 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacking Models for Nearly Optimal Link Prediction in Complex Networks
Sep 17, 2019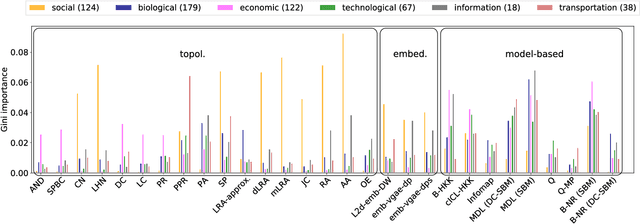
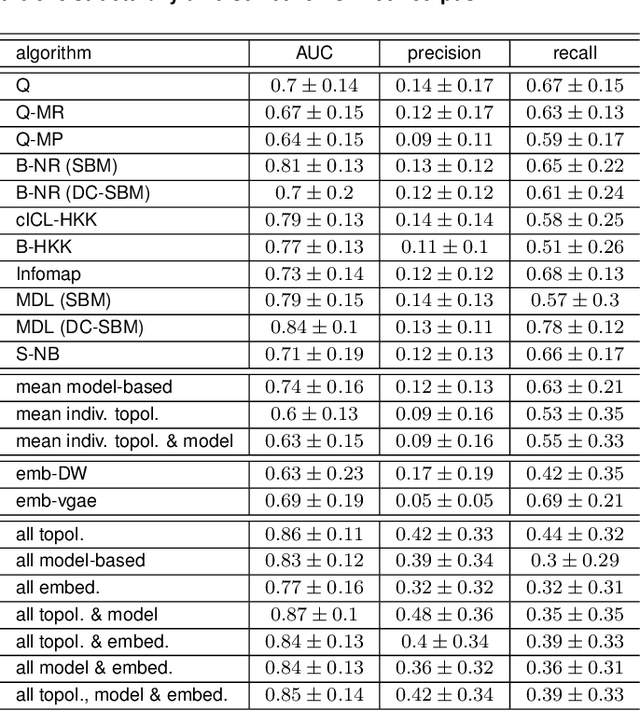
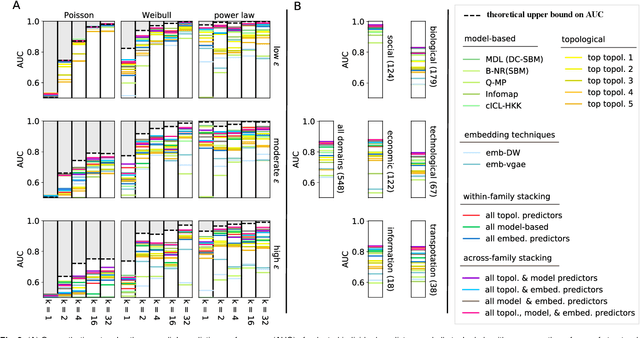
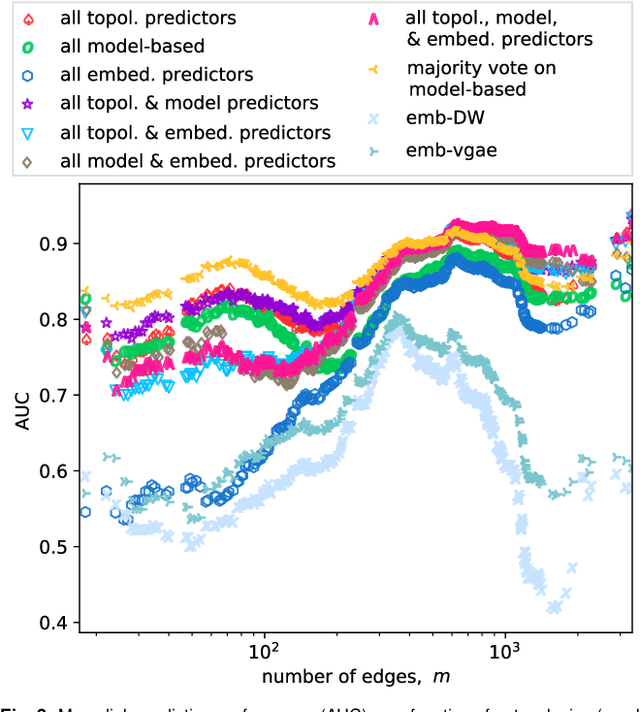
Most real-world networks are incompletely observed. Algorithms that can accurately predict which links are missing can dramatically speedup the collection of network data and improve the validity of network models. Many algorithms now exist for predicting missing links, given a partially observed network, but it has remained unknown whether a single best predictor exists, how link predictability varies across methods and networks from different domains, and how close to optimality current methods are. We answer these questions by systematically evaluating 203 individual link predictor algorithms, representing three popular families of methods, applied to a large corpus of 548 structurally diverse networks from six scientific domains. We first show that individual algorithms exhibit a broad diversity of prediction errors, such that no one predictor or family is best, or worst, across all realistic inputs. We then exploit this diversity via meta-learning to construct a series of "stacked" models that combine predictors into a single algorithm. Applied to a broad range of synthetic networks, for which we may analytically calculate optimal performance, these stacked models achieve optimal or nearly optimal levels of accuracy. Applied to real-world networks, stacked models are also superior, but their accuracy varies strongly by domain, suggesting that link prediction may be fundamentally easier in social networks than in biological or technological networks. These results indicate that the state-of-the-art for link prediction comes from combining individual algorithms, which achieves nearly optimal predictions. We close with a brief discussion of limitations and opportunities for further improvement of these results.
Nearly-Unsupervised Hashcode Representations for Relation Extraction
Sep 09, 2019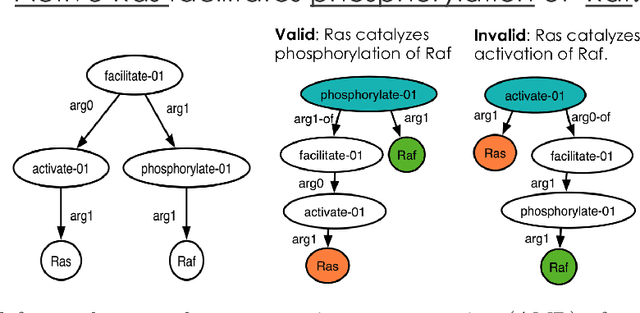
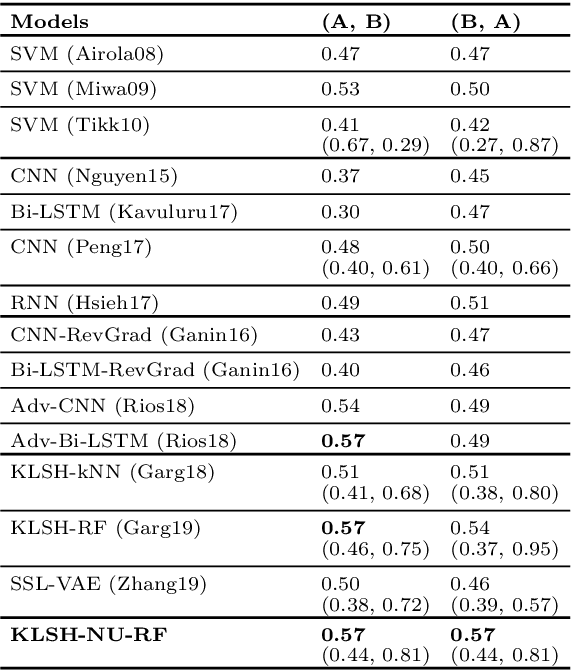
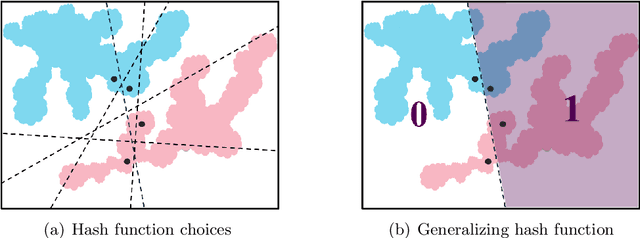
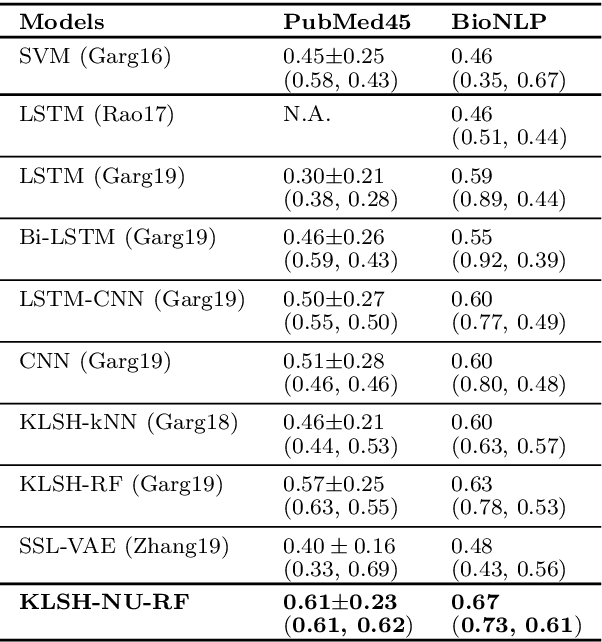
Recently, kernelized locality sensitive hashcodes have been successfully employed as representations of natural language text, especially showing high relevance to biomedical relation extraction tasks. In this paper, we propose to optimize the hashcode representations in a nearly unsupervised manner, in which we only use data points, but not their class labels, for learning. The optimized hashcode representations are then fed to a supervised classifier following the prior work. This nearly unsupervised approach allows fine-grained optimization of each hash function, which is particularly suitable for building hashcode representations generalizing from a training set to a test set. We empirically evaluate the proposed approach for biomedical relation extraction tasks, obtaining significant accuracy improvements w.r.t. state-of-the-art supervised and semi-supervised approaches.
Efficient Covariance Estimation from Temporal Data
May 30, 2019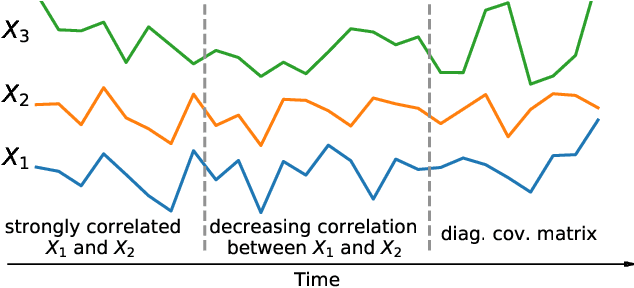
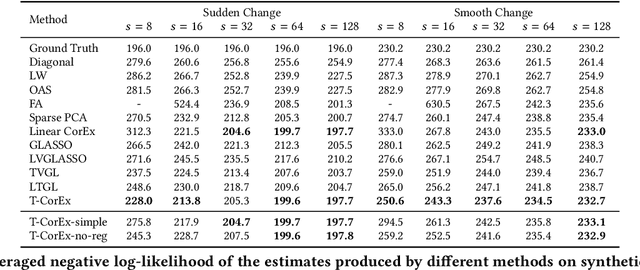
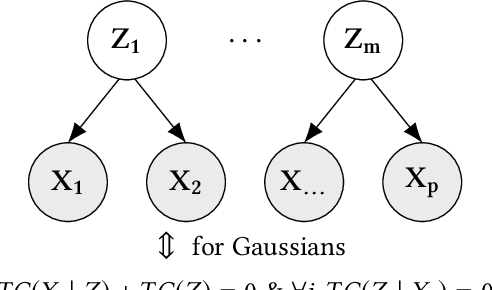
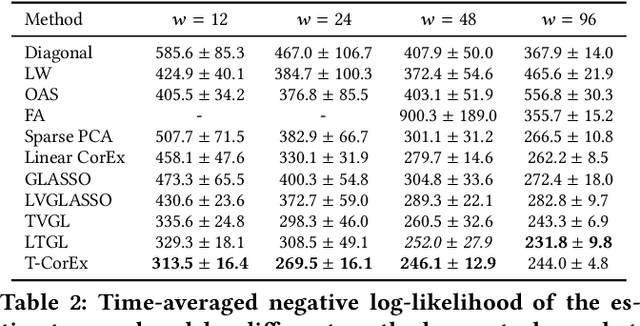
Estimating the covariance structure of multivariate time series is a fundamental problem with a wide-range of real-world applications -- from financial modeling to fMRI analysis. Despite significant recent advances, current state-of-the-art methods are still severely limited in terms of scalability, and do not work well in high-dimensional undersampled regimes. In this work we propose a novel method called Temporal Correlation Explanation, or T-CorEx, that (a) has linear time and memory complexity with respect to the number of variables, and can scale to very large temporal datasets that are not tractable with existing methods; (b) gives state-of-the-art results in highly undersampled regimes on both synthetic and real-world datasets; and (c) makes minimal assumptions about the character of the dynamics of the system. T-CorEx optimizes an information-theoretic objective function to learn a latent factor graphical model for each time period and applies two regularization techniques to induce temporal consistency of estimates. We perform extensive evaluation of T-Corex using both synthetic and real-world data and demonstrate that it can be used for detecting sudden changes in the underlying covariance matrix, capturing transient correlations and analyzing extremely high-dimensional complex multivariate time series such as high-resolution fMRI data.
MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing
May 28, 2019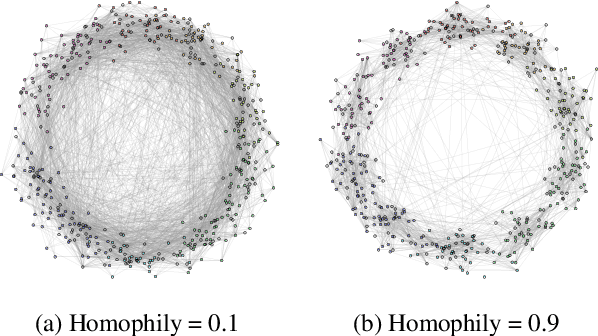
Existing popular methods for semi-supervised learning with Graph Neural Networks (such as the Graph Convolutional Network) provably cannot learn a general class of neighborhood mixing relationships. To address this weakness, we propose a new model, MixHop, that can learn these relationships, including difference operators, by repeatedly mixing feature representations of neighbors at various distances. Mixhop requires no additional memory or computational complexity, and outperforms on challenging baselines. In addition, we propose sparsity regularization that allows us to visualize how the network prioritizes neighborhood information across different graph datasets. Our analysis of the learned architectures reveals that neighborhood mixing varies per datasets.
Better Automatic Evaluation of Open-Domain Dialogue Systems with Contextualized Embeddings
Apr 24, 2019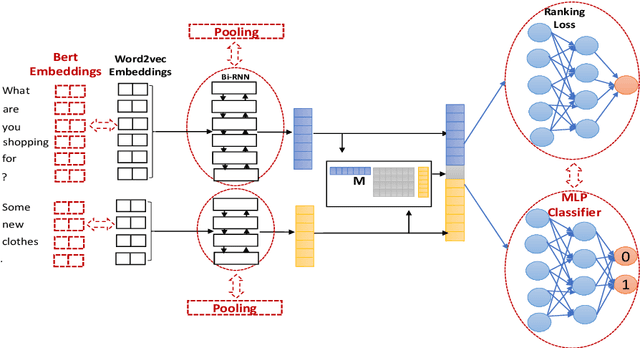
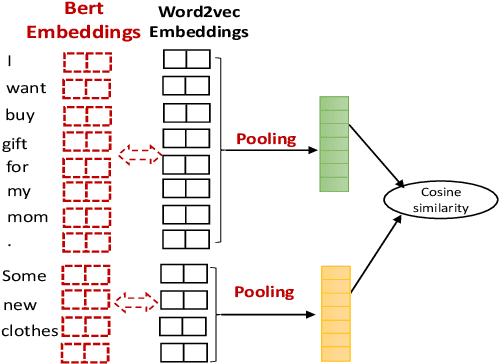

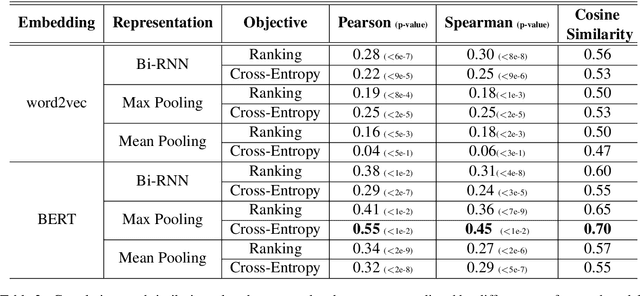
Despite advances in open-domain dialogue systems, automatic evaluation of such systems is still a challenging problem. Traditional reference-based metrics such as BLEU are ineffective because there could be many valid responses for a given context that share no common words with reference responses. A recent work proposed Referenced metric and Unreferenced metric Blended Evaluation Routine (RUBER) to combine a learning-based metric, which predicts relatedness between a generated response and a given query, with reference-based metric; it showed high correlation with human judgments. In this paper, we explore using contextualized word embeddings to compute more accurate relatedness scores, thus better evaluation metrics. Experiments show that our evaluation metrics outperform RUBER, which is trained on static embeddings.
Exact Rate-Distortion in Autoencoders via Echo Noise
Apr 15, 2019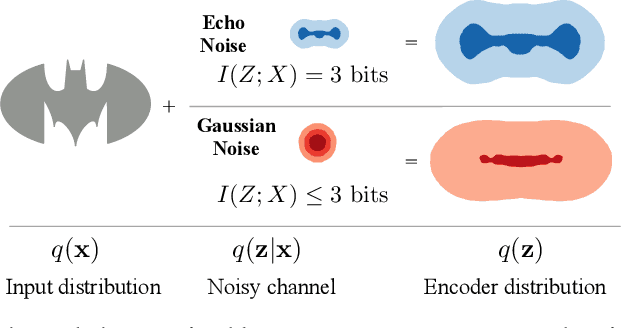
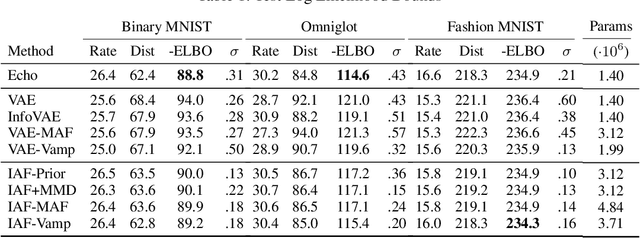
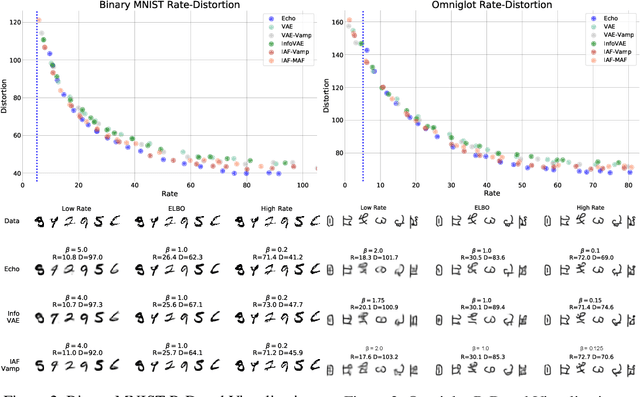

Compression is at the heart of effective representation learning. However, lossy compression is typically achieved through simple parametric models like Gaussian noise to preserve analytic tractability, and the limitations this imposes on learning are largely unexplored. Further, the Gaussian prior assumptions in models such as variational autoencoders (VAEs) provide only an upper bound on the compression rate in general. We introduce a new noise channel, Echo noise, that admits a simple, exact expression for mutual information for arbitrary input distributions. The noise is constructed in a data-driven fashion that does not require restrictive distributional assumptions. With its complex encoding mechanism and exact rate regularization, Echo leads to improved bounds on log-likelihood and dominates $\beta$-VAEs across the achievable range of rate-distortion trade-offs. Further, we show that Echo noise can outperform state-of-the-art flow methods without the need to train complex distributional transformations
Identifying and Analyzing Cryptocurrency Manipulations in Social Media
Feb 04, 2019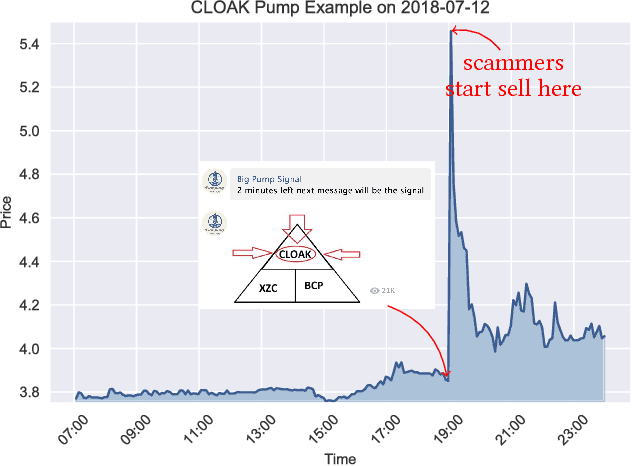
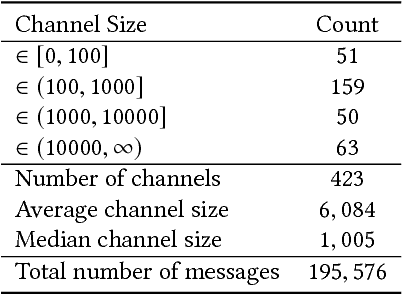
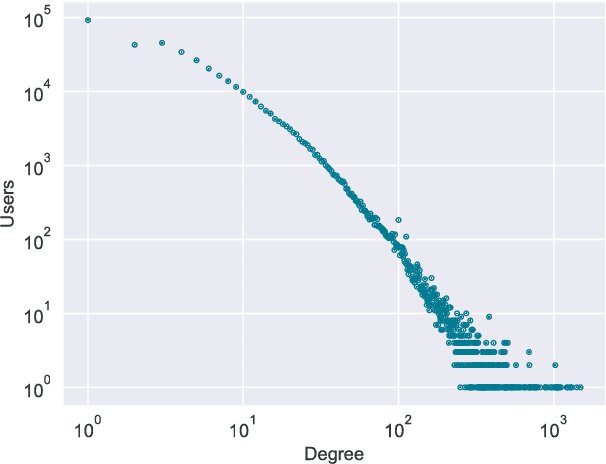
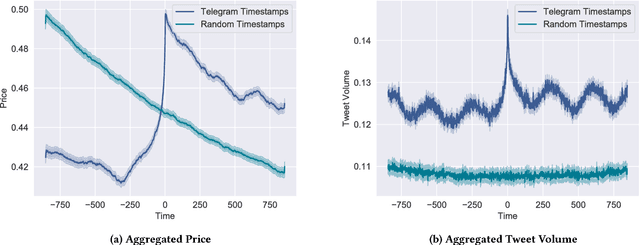
Interest surrounding cryptocurrencies, digital or virtual currencies that are used as a medium for financial transactions, has grown tremendously in recent years. The anonymity surrounding these currencies makes investors particularly susceptible to fraud---such as "pump and dump" scams---where the goal is to artificially inflate the perceived worth of a currency, luring victims into investing before the fraudsters can sell their holdings. Because of the speed and relative anonymity offered by social platforms such as Twitter and Telegram, social media has become a preferred platform for scammers who wish to spread false hype about the cryptocurrency they are trying to pump. In this work we propose and evaluate a computational approach that can automatically identify pump and dump scams as they unfold by combining information across social media platforms. We also develop a multi-modal approach for predicting whether a particular pump attempt will succeed or not. Finally, we analyze the prevalence of bots in cryptocurrency related tweets, and observe a significant increase in bot activity during the pump attempts.
Invariant Representations without Adversarial Training
Nov 04, 2018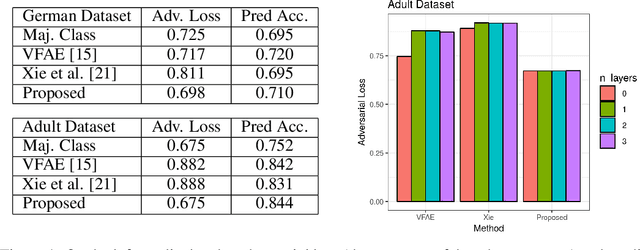
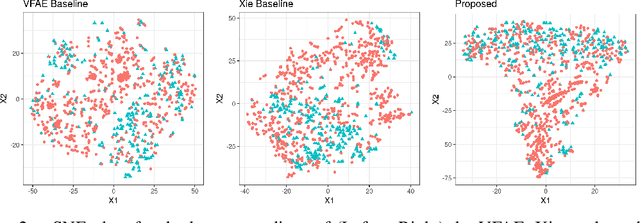
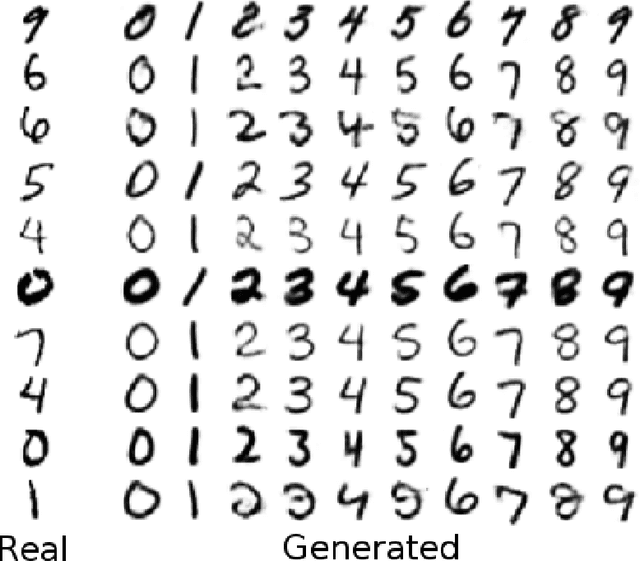
Representations of data that are invariant to changes in specified factors are useful for a wide range of problems: removing potential biases in prediction problems, controlling the effects of covariates, and disentangling meaningful factors of variation. Unfortunately, learning representations that exhibit invariance to arbitrary nuisance factors yet remain useful for other tasks is challenging. Existing approaches cast the trade-off between task performance and invariance in an adversarial way, using an iterative minimax optimization. We show that adversarial training is unnecessary and sometimes counter-productive; we instead cast invariant representation learning as a single information-theoretic objective that can be directly optimized. We demonstrate that this approach matches or exceeds performance of state-of-the-art adversarial approaches for learning fair representations and for generative modeling with controllable transformations.
Kernelized Hashcode Representations for Biomedical Relation Extraction
Oct 31, 2018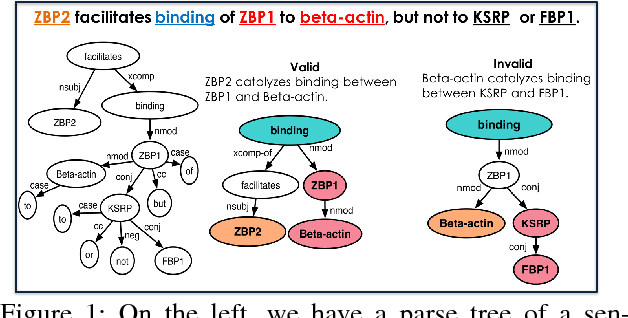
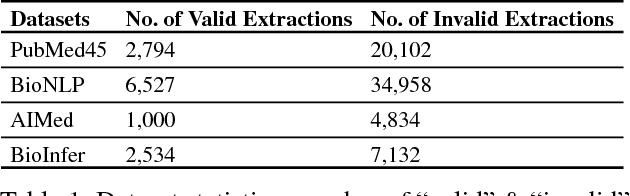
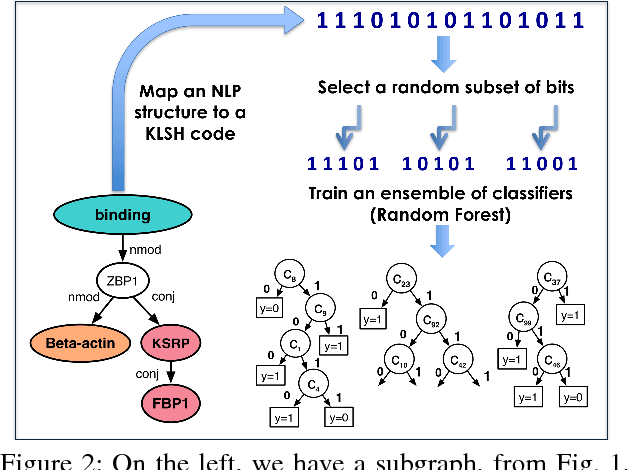
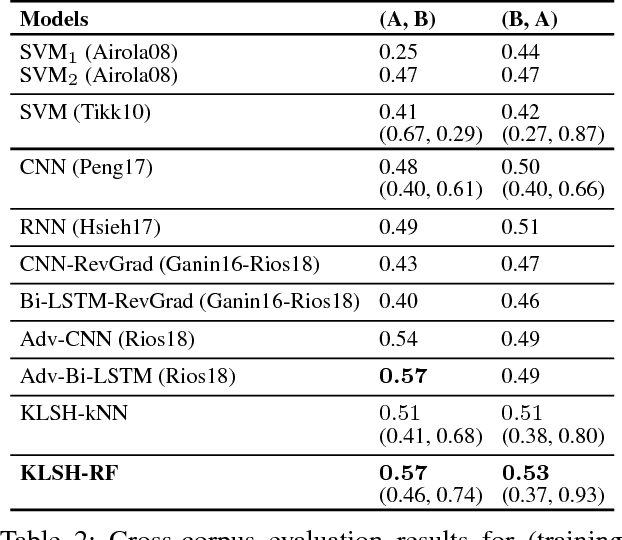
Kernel methods have produced state-of-the-art results for a number of NLP tasks such as relation extraction, but suffer from poor scalability due to the high cost of computing kernel similarities between discrete natural language structures. A recently proposed technique, kernelized locality-sensitive hashing (KLSH), can significantly reduce the computational cost, but is only applicable to classifiers operating on kNN graphs. Here we propose to use random subspaces of KLSH codes for efficiently constructing an explicit representation of NLP structures suitable for general classification methods. Further, we propose an approach for optimizing the KLSH model for classification problems by maximizing a variational lower bound on mutual information between the KLSH codes (feature vectors) and the class labels. We evaluate the proposed approach on biomedical relation extraction datasets, and observe significant and robust improvements in accuracy w.r.t. state-of-the-art classifiers, along with drastic (orders-of-magnitude) speedup compared to conventional kernel methods.
Dialogue Modeling Via Hash Functions
Oct 18, 2018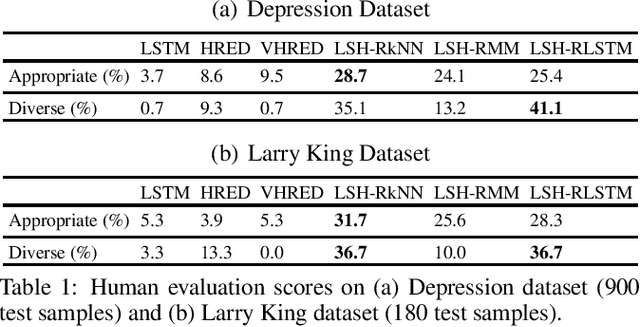
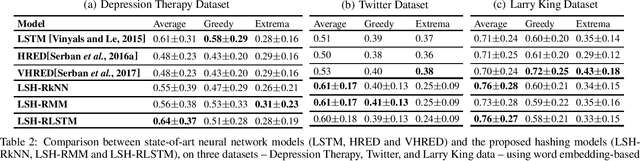
We propose a novel dialogue modeling framework which uses binary hashcodes as compressed text representations, allowing for efficient similarity search, and a novel lower bound on mutual information between the hashcodes of the two dialog agents, which serves as a model selection criterion for optimizing those representations towards better alignment between the dialog participants and higher predictability of one response from another, facilitating better dialog generation. Empirical evaluation on several datasets, from depression therapy sessions to Larry King TV show interviews and Twitter data, demonstrate that our hashing-based approach is competitive with state-of-art neural network based dialogue generation systems, often significantly outperforming them in terms of response quality and computational efficiency, especially on relatively small datasets.