 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimosa Framework: Toward Evolving Multi-Agent Systems for Scientific Research
Mar 30, 2026Current Autonomous Scientific Research (ASR) systems, despite leveraging large language models (LLMs) and agentic architectures, remain constrained by fixed workflows and toolsets that prevent adaptation to evolving tasks and environments. We introduce Mimosa, an evolving multi-agent framework that automatically synthesizes task-specific multi-agent workflows and iteratively refines them through experimental feedback. Mimosa leverages the Model Context Protocol (MCP) for dynamic tool discovery, generates workflow topologies via a meta-orchestrator, executes subtasks through code-generating agents that invoke available tools and scientific software libraries, and scores executions with an LLM-based judge whose feedback drives workflow refinement. On ScienceAgentBench, Mimosa achieves a success rate of 43.1% with DeepSeek-V3.2, surpassing both single-agent baselines and static multi-agent configurations. Our results further reveal that models respond heterogeneously to multi-agent decomposition and iterative learning, indicating that the benefits of workflow evolution depend on the capabilities of the underlying execution model. Beyond these benchmarks, Mimosa modular architecture and tool-agnostic design make it readily extensible, and its fully logged execution traces and archived workflows support auditability by preserving every analytical step for inspection and potential replication. Combined with domain-expert guidance, the framework has the potential to automate a broad range of computationally accessible scientific tasks across disciplines. Released as a fully open-source platform, Mimosa aims to provide an open foundation for community-driven ASR.
MetaboT: AI-based agent for natural language-based interaction with metabolomics knowledge graphs
Oct 02, 2025Mass spectrometry metabolomics generates vast amounts of data requiring advanced methods for interpretation. Knowledge graphs address these challenges by structuring mass spectrometry data, metabolite information, and their relationships into a connected network (Gaudry et al. 2024). However, effective use of a knowledge graph demands an in-depth understanding of its ontology and its query language syntax. To overcome this, we designed MetaboT, an AI system utilizing large language models (LLMs) to translate user questions into SPARQL semantic query language for operating on knowledge graphs (Steve Harris 2013). We demonstrate its effectiveness using the Experimental Natural Products Knowledge Graph (ENPKG), a large-scale public knowledge graph for plant natural products (Gaudry et al. 2024).MetaboT employs specialized AI agents for handling user queries and interacting with the knowledge graph by breaking down complex tasks into discrete components, each managed by a specialised agent (Fig. 1a). The multi-agent system is constructed using the LangChain and LangGraph libraries, which facilitate the integration of LLMs with external tools and information sources (LangChain, n.d.). The query generation process follows a structured workflow. First, the Entry Agent determines if the question is new or a follow-up to previous interactions. New questions are forwarded to the Validator Agent, which verifies if the question is related to the knowledge graph. Then, the valid question is sent to the Supervisor Agent, which identifies if the question requires chemical conversions or standardized identifiers. In this case it delegates the question to the Knowledge Graph Agent, which can use tools to extract necessary details, such as URIs or taxonomies of chemical names, from the user query. Finally, an agent responsible for crafting the SPARQL queries equipped with the ontology of the knowledge graph uses the provided identifiers to generate the query. Then, the system executes the generated query against the metabolomics knowledge graph and returns structured results to the user (Fig. 1b). To assess the performance of MetaboT we have curated 50 metabolomics-related questions and their expected answers. In addition to submitting these questions to MetaboT, we evaluated a baseline by submitting them to a standard LLM (GPT-4o) with a prompt that incorporated the knowledge graph ontology but did not provide specific entity IDs. This baseline achieved only 8.16% accuracy, compared to MetaboT's 83.67%, underscoring the necessity of our multi-agent system for accurately retrieving entities and generating correct SPARQL queries. MetaboT demonstrates promising performance as a conversational question-answering assistant, enabling researchers to retrieve structured metabolomics data through natural language queries. By automating the generation and execution of SPARQL queries, it removes technical barriers that have traditionally hindered access to knowledge graphs. Importantly, MetaboT leverages the capabilities of LLMs while maintaining experimentally grounded query generation, ensuring that outputs remain aligned with domain-specific standards and data structures. This approach facilitates data-driven discoveries by bridging the gap between complex semantic technologies and user-friendly interaction. MetaboT is accessible at [https://metabot.holobiomicslab.eu/], and its source code is available at [https://github.com/HolobiomicsLab/MetaboT].
Q${}^2$Forge: Minting Competency Questions and SPARQL Queries for Question-Answering Over Knowledge Graphs
May 19, 2025The SPARQL query language is the standard method to access knowledge graphs (KGs). However, formulating SPARQL queries is a significant challenge for non-expert users, and remains time-consuming for the experienced ones. Best practices recommend to document KGs with competency questions and example queries to contextualise the knowledge they contain and illustrate their potential applications. In practice, however, this is either not the case or the examples are provided in limited numbers. Large Language Models (LLMs) are being used in conversational agents and are proving to be an attractive solution with a wide range of applications, from simple question-answering about common knowledge to generating code in a targeted programming language. However, training and testing these models to produce high quality SPARQL queries from natural language questions requires substantial datasets of question-query pairs. In this paper, we present Q${}^2$Forge that addresses the challenge of generating new competency questions for a KG and corresponding SPARQL queries. It iteratively validates those queries with human feedback and LLM as a judge. Q${}^2$Forge is open source, generic, extensible and modular, meaning that the different modules of the application (CQ generation, query generation and query refinement) can be used separately, as an integrated pipeline, or replaced by alternative services. The result is a complete pipeline from competency question formulation to query evaluation, supporting the creation of reference query sets for any target KG.
Content negotiation on the Web: State of the art
Apr 21, 2022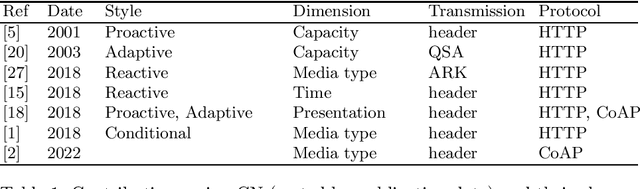
The openness and accessibility of the Web has contributed greatly to its worldwide adoption. Uniform Resource Identifiers (URIs) are used for resource identification on the Web. A resource on the Web can be described in many ways, which makes it difficult for a user to find an adequate representation. This situation has motivated fruitful research on content negotiation to satisfy user requirements efficiently and effectively. We focus on the important topic of content negotiation, and our goal is to present the first comprehensive state of the art. Our contributions include (1) identifying the characteristics of content negotiation scenarios (styles, dimensions, and means of conveying constraints), (2) comparing and classifying existing contributions, (3) identifying use cases that the current state of content negotiation struggles to address, (4) suggesting research directions for future work. The results of the state of the art show that the problem of content negotiation is relevant and far from being solved.