 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent negotiation on the Web: State of the art
Apr 21, 2022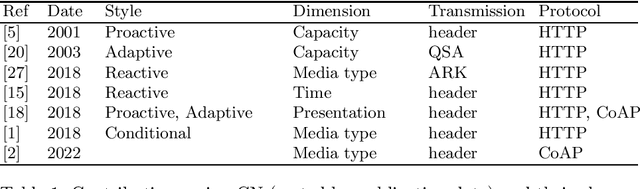
The openness and accessibility of the Web has contributed greatly to its worldwide adoption. Uniform Resource Identifiers (URIs) are used for resource identification on the Web. A resource on the Web can be described in many ways, which makes it difficult for a user to find an adequate representation. This situation has motivated fruitful research on content negotiation to satisfy user requirements efficiently and effectively. We focus on the important topic of content negotiation, and our goal is to present the first comprehensive state of the art. Our contributions include (1) identifying the characteristics of content negotiation scenarios (styles, dimensions, and means of conveying constraints), (2) comparing and classifying existing contributions, (3) identifying use cases that the current state of content negotiation struggles to address, (4) suggesting research directions for future work. The results of the state of the art show that the problem of content negotiation is relevant and far from being solved.
Knowledge Graphs
Mar 28, 2020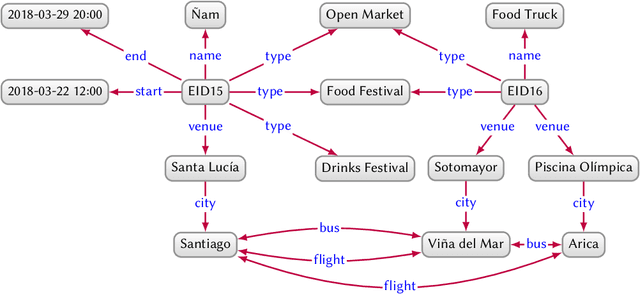
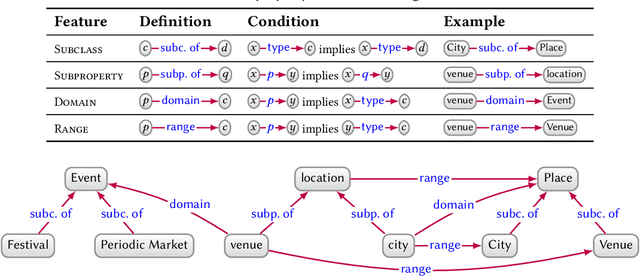
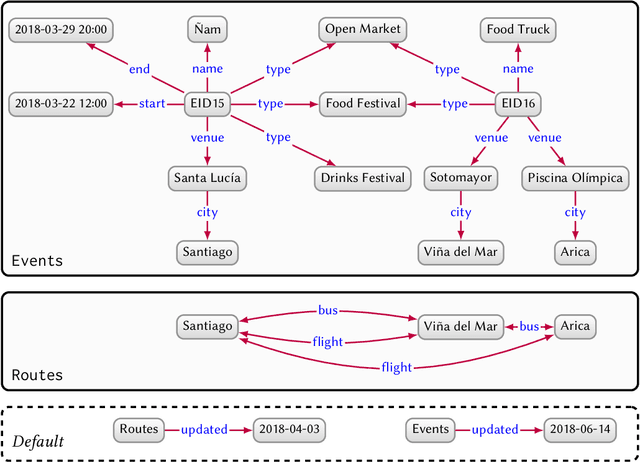
In this paper we provide a comprehensive introduction to knowledge graphs, which have recently garnered significant attention from both industry and academia in scenarios that require exploiting diverse, dynamic, large-scale collections of data. After a general introduction, we motivate and contrast various graph-based data models and query languages that are used for knowledge graphs. We discuss the roles of schema, identity, and context in knowledge graphs. We explain how knowledge can be represented and extracted using a combination of deductive and inductive techniques. We summarise methods for the creation, enrichment, quality assessment, refinement, and publication of knowledge graphs. We provide an overview of prominent open knowledge graphs and enterprise knowledge graphs, their applications, and how they use the aforementioned techniques. We conclude with high-level future research directions for knowledge graphs.
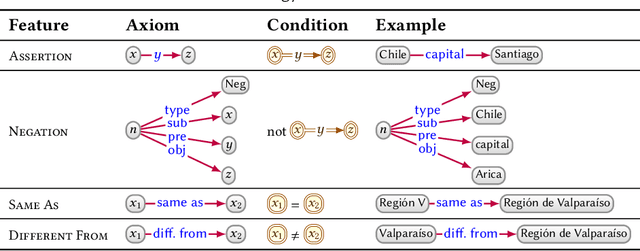
NdFluents: A Multi-dimensional Contexts Ontology
Sep 22, 2016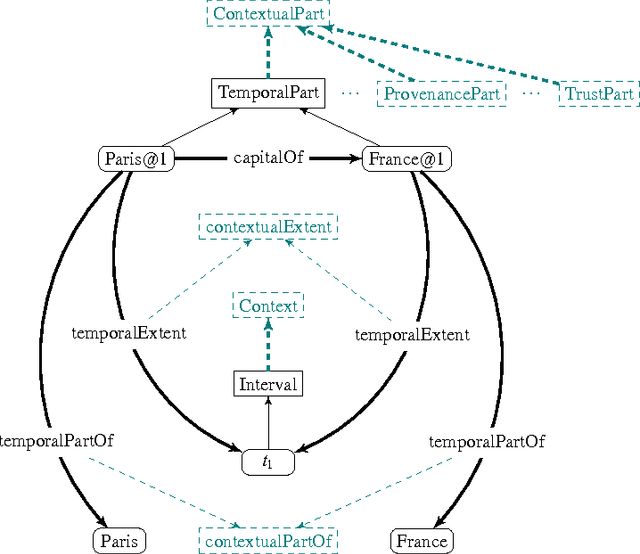

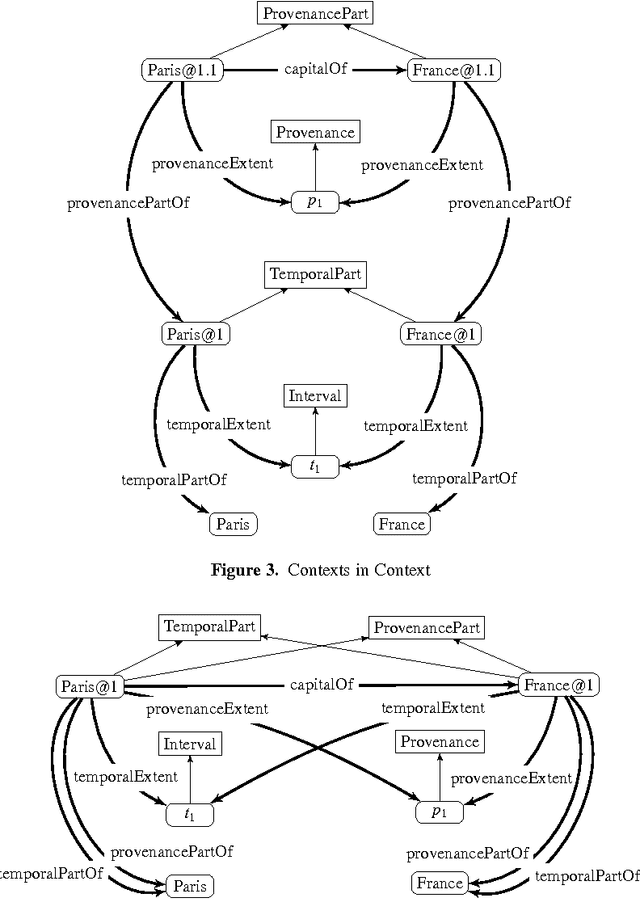
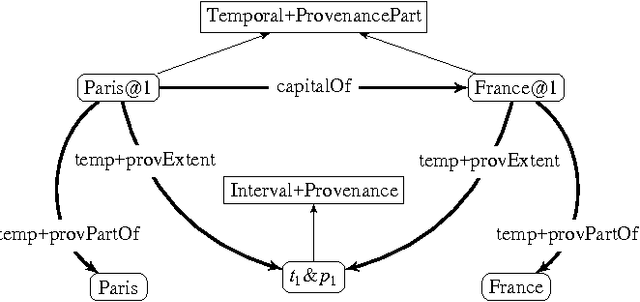
Annotating semantic data with metadata is becoming more and more important to provide information about the statements being asserted. While initial solutions proposed a data model to represent a specific dimension of meta-information (such as time or provenance), the need for a general annotation framework which allows representing different context dimensions is needed. In this paper, we extend the 4dFluents ontology by Welty and Fikes---on associating temporal validity to statements---to any dimension of context, and discuss possible issues that multidimensional context representations have to face and how we address them.