 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Recommendation: Attack of the Learned Fake Users
Sep 21, 2018

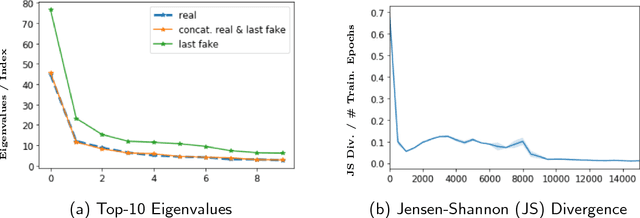
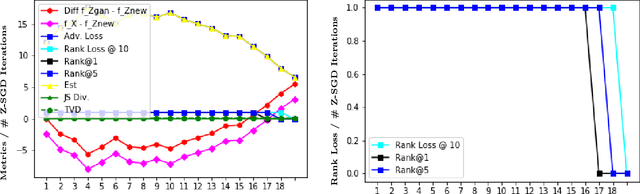
Can machine learning models for recommendation be easily fooled? While the question has been answered for hand-engineered fake user profiles, it has not been explored for machine learned adversarial attacks. This paper attempts to close this gap. We propose a framework for generating fake user profiles which, when incorporated in the training of a recommendation system, can achieve an adversarial intent, while remaining indistinguishable from real user profiles. We formulate this procedure as a repeated general-sum game between two players: an oblivious recommendation system $R$ and an adversarial fake user generator $A$ with two goals: (G1) the rating distribution of the fake users needs to be close to the real users, and (G2) some objective $f_A$ encoding the attack intent, such as targeting the top-K recommendation quality of $R$ for a subset of users, needs to be optimized. We propose a learning framework to achieve both goals, and offer extensive experiments considering multiple types of attacks highlighting the vulnerability of recommendation systems.
Time Series Deinterleaving of DNS Traffic
Jul 16, 2018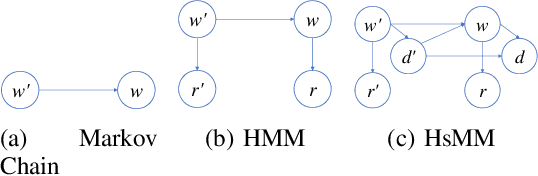
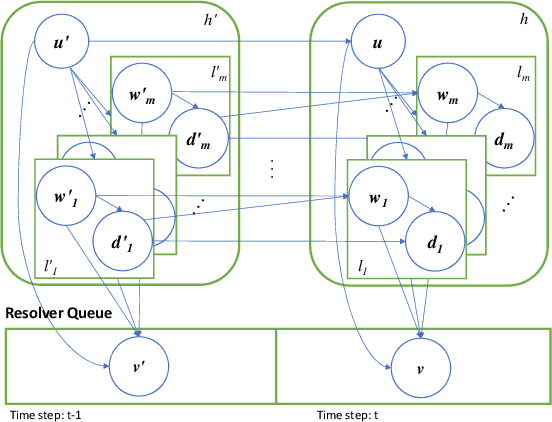

Stream deinterleaving is an important problem with various applications in the cybersecurity domain. In this paper, we consider the specific problem of deinterleaving DNS data streams using machine-learning techniques, with the objective of automating the extraction of malware domain sequences. We first develop a generative model for user request generation and DNS stream interleaving. Based on these we evaluate various inference strategies for deinterleaving including augmented HMMs and LSTMs on synthetic datasets. Our results demonstrate that state-of-the-art LSTMs outperform more traditional augmented HMMs in this application domain.
High Dimensional Data Enrichment: Interpretable, Fast, and Data-Efficient
Jun 15, 2018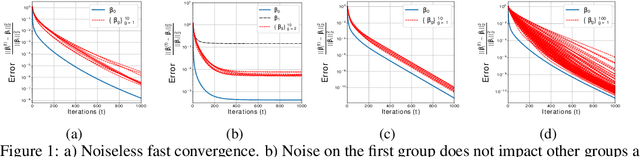

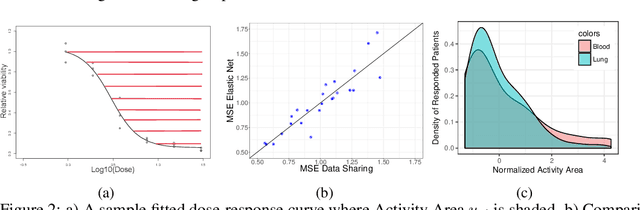
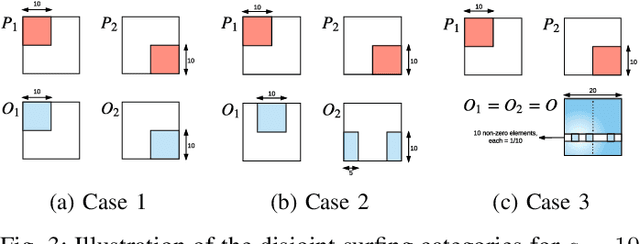
High dimensional structured data enriched model describes groups of observations by shared and per-group individual parameters, each with its own structure such as sparsity or group sparsity. In this paper, we consider the general form of data enrichment where data comes in a fixed but arbitrary number of groups G. Any convex function, e.g., norms, can characterize the structure of both shared and individual parameters. We propose an estimator for high dimensional data enriched model and provide conditions under which it consistently estimates both shared and individual parameters. We also delineate sample complexity of the estimator and present high probability non-asymptotic bound on estimation error of all parameters. Interestingly the sample complexity of our estimator translates to conditions on both per-group sample sizes and the total number of samples. We propose an iterative estimation algorithm with linear convergence rate and supplement our theoretical analysis with synthetic and real experimental results. Particularly, we show the predictive power of data-enriched model along with its interpretable results in anticancer drug sensitivity analysis.
Topic Modeling on Health Journals with Regularized Variational Inference
Jan 15, 2018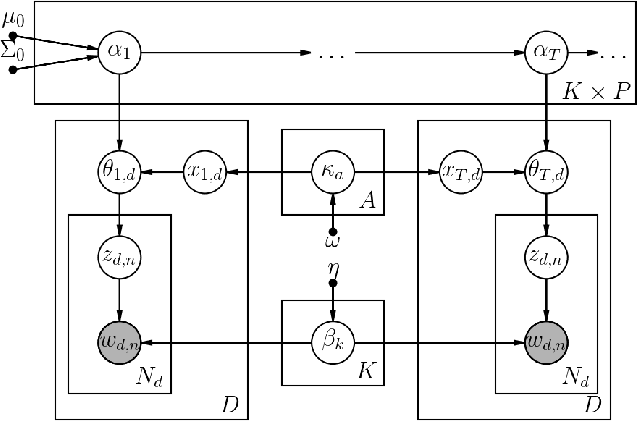

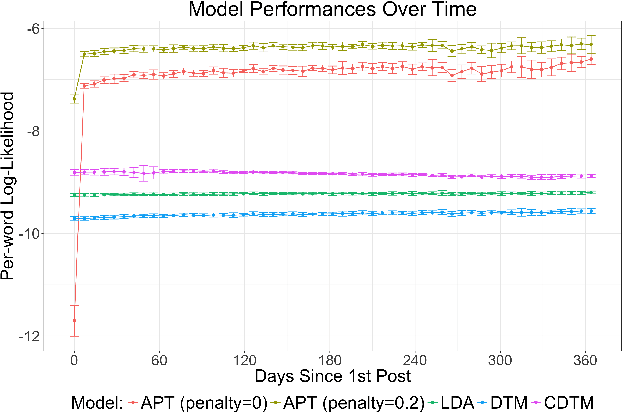
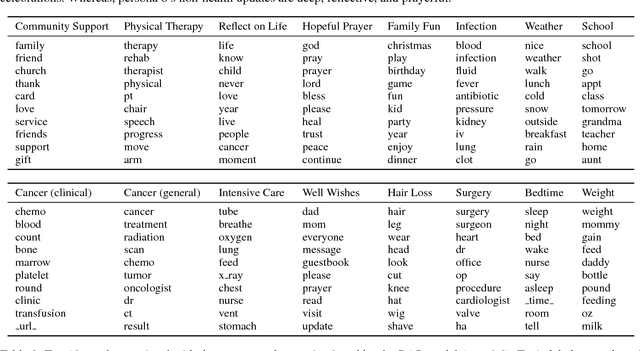
Topic modeling enables exploration and compact representation of a corpus. The CaringBridge (CB) dataset is a massive collection of journals written by patients and caregivers during a health crisis. Topic modeling on the CB dataset, however, is challenging due to the asynchronous nature of multiple authors writing about their health journeys. To overcome this challenge we introduce the Dynamic Author-Persona topic model (DAP), a probabilistic graphical model designed for temporal corpora with multiple authors. The novelty of the DAP model lies in its representation of authors by a persona --- where personas capture the propensity to write about certain topics over time. Further, we present a regularized variational inference algorithm, which we use to encourage the DAP model's personas to be distinct. Our results show significant improvements over competing topic models --- particularly after regularization, and highlight the DAP model's unique ability to capture common journeys shared by different authors.
Theory-guided Data Science: A New Paradigm for Scientific Discovery from Data
Nov 13, 2017

Data science models, although successful in a number of commercial domains, have had limited applicability in scientific problems involving complex physical phenomena. Theory-guided data science (TGDS) is an emerging paradigm that aims to leverage the wealth of scientific knowledge for improving the effectiveness of data science models in enabling scientific discovery. The overarching vision of TGDS is to introduce scientific consistency as an essential component for learning generalizable models. Further, by producing scientifically interpretable models, TGDS aims to advance our scientific understanding by discovering novel domain insights. Indeed, the paradigm of TGDS has started to gain prominence in a number of scientific disciplines such as turbulence modeling, material discovery, quantum chemistry, bio-medical science, bio-marker discovery, climate science, and hydrology. In this paper, we formally conceptualize the paradigm of TGDS and present a taxonomy of research themes in TGDS. We describe several approaches for integrating domain knowledge in different research themes using illustrative examples from different disciplines. We also highlight some of the promising avenues of novel research for realizing the full potential of theory-guided data science.
Sparse Linear Isotonic Models
Oct 16, 2017
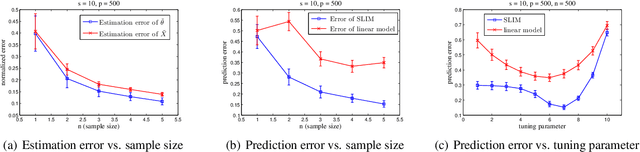
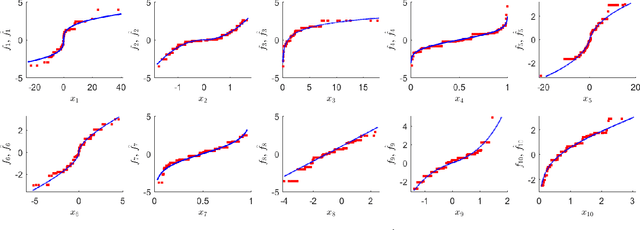
In machine learning and data mining, linear models have been widely used to model the response as parametric linear functions of the predictors. To relax such stringent assumptions made by parametric linear models, additive models consider the response to be a summation of unknown transformations applied on the predictors; in particular, additive isotonic models (AIMs) assume the unknown transformations to be monotone. In this paper, we introduce sparse linear isotonic models (SLIMs) for highdimensional problems by hybridizing ideas in parametric sparse linear models and AIMs, which enjoy a few appealing advantages over both. In the high-dimensional setting, a two-step algorithm is proposed for estimating the sparse parameters as well as the monotone functions over predictors. Under mild statistical assumptions, we show that the algorithm can accurately estimate the parameters. Promising preliminary experiments are presented to support the theoretical results.
High-Dimensional Dependency Structure Learning for Physical Processes
Sep 12, 2017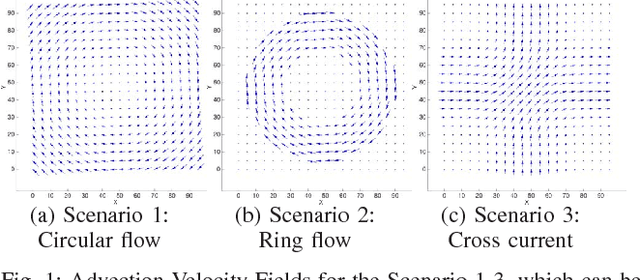
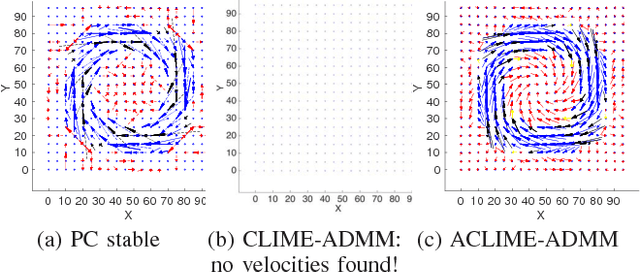
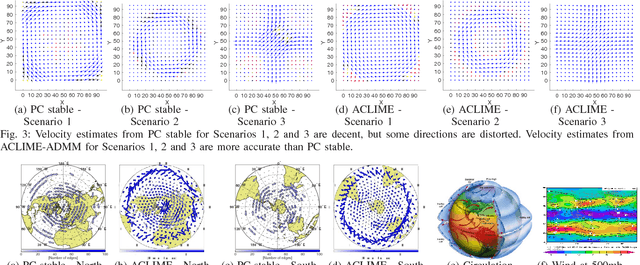
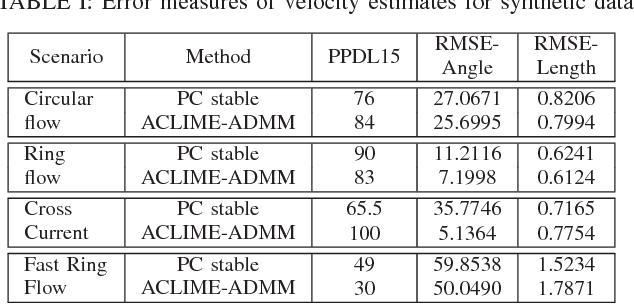
In this paper, we consider the use of structure learning methods for probabilistic graphical models to identify statistical dependencies in high-dimensional physical processes. Such processes are often synthetically characterized using PDEs (partial differential equations) and are observed in a variety of natural phenomena, including geoscience data capturing atmospheric and hydrological phenomena. Classical structure learning approaches such as the PC algorithm and variants are challenging to apply due to their high computational and sample requirements. Modern approaches, often based on sparse regression and variants, do come with finite sample guarantees, but are usually highly sensitive to the choice of hyper-parameters, e.g., parameter $\lambda$ for sparsity inducing constraint or regularization. In this paper, we present ACLIME-ADMM, an efficient two-step algorithm for adaptive structure learning, which estimates an edge specific parameter $\lambda_{ij}$ in the first step, and uses these parameters to learn the structure in the second step. Both steps of our algorithm use (inexact) ADMM to solve suitable linear programs, and all iterations can be done in closed form in an efficient block parallel manner. We compare ACLIME-ADMM with baselines on both synthetic data simulated by partial differential equations (PDEs) that model advection-diffusion processes, and real data (50 years) of daily global geopotential heights to study information flow in the atmosphere. ACLIME-ADMM is shown to be efficient, stable, and competitive, usually better than the baselines especially on difficult problems. On real data, ACLIME-ADMM recovers the underlying structure of global atmospheric circulation, including switches in wind directions at the equator and tropics entirely from the data.
R2N2: Residual Recurrent Neural Networks for Multivariate Time Series Forecasting
Sep 10, 2017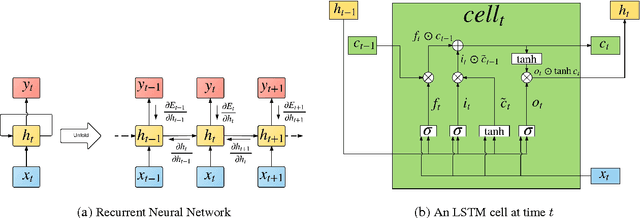
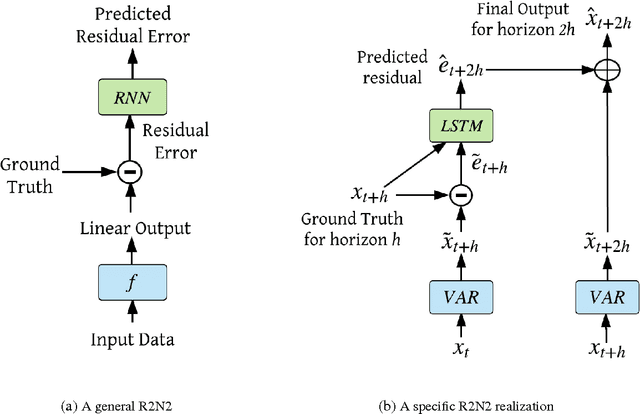
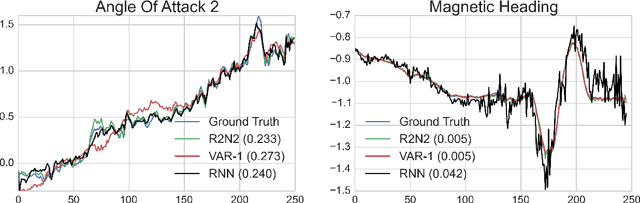
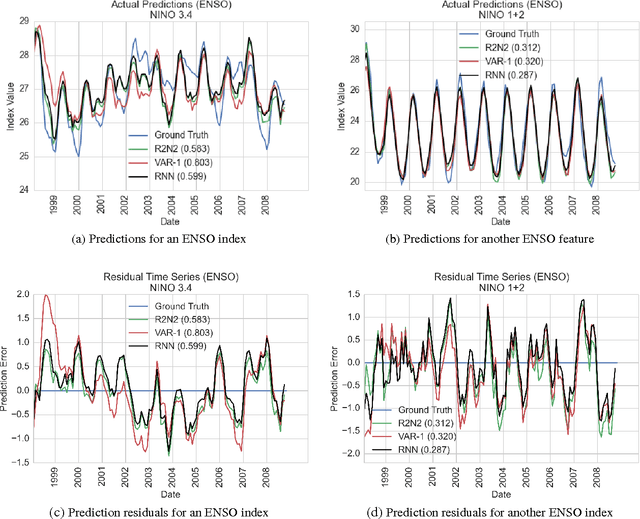
Multivariate time-series modeling and forecasting is an important problem with numerous applications. Traditional approaches such as VAR (vector auto-regressive) models and more recent approaches such as RNNs (recurrent neural networks) are indispensable tools in modeling time-series data. In many multivariate time series modeling problems, there is usually a significant linear dependency component, for which VARs are suitable, and a nonlinear component, for which RNNs are suitable. Modeling such times series with only VAR or only RNNs can lead to poor predictive performance or complex models with large training times. In this work, we propose a hybrid model called R2N2 (Residual RNN), which first models the time series with a simple linear model (like VAR) and then models its residual errors using RNNs. R2N2s can be trained using existing algorithms for VARs and RNNs. Through an extensive empirical evaluation on two real world datasets (aviation and climate domains), we show that R2N2 is competitive, usually better than VAR or RNN, used alone. We also show that R2N2 is faster to train as compared to an RNN, while requiring less number of hidden units.
High Dimensional Structured Superposition Models
May 30, 2017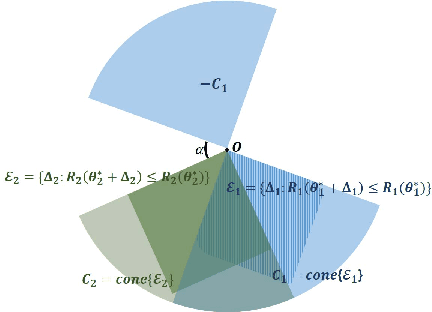
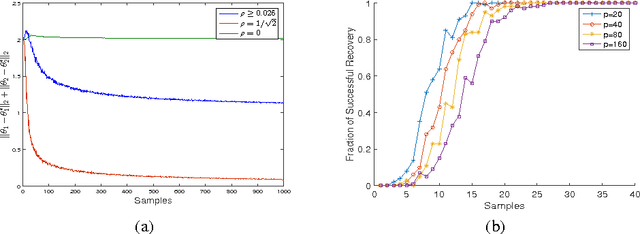
High dimensional superposition models characterize observations using parameters which can be written as a sum of multiple component parameters, each with its own structure, e.g., sum of low rank and sparse matrices, sum of sparse and rotated sparse vectors, etc. In this paper, we consider general superposition models which allow sum of any number of component parameters, and each component structure can be characterized by any norm. We present a simple estimator for such models, give a geometric condition under which the components can be accurately estimated, characterize sample complexity of the estimator, and give high probability non-asymptotic bounds on the componentwise estimation error. We use tools from empirical processes and generic chaining for the statistical analysis, and our results, which substantially generalize prior work on superposition models, are in terms of Gaussian widths of suitable sets.
Recommendation under Capacity Constraints
Mar 12, 2017
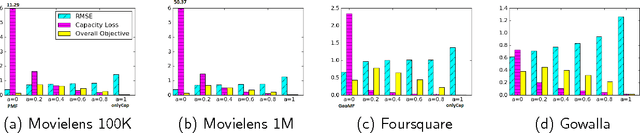
In this paper, we investigate the common scenario where every candidate item for recommendation is characterized by a maximum capacity, i.e., number of seats in a Point-of-Interest (POI) or size of an item's inventory. Despite the prevalence of the task of recommending items under capacity constraints in a variety of settings, to the best of our knowledge, none of the known recommender methods is designed to respect capacity constraints. To close this gap, we extend three state-of-the art latent factor recommendation approaches: probabilistic matrix factorization (PMF), geographical matrix factorization (GeoMF), and bayesian personalized ranking (BPR), to optimize for both recommendation accuracy and expected item usage that respects the capacity constraints. We introduce the useful concepts of user propensity to listen and item capacity. Our experimental results in real-world datasets, both for the domain of item recommendation and POI recommendation, highlight the benefit of our method for the setting of recommendation under capacity constraints.