session to session in the control and dementia groups.
Capturing Stance Dynamics in Social Media: Open Challenges and Research Directions
Sep 01, 2021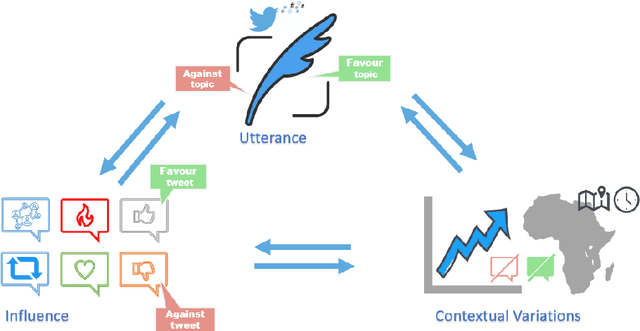
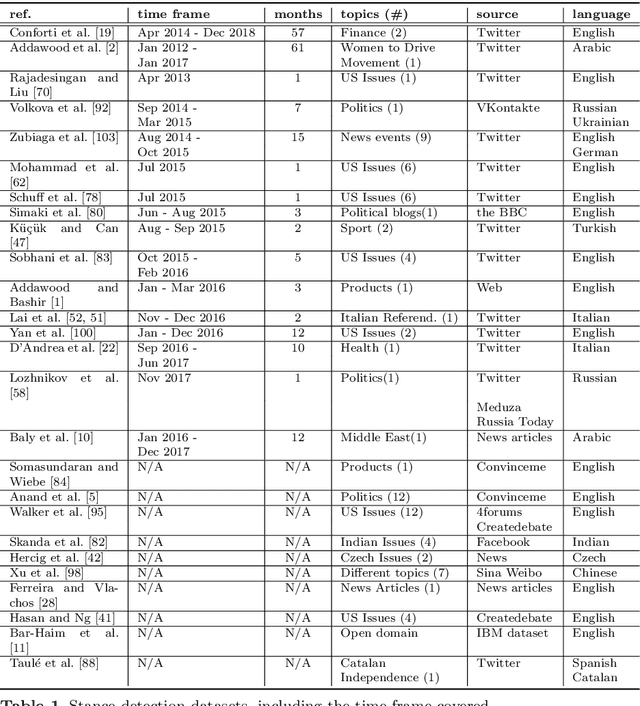
Social media platforms provide a goldmine for mining public opinion on issues of wide societal interest. Opinion mining is a problem that can be operationalised by capturing and aggregating the stance of individual social media posts as supporting, opposing or being neutral towards the issue at hand. While most prior work in stance detection has investigated datasets with limited time coverage, interest in investigating longitudinal datasets has recently increased. Evolving dynamics in linguistic and behavioural patterns observed in new data require in turn adapting stance detection systems to deal with the changes. In this survey paper, we investigate the intersection between computational linguistics and the temporal evolution of human communication in digital media. We perform a critical review in emerging research considering dynamics, exploring different semantic and pragmatic factors that impact linguistic data in general, and stance particularly. We further discuss current directions in capturing stance dynamics in social media. We organise the challenges of dealing with stance dynamics, identify open challenges and discuss future directions in three key dimensions: utterance, context and influence.