 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Modeling Via Hash Functions
Paper and Code
Oct 18, 2018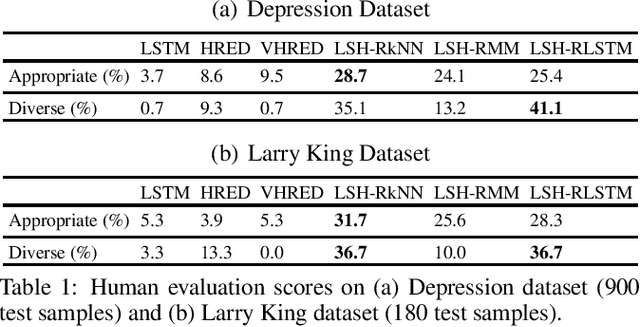
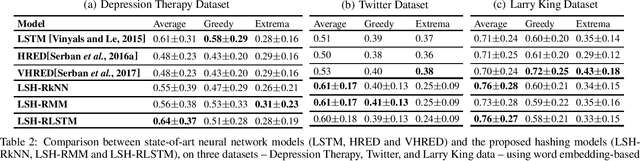
We propose a novel dialogue modeling framework which uses binary hashcodes as compressed text representations, allowing for efficient similarity search, and a novel lower bound on mutual information between the hashcodes of the two dialog agents, which serves as a model selection criterion for optimizing those representations towards better alignment between the dialog participants and higher predictability of one response from another, facilitating better dialog generation. Empirical evaluation on several datasets, from depression therapy sessions to Larry King TV show interviews and Twitter data, demonstrate that our hashing-based approach is competitive with state-of-art neural network based dialogue generation systems, often significantly outperforming them in terms of response quality and computational efficiency, especially on relatively small datasets.