 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAverage Gradient Outer Product in kernel regression provably recovers the central subspace for multi-index models
May 14, 2026We study a prototypical situation when a learned predictor can discover useful low-dimensional structure in data, while using fewer samples than are needed for accurate prediction. Specifically, we consider the problem of recovering a multi-index polynomial $f^*(x)=h(Ux)$, with $U\in\mathbb{R}^{r\times d}$ and $r\ll d$, from finitely many data/label pairs. Importantly, the target function depends on input $x$ only through the projection onto an unknown $r$-dimensional central subspace. The algorithm we analyze is appealingly simple: fit kernel ridge regression (KRR) to the data and compute the Average Gradient Outer Product (AGOP) from the fitted predictor. Our main results show that under reasonable assumptions the top $r$-dimensional eigenspace of AGOP provably recovers the central subspace, even in regimes when the prediction error remains large. Specifically, if the target function $f^*$ has degree $p^*$, it is known that $n\asymp d^{p^*}$ samples are necessary for KRR to achieve accurate prediction. In contrast, we show that if a low degree $p$ component of $f^*$ already carries all relevant directions for prediction, subspace recovery occurs in the much lower sample regime $n\asymp d^{p+δ}$ for any $δ\in(0,1)$. Our results thus demonstrate a separation between prediction and representation, and provide an explanation for why iterative kernel methods such as Recursive Feature Machines (RFM) can be sample-efficient in practice.
Iteratively reweighted kernel machines efficiently learn sparse functions
May 13, 2025The impressive practical performance of neural networks is often attributed to their ability to learn low-dimensional data representations and hierarchical structure directly from data. In this work, we argue that these two phenomena are not unique to neural networks, and can be elicited from classical kernel methods. Namely, we show that the derivative of the kernel predictor can detect the influential coordinates with low sample complexity. Moreover, by iteratively using the derivatives to reweight the data and retrain kernel machines, one is able to efficiently learn hierarchical polynomials with finite leap complexity. Numerical experiments illustrate the developed theory.
Emergence in non-neural models: grokking modular arithmetic via average gradient outer product
Jul 29, 2024Neural networks trained to solve modular arithmetic tasks exhibit grokking, a phenomenon where the test accuracy starts improving long after the model achieves 100% training accuracy in the training process. It is often taken as an example of "emergence", where model ability manifests sharply through a phase transition. In this work, we show that the phenomenon of grokking is not specific to neural networks nor to gradient descent-based optimization. Specifically, we show that this phenomenon occurs when learning modular arithmetic with Recursive Feature Machines (RFM), an iterative algorithm that uses the Average Gradient Outer Product (AGOP) to enable task-specific feature learning with general machine learning models. When used in conjunction with kernel machines, iterating RFM results in a fast transition from random, near zero, test accuracy to perfect test accuracy. This transition cannot be predicted from the training loss, which is identically zero, nor from the test loss, which remains constant in initial iterations. Instead, as we show, the transition is completely determined by feature learning: RFM gradually learns block-circulant features to solve modular arithmetic. Paralleling the results for RFM, we show that neural networks that solve modular arithmetic also learn block-circulant features. Furthermore, we present theoretical evidence that RFM uses such block-circulant features to implement the Fourier Multiplication Algorithm, which prior work posited as the generalizing solution neural networks learn on these tasks. Our results demonstrate that emergence can result purely from learning task-relevant features and is not specific to neural architectures nor gradient descent-based optimization methods. Furthermore, our work provides more evidence for AGOP as a key mechanism for feature learning in neural networks.
Catapults in SGD: spikes in the training loss and their impact on generalization through feature learning
Jun 07, 2023



In this paper, we first present an explanation regarding the common occurrence of spikes in the training loss when neural networks are trained with stochastic gradient descent (SGD). We provide evidence that the spikes in the training loss of SGD are "catapults", an optimization phenomenon originally observed in GD with large learning rates in [Lewkowycz et al. 2020]. We empirically show that these catapults occur in a low-dimensional subspace spanned by the top eigenvectors of the tangent kernel, for both GD and SGD. Second, we posit an explanation for how catapults lead to better generalization by demonstrating that catapults promote feature learning by increasing alignment with the Average Gradient Outer Product (AGOP) of the true predictor. Furthermore, we demonstrate that a smaller batch size in SGD induces a larger number of catapults, thereby improving AGOP alignment and test performance.
Restricted Strong Convexity of Deep Learning Models with Smooth Activations
Sep 29, 2022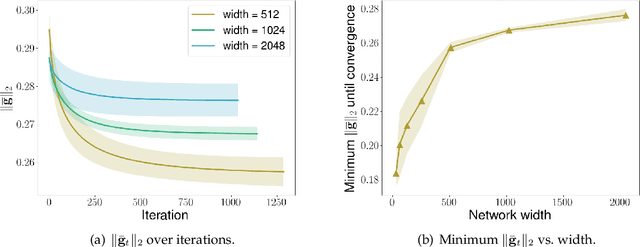
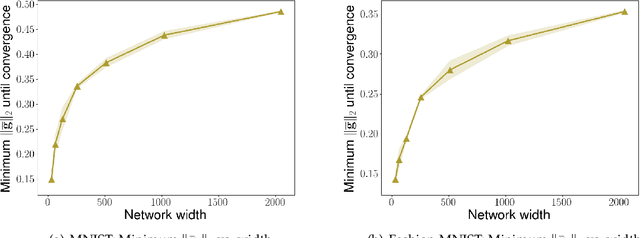
We consider the problem of optimization of deep learning models with smooth activation functions. While there exist influential results on the problem from the ``near initialization'' perspective, we shed considerable new light on the problem. In particular, we make two key technical contributions for such models with $L$ layers, $m$ width, and $\sigma_0^2$ initialization variance. First, for suitable $\sigma_0^2$, we establish a $O(\frac{\text{poly}(L)}{\sqrt{m}})$ upper bound on the spectral norm of the Hessian of such models, considerably sharpening prior results. Second, we introduce a new analysis of optimization based on Restricted Strong Convexity (RSC) which holds as long as the squared norm of the average gradient of predictors is $\Omega(\frac{\text{poly}(L)}{\sqrt{m}})$ for the square loss. We also present results for more general losses. The RSC based analysis does not need the ``near initialization" perspective and guarantees geometric convergence for gradient descent (GD). To the best of our knowledge, ours is the first result on establishing geometric convergence of GD based on RSC for deep learning models, thus becoming an alternative sufficient condition for convergence that does not depend on the widely-used Neural Tangent Kernel (NTK). We share preliminary experimental results supporting our theoretical advances.
A note on Linear Bottleneck networks and their Transition to Multilinearity
Jun 30, 2022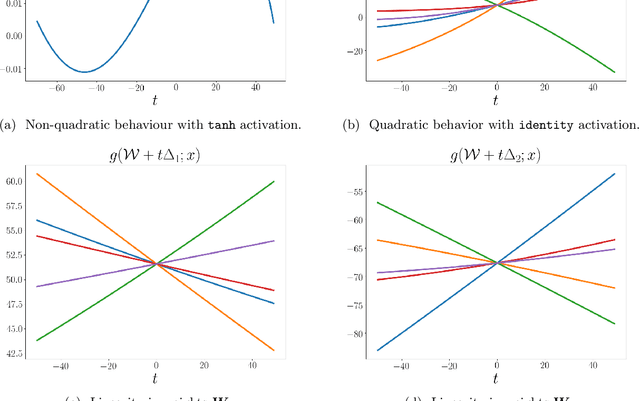
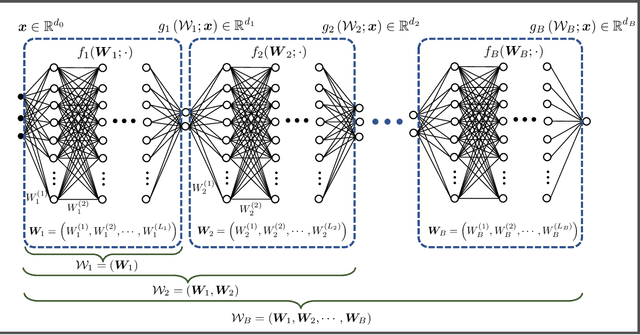
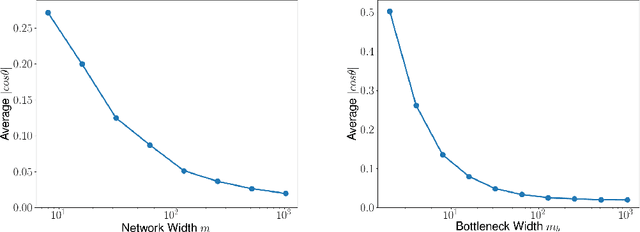
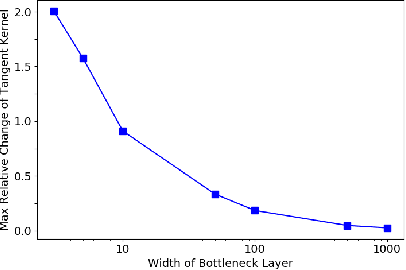
Randomly initialized wide neural networks transition to linear functions of weights as the width grows, in a ball of radius $O(1)$ around initialization. A necessary condition for this result is that all layers of the network are wide enough, i.e., all widths tend to infinity. However, the transition to linearity breaks down when this infinite width assumption is violated. In this work we show that linear networks with a bottleneck layer learn bilinear functions of the weights, in a ball of radius $O(1)$ around initialization. In general, for $B-1$ bottleneck layers, the network is a degree $B$ multilinear function of weights. Importantly, the degree only depends on the number of bottlenecks and not the total depth of the network.
Quadratic models for understanding neural network dynamics
May 24, 2022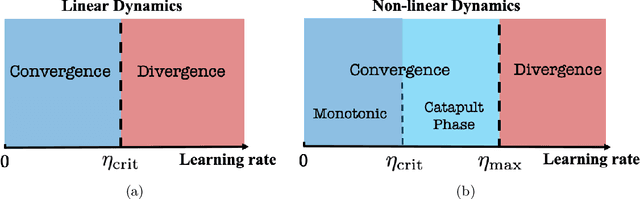
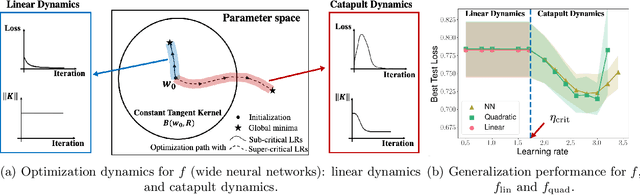
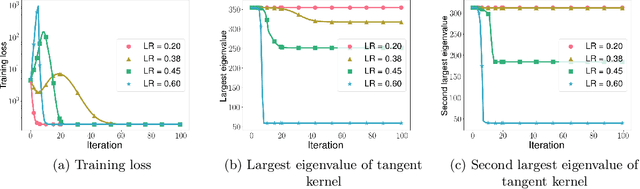
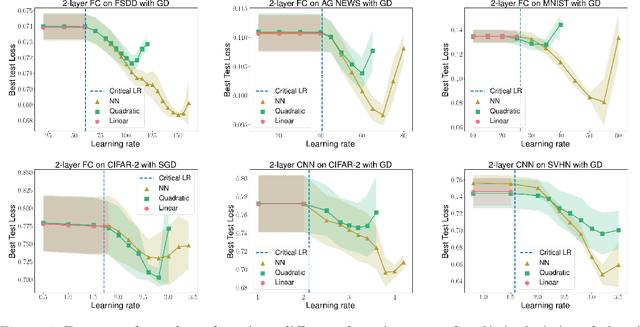
In this work, we propose using a quadratic model as a tool for understanding properties of wide neural networks in both optimization and generalization. We show analytically that certain deep learning phenomena such as the "catapult phase" from [Lewkowycz et al. 2020], which cannot be captured by linear models, are manifested in the quadratic model for shallow ReLU networks. Furthermore, our empirical results indicate that the behaviour of quadratic models parallels that of neural networks in generalization, especially in the large learning rate regime. We expect that quadratic models will serve as a useful tool for analysis of neural networks.
Transition to Linearity of General Neural Networks with Directed Acyclic Graph Architecture
May 24, 2022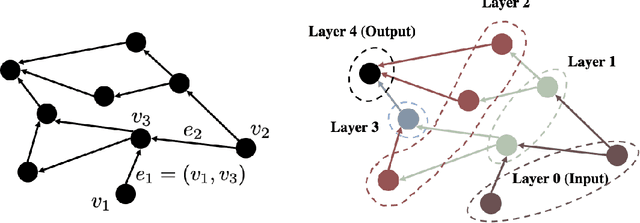
In this paper we show that feedforward neural networks corresponding to arbitrary directed acyclic graphs undergo transition to linearity as their "width" approaches infinity. The width of these general networks is characterized by the minimum in-degree of their neurons, except for the input and first layers. Our results identify the mathematical structure underlying transition to linearity and generalize a number of recent works aimed at characterizing transition to linearity or constancy of the Neural Tangent Kernel for standard architectures.
Transition to Linearity of Wide Neural Networks is an Emerging Property of Assembling Weak Models
Mar 10, 2022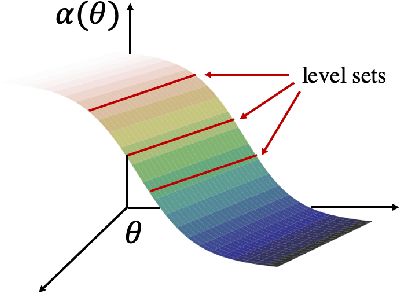
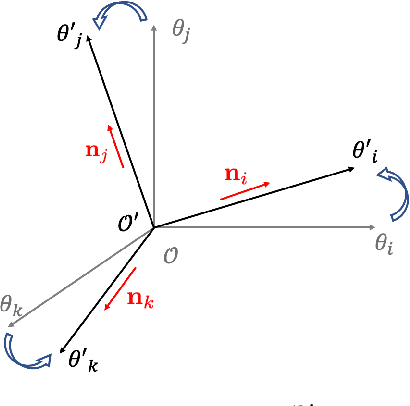
Wide neural networks with linear output layer have been shown to be near-linear, and to have near-constant neural tangent kernel (NTK), in a region containing the optimization path of gradient descent. These findings seem counter-intuitive since in general neural networks are highly complex models. Why does a linear structure emerge when the networks become wide? In this work, we provide a new perspective on this "transition to linearity" by considering a neural network as an assembly model recursively built from a set of sub-models corresponding to individual neurons. In this view, we show that the linearity of wide neural networks is, in fact, an emerging property of assembling a large number of diverse "weak" sub-models, none of which dominate the assembly.
On the linearity of large non-linear models: when and why the tangent kernel is constant
Oct 02, 2020
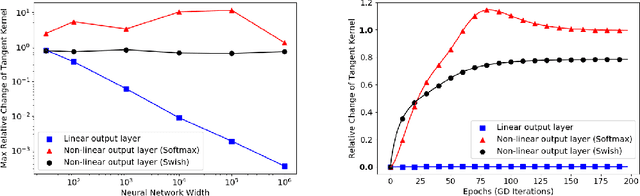
The goal of this work is to shed light on the remarkable phenomenon of transition to linearity of certain neural networks as their width approaches infinity. We show that the transition to linearity of the model and, equivalently, constancy of the (neural) tangent kernel (NTK) result from the scaling properties of the norm of the Hessian matrix of the network as a function of the network width. We present a general framework for understanding the constancy of the tangent kernel via Hessian scaling applicable to the standard classes of neural networks. Our analysis provides a new perspective on the phenomenon of constant tangent kernel, which is different from the widely accepted "lazy training". Furthermore, we show that the transition to linearity is not a general property of wide neural networks and does not hold when the last layer of the network is non-linear. It is also not necessary for successful optimization by gradient descent.