 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Bandits with Online Neural Regression
Dec 12, 2023



Recent works have shown a reduction from contextual bandits to online regression under a realizability assumption [Foster and Rakhlin, 2020, Foster and Krishnamurthy, 2021]. In this work, we investigate the use of neural networks for such online regression and associated Neural Contextual Bandits (NeuCBs). Using existing results for wide networks, one can readily show a ${\mathcal{O}}(\sqrt{T})$ regret for online regression with square loss, which via the reduction implies a ${\mathcal{O}}(\sqrt{K} T^{3/4})$ regret for NeuCBs. Departing from this standard approach, we first show a $\mathcal{O}(\log T)$ regret for online regression with almost convex losses that satisfy QG (Quadratic Growth) condition, a generalization of the PL (Polyak-\L ojasiewicz) condition, and that have a unique minima. Although not directly applicable to wide networks since they do not have unique minima, we show that adding a suitable small random perturbation to the network predictions surprisingly makes the loss satisfy QG with unique minima. Based on such a perturbed prediction, we show a ${\mathcal{O}}(\log T)$ regret for online regression with both squared loss and KL loss, and subsequently convert these respectively to $\tilde{\mathcal{O}}(\sqrt{KT})$ and $\tilde{\mathcal{O}}(\sqrt{KL^*} + K)$ regret for NeuCB, where $L^*$ is the loss of the best policy. Separately, we also show that existing regret bounds for NeuCBs are $\Omega(T)$ or assume i.i.d. contexts, unlike this work. Finally, our experimental results on various datasets demonstrate that our algorithms, especially the one based on KL loss, persistently outperform existing algorithms.
AmbientFlow: Invertible generative models from incomplete, noisy measurements
Sep 09, 2023Generative models have gained popularity for their potential applications in imaging science, such as image reconstruction, posterior sampling and data sharing. Flow-based generative models are particularly attractive due to their ability to tractably provide exact density estimates along with fast, inexpensive and diverse samples. Training such models, however, requires a large, high quality dataset of objects. In applications such as computed imaging, it is often difficult to acquire such data due to requirements such as long acquisition time or high radiation dose, while acquiring noisy or partially observed measurements of these objects is more feasible. In this work, we propose AmbientFlow, a framework for learning flow-based generative models directly from noisy and incomplete data. Using variational Bayesian methods, a novel framework for establishing flow-based generative models from noisy, incomplete data is proposed. Extensive numerical studies demonstrate the effectiveness of AmbientFlow in correctly learning the object distribution. The utility of AmbientFlow in a downstream inference task of image reconstruction is demonstrated.
SSL4EO-L: Datasets and Foundation Models for Landsat Imagery
Jun 15, 2023



The Landsat program is the longest-running Earth observation program in history, with 50+ years of data acquisition by 8 satellites. The multispectral imagery captured by sensors onboard these satellites is critical for a wide range of scientific fields. Despite the increasing popularity of deep learning and remote sensing, the majority of researchers still use decision trees and random forests for Landsat image analysis due to the prevalence of small labeled datasets and lack of foundation models. In this paper, we introduce SSL4EO-L, the first ever dataset designed for Self-Supervised Learning for Earth Observation for the Landsat family of satellites (including 3 sensors and 2 product levels) and the largest Landsat dataset in history (5M image patches). Additionally, we modernize and re-release the L7 Irish and L8 Biome cloud detection datasets, and introduce the first ML benchmark datasets for Landsats 4-5 TM and Landsat 7 ETM+ SR. Finally, we pre-train the first foundation models for Landsat imagery using SSL4EO-L and evaluate their performance on multiple semantic segmentation tasks. All datasets and model weights are available via the TorchGeo (https://github.com/microsoft/torchgeo) library, making reproducibility and experimentation easy, and enabling scientific advancements in the burgeoning field of remote sensing for a myriad of downstream applications.
Neural Exploitation and Exploration of Contextual Bandits
May 05, 2023



In this paper, we study utilizing neural networks for the exploitation and exploration of contextual multi-armed bandits. Contextual multi-armed bandits have been studied for decades with various applications. To solve the exploitation-exploration trade-off in bandits, there are three main techniques: epsilon-greedy, Thompson Sampling (TS), and Upper Confidence Bound (UCB). In recent literature, a series of neural bandit algorithms have been proposed to adapt to the non-linear reward function, combined with TS or UCB strategies for exploration. In this paper, instead of calculating a large-deviation based statistical bound for exploration like previous methods, we propose, ``EE-Net,'' a novel neural-based exploitation and exploration strategy. In addition to using a neural network (Exploitation network) to learn the reward function, EE-Net uses another neural network (Exploration network) to adaptively learn the potential gains compared to the currently estimated reward for exploration. We provide an instance-based $\widetilde{\mathcal{O}}(\sqrt{T})$ regret upper bound for EE-Net and show that EE-Net outperforms related linear and neural contextual bandit baselines on real-world datasets.
Alternate Loss Functions Can Improve the Performance of Artificial Neural Networks
Mar 17, 2023All machine learning algorithms use a loss, cost, utility or reward function to encode the learning objective and oversee the learning process. This function that supervises learning is a frequently unrecognized hyperparameter that determines how incorrect outputs are penalized and can be tuned to improve performance. This paper shows that training speed and final accuracy of neural networks can significantly depend on the loss function used to train neural networks. In particular derivative values can be significantly different with different loss functions leading to significantly different performance after gradient descent based Backpropagation (BP) training. This paper explores the effect on performance of new loss functions that are more liberal or strict compared to the popular Cross-entropy loss in penalizing incorrect outputs. Eight new loss functions are proposed and a comparison of performance with different loss functions is presented. The new loss functions presented in this paper are shown to outperform Cross-entropy loss on computer vision and NLP benchmarks.
Improved Algorithms for Neural Active Learning
Oct 02, 2022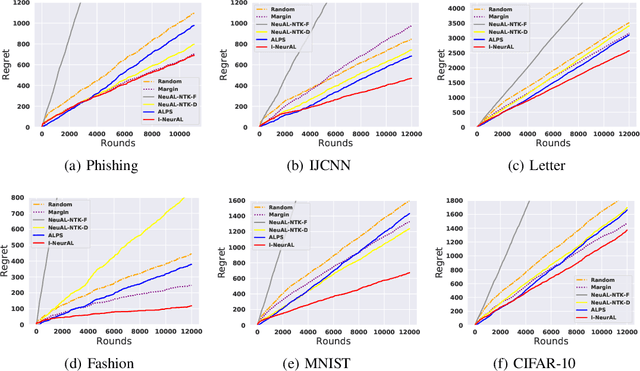

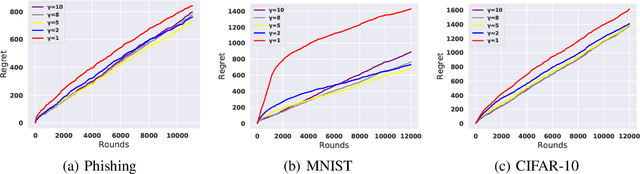
We improve the theoretical and empirical performance of neural-network(NN)-based active learning algorithms for the non-parametric streaming setting. In particular, we introduce two regret metrics by minimizing the population loss that are more suitable in active learning than the one used in state-of-the-art (SOTA) related work. Then, the proposed algorithm leverages the powerful representation of NNs for both exploitation and exploration, has the query decision-maker tailored for $k$-class classification problems with the performance guarantee, utilizes the full feedback, and updates parameters in a more practical and efficient manner. These careful designs lead to a better regret upper bound, improving by a multiplicative factor $O(\log T)$ and removing the curse of both input dimensionality and the complexity of the function to be learned. Furthermore, we show that the algorithm can achieve the same performance as the Bayes-optimal classifier in the long run under the hard-margin setting in classification problems. In the end, we use extensive experiments to evaluate the proposed algorithm and SOTA baselines, to show the improved empirical performance.
Restricted Strong Convexity of Deep Learning Models with Smooth Activations
Sep 29, 2022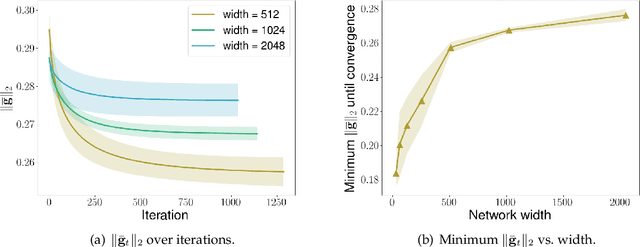
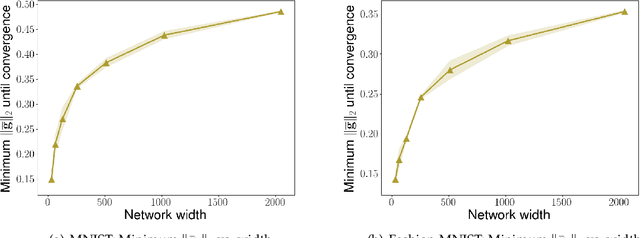
We consider the problem of optimization of deep learning models with smooth activation functions. While there exist influential results on the problem from the ``near initialization'' perspective, we shed considerable new light on the problem. In particular, we make two key technical contributions for such models with $L$ layers, $m$ width, and $\sigma_0^2$ initialization variance. First, for suitable $\sigma_0^2$, we establish a $O(\frac{\text{poly}(L)}{\sqrt{m}})$ upper bound on the spectral norm of the Hessian of such models, considerably sharpening prior results. Second, we introduce a new analysis of optimization based on Restricted Strong Convexity (RSC) which holds as long as the squared norm of the average gradient of predictors is $\Omega(\frac{\text{poly}(L)}{\sqrt{m}})$ for the square loss. We also present results for more general losses. The RSC based analysis does not need the ``near initialization" perspective and guarantees geometric convergence for gradient descent (GD). To the best of our knowledge, ours is the first result on establishing geometric convergence of GD based on RSC for deep learning models, thus becoming an alternative sufficient condition for convergence that does not depend on the widely-used Neural Tangent Kernel (NTK). We share preliminary experimental results supporting our theoretical advances.
Stability Based Generalization Bounds for Exponential Family Langevin Dynamics
Jan 09, 2022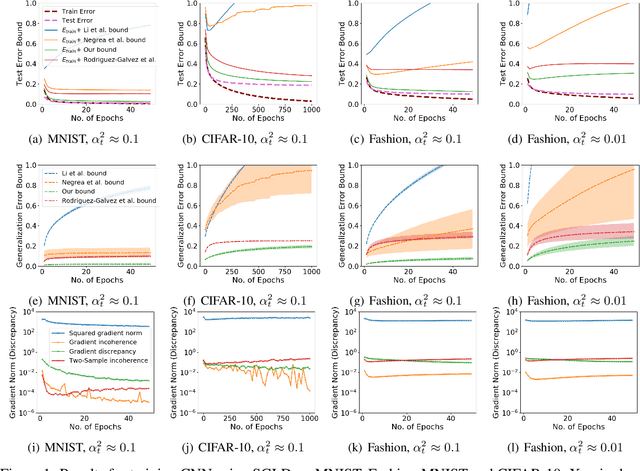
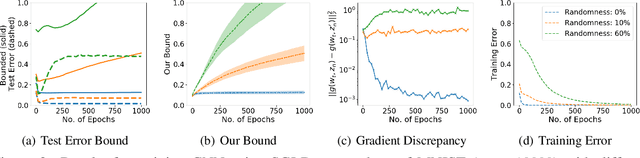
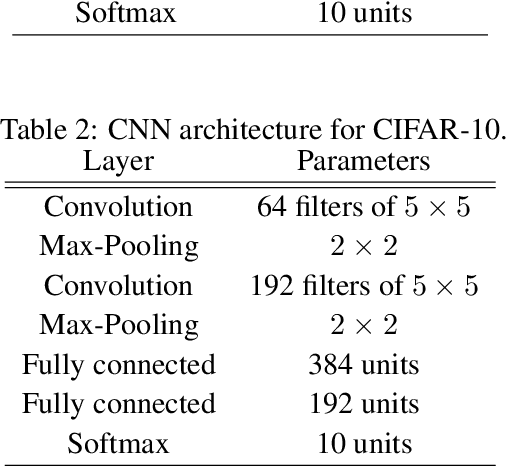
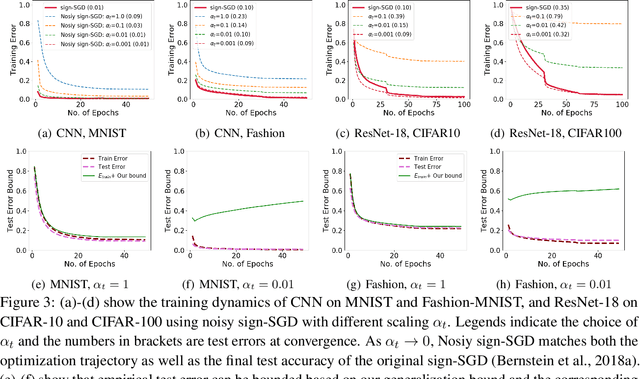
We study generalization bounds for noisy stochastic mini-batch iterative algorithms based on the notion of stability. Recent years have seen key advances in data-dependent generalization bounds for noisy iterative learning algorithms such as stochastic gradient Langevin dynamics (SGLD) based on stability (Mou et al., 2018; Li et al., 2020) and information theoretic approaches (Xu and Raginsky, 2017; Negrea et al., 2019; Steinke and Zakynthinou, 2020; Haghifam et al., 2020). In this paper, we unify and substantially generalize stability based generalization bounds and make three technical advances. First, we bound the generalization error of general noisy stochastic iterative algorithms (not necessarily gradient descent) in terms of expected (not uniform) stability. The expected stability can in turn be bounded by a Le Cam Style Divergence. Such bounds have a O(1/n) sample dependence unlike many existing bounds with O(1/\sqrt{n}) dependence. Second, we introduce Exponential Family Langevin Dynamics(EFLD) which is a substantial generalization of SGLD and which allows exponential family noise to be used with stochastic gradient descent (SGD). We establish data-dependent expected stability based generalization bounds for general EFLD algorithms. Third, we consider an important special case of EFLD: noisy sign-SGD, which extends sign-SGD using Bernoulli noise over {-1,+1}. Generalization bounds for noisy sign-SGD are implied by that of EFLD and we also establish optimization guarantees for the algorithm. Further, we present empirical results on benchmark datasets to illustrate that our bounds are non-vacuous and quantitatively much sharper than existing bounds.
TorchGeo: deep learning with geospatial data
Nov 17, 2021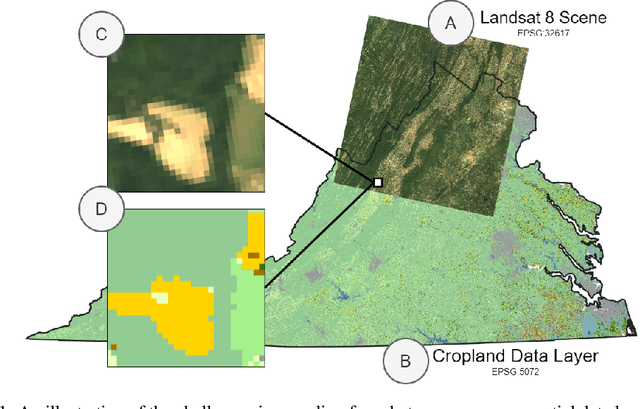
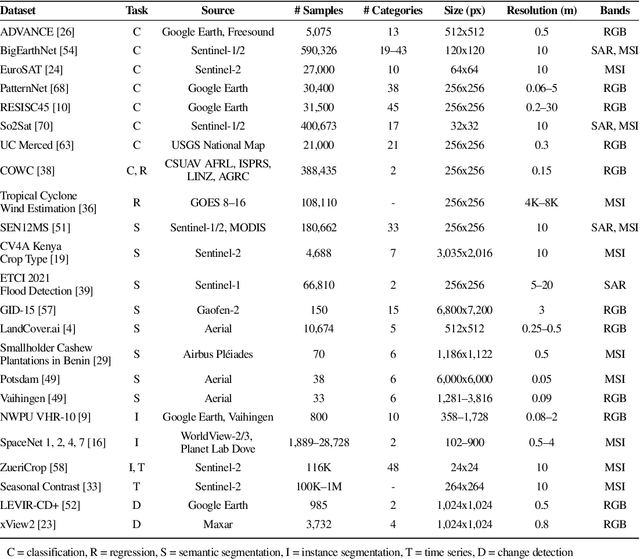
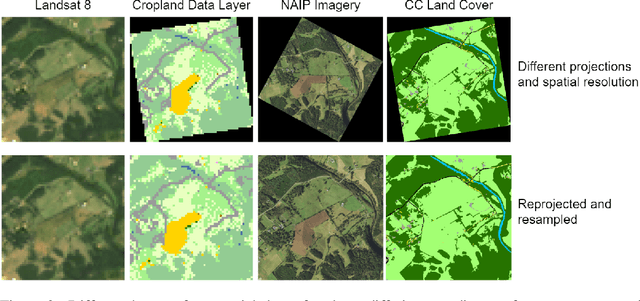
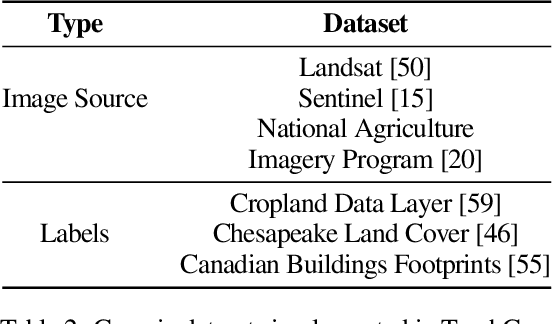
Remotely sensed geospatial data are critical for applications including precision agriculture, urban planning, disaster monitoring and response, and climate change research, among others. Deep learning methods are particularly promising for modeling many remote sensing tasks given the success of deep neural networks in similar computer vision tasks and the sheer volume of remotely sensed imagery available. However, the variance in data collection methods and handling of geospatial metadata make the application of deep learning methodology to remotely sensed data nontrivial. For example, satellite imagery often includes additional spectral bands beyond red, green, and blue and must be joined to other geospatial data sources that can have differing coordinate systems, bounds, and resolutions. To help realize the potential of deep learning for remote sensing applications, we introduce TorchGeo, a Python library for integrating geospatial data into the PyTorch deep learning ecosystem. TorchGeo provides data loaders for a variety of benchmark datasets, composable datasets for generic geospatial data sources, samplers for geospatial data, and transforms that work with multispectral imagery. TorchGeo is also the first library to provide pre-trained models for multispectral satellite imagery (e.g. models that use all bands from the Sentinel 2 satellites), allowing for advances in transfer learning on downstream remote sensing tasks with limited labeled data. We use TorchGeo to create reproducible benchmark results on existing datasets and benchmark our proposed method for preprocessing geospatial imagery on-the-fly. TorchGeo is open-source and available on GitHub: https://github.com/microsoft/torchgeo.
EE-Net: Exploitation-Exploration Neural Networks in Contextual Bandits
Oct 07, 2021
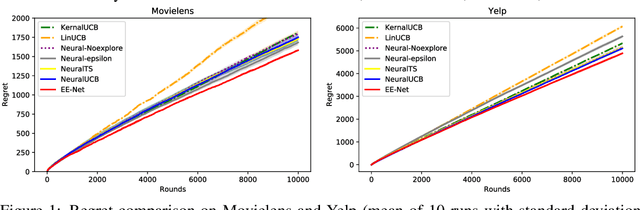

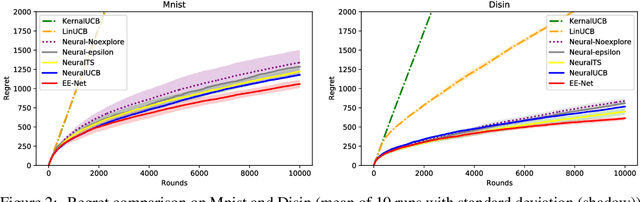
Contextual multi-armed bandits have been studied for decades and adapted to various applications such as online advertising and personalized recommendation. To solve the exploitation-exploration tradeoff in bandits, there are three main techniques: epsilon-greedy, Thompson Sampling (TS), and Upper Confidence Bound (UCB). In recent literature, linear contextual bandits have adopted ridge regression to estimate the reward function and combine it with TS or UCB strategies for exploration. However, this line of works explicitly assumes the reward is based on a linear function of arm vectors, which may not be true in real-world datasets. To overcome this challenge, a series of neural-based bandit algorithms have been proposed, where a neural network is assigned to learn the underlying reward function and TS or UCB are adapted for exploration. In this paper, we propose "EE-Net", a neural-based bandit approach with a novel exploration strategy. In addition to utilizing a neural network (Exploitation network) to learn the reward function, EE-Net adopts another neural network (Exploration network) to adaptively learn potential gains compared to currently estimated reward. Then, a decision-maker is constructed to combine the outputs from the Exploitation and Exploration networks. We prove that EE-Net achieves $\mathcal{O}(\sqrt{T\log T})$ regret, which is tighter than existing state-of-the-art neural bandit algorithms ($\mathcal{O}(\sqrt{T}\log T)$ for both UCB-based and TS-based). Through extensive experiments on four real-world datasets, we show that EE-Net outperforms existing linear and neural bandit approaches.