 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-linear RACE Sketches for Approximate Kernel Density Estimation on Streaming Data
Dec 04, 2019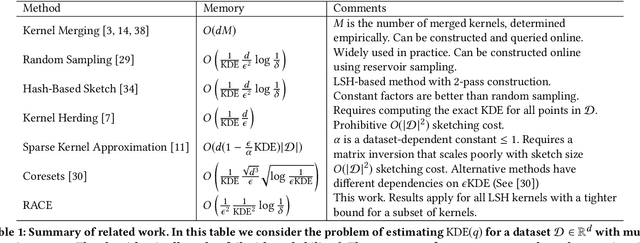
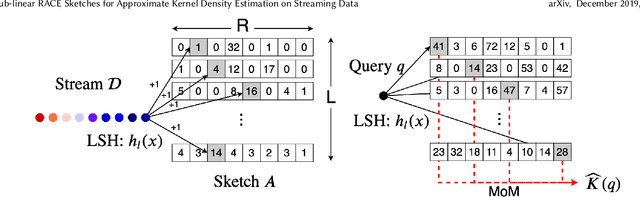
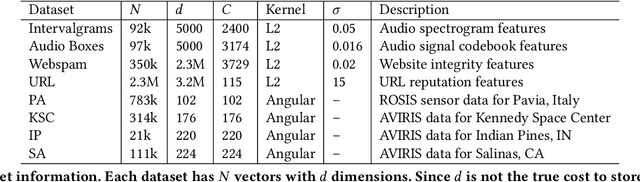
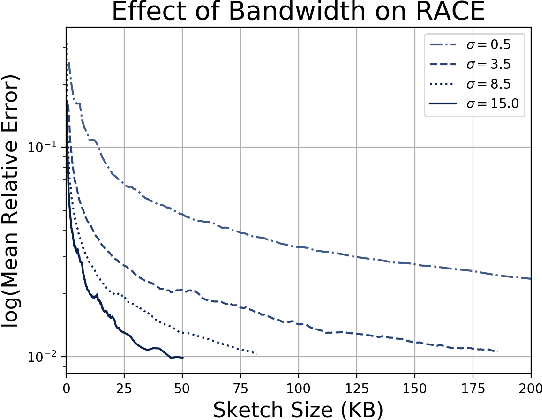
Kernel density estimation is a simple and effective method that lies at the heart of many important machine learning applications. Unfortunately, kernel methods scale poorly for large, high dimensional datasets. Approximate kernel density estimation has a prohibitively high memory and computation cost, especially in the streaming setting. Recent sampling algorithms for high dimensional densities can reduce the computation cost but cannot operate online, while streaming algorithms cannot handle high dimensional datasets due to the curse of dimensionality. We propose RACE, an efficient sketching algorithm for kernel density estimation on high-dimensional streaming data. RACE compresses a set of N high dimensional vectors into a small array of integer counters. This array is sufficient to estimate the kernel density for a large class of kernels. Our sketch is practical to implement and comes with strong theoretical guarantees. We evaluate our method on real-world high-dimensional datasets and show that our sketch achieves 10x better compression compared to competing methods.
FourierSAT: A Fourier Expansion-Based Algebraic Framework for Solving Hybrid Boolean Constraints
Dec 02, 2019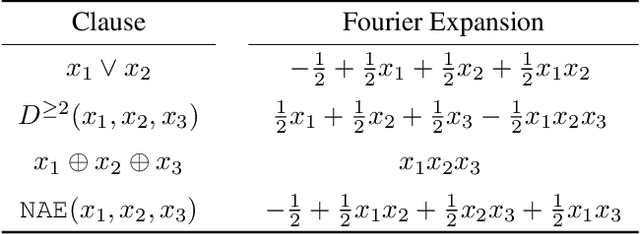
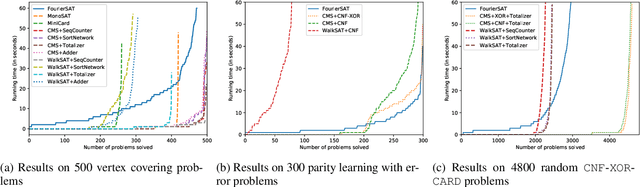
The Boolean SATisfiability problem (SAT) is of central importance in computer science. Although SAT is known to be NP-complete, progress on the engineering side, especially that of Conflict-Driven Clause Learning (CDCL) and Local Search SAT solvers, has been remarkable. Yet, while SAT solvers aimed at solving industrial-scale benchmarks in Conjunctive Normal Form (CNF) have become quite mature, SAT solvers that are effective on other types of constraints, e.g., cardinality constraints and XORs, are less well studied; a general approach to handling non-CNF constraints is still lacking. In addition, previous work indicated that for specific classes of benchmarks, the running time of extant SAT solvers depends heavily on properties of the formula and details of encoding, instead of the scale of the benchmarks, which adds uncertainty to expectations of running time. To address the issues above, we design FourierSAT, an incomplete SAT solver based on Fourier analysis of Boolean functions, a technique to represent Boolean functions by multilinear polynomials. By such a reduction to continuous optimization, we propose an algebraic framework for solving systems consisting of different types of constraints. The idea is to leverage gradient information to guide the search process in the direction of local improvements. Empirical results demonstrate that FourierSAT is more robust than other solvers on certain classes of benchmarks.
Lsh-sampling Breaks the Computation Chicken-and-egg Loop in Adaptive Stochastic Gradient Estimation
Oct 30, 2019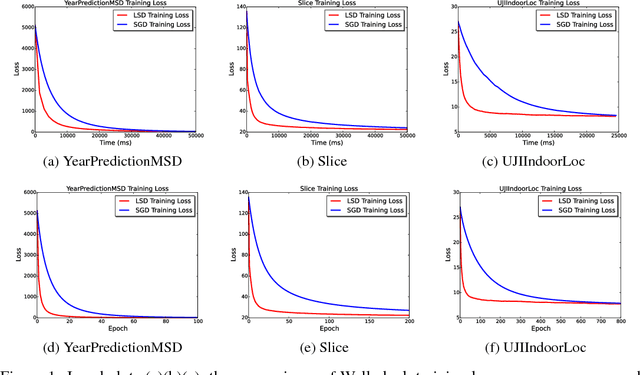
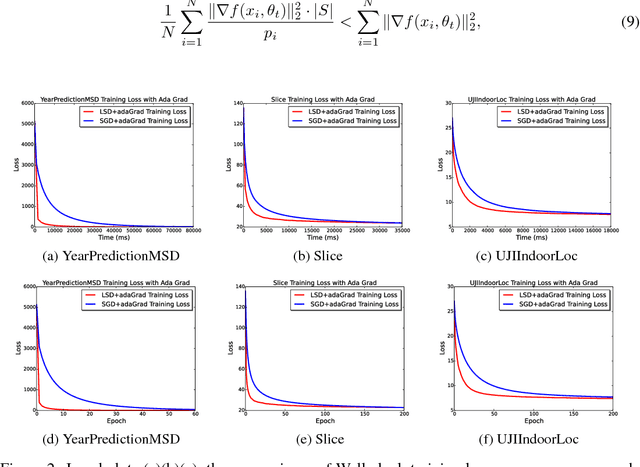
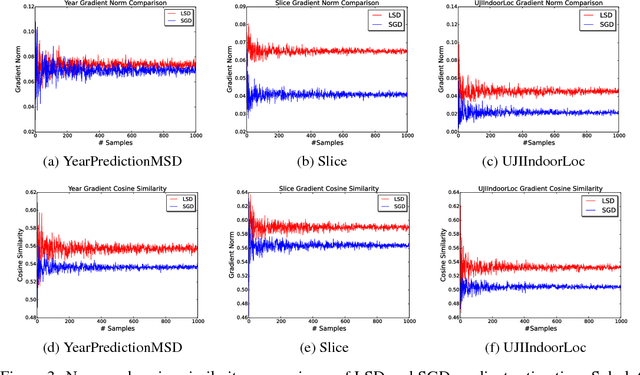
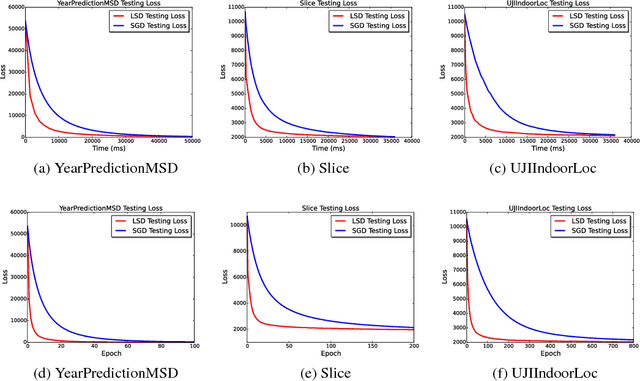
Stochastic Gradient Descent or SGD is the most popular optimization algorithm for large-scale problems. SGD estimates the gradient by uniform sampling with sample size one. There have been several other works that suggest faster epoch-wise convergence by using weighted non-uniform sampling for better gradient estimates. Unfortunately, the per-iteration cost of maintaining this adaptive distribution for gradient estimation is more than calculating the full gradient itself, which we call the chicken-and-the-egg loop. As a result, the false impression of faster convergence in iterations, in reality, leads to slower convergence in time. In this paper, we break this barrier by providing the first demonstration of a scheme, Locality sensitive hashing (LSH) sampled Stochastic Gradient Descent (LGD), which leads to superior gradient estimation while keeping the sampling cost per iteration similar to that of the uniform sampling. Such an algorithm is possible due to the sampling view of LSH, which came to light recently. As a consequence of superior and fast estimation, we reduce the running time of all existing gradient descent algorithms, that relies on gradient estimates including Adam, Ada-grad, etc. We demonstrate the effectiveness of our proposal with experiments on linear models as well as the non-linear BERT, which is a recent popular deep learning based language representation model.
Extreme Classification in Log Memory using Count-Min Sketch: A Case Study of Amazon Search with 50M Products
Oct 28, 2019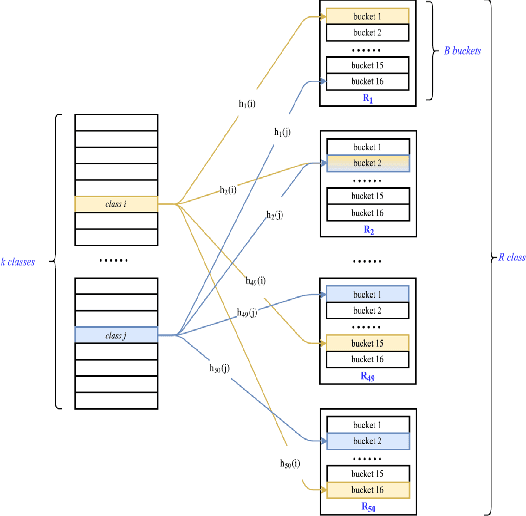

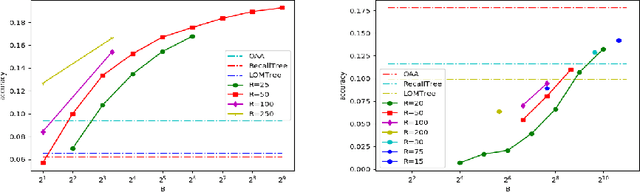
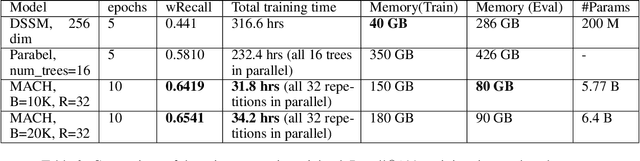
In the last decade, it has been shown that many hard AI tasks, especially in NLP, can be naturally modeled as extreme classification problems leading to improved precision. However, such models are prohibitively expensive to train due to the memory blow-up in the last layer. For example, a reasonable softmax layer for the dataset of interest in this paper can easily reach well beyond 100 billion parameters (>400 GB memory). To alleviate this problem, we present Merged-Average Classifiers via Hashing (MACH), a generic K-classification algorithm where memory provably scales at O(logK) without any strong assumption on the classes. MACH is subtly a count-min sketch structure in disguise, which uses universal hashing to reduce classification with a large number of classes to few embarrassingly parallel and independent classification tasks with a small (constant) number of classes. MACH naturally provides a technique for zero communication model parallelism. We experiment with 6 datasets; some multiclass and some multilabel, and show consistent improvement over respective state-of-the-art baselines. In particular, we train an end-to-end deep classifier on a private product search dataset sampled from Amazon Search Engine with 70 million queries and 49.46 million products. MACH outperforms, by a significant margin,the state-of-the-art extreme classification models deployed on commercial search engines: Parabel and dense embedding models. Our largest model has 6.4 billion parameters and trains in less than 35 hours on a single p3.16x machine. Our training times are 7-10x faster, and our memory footprints are 2-4x smaller than the best baselines. This training time is also significantly lower than the one reported by Google's mixture of experts (MoE) language model on a comparable model size and hardware.
Adaptive Learned Bloom Filter (Ada-BF): Efficient Utilization of the Classifier
Oct 21, 2019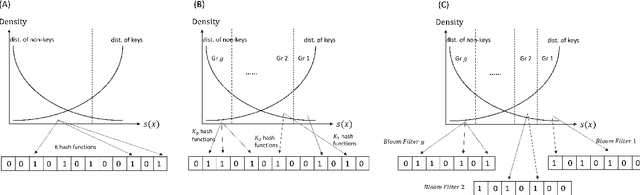
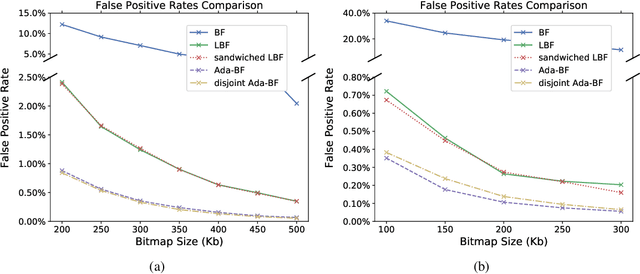
Recent work suggests improving the performance of Bloom filter by incorporating a machine learning model as a binary classifier. However, such learned Bloom filter does not take full advantage of the predicted probability scores. We proposed new algorithms that generalize the learned Bloom filter by using the complete spectrum of the scores regions. We proved our algorithms have lower False Positive Rate (FPR) and memory usage compared with the existing approaches to learned Bloom filter. We also demonstrated the improved performance of our algorithms on real-world datasets.
Semantic Similarity Based Softmax Classifier for Zero-Shot Learning
Sep 10, 2019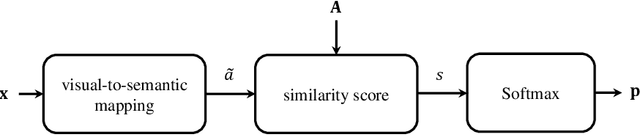
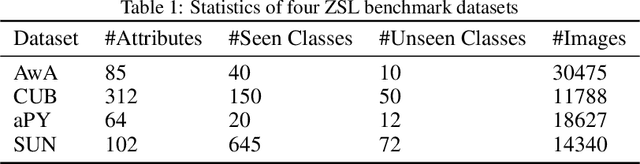
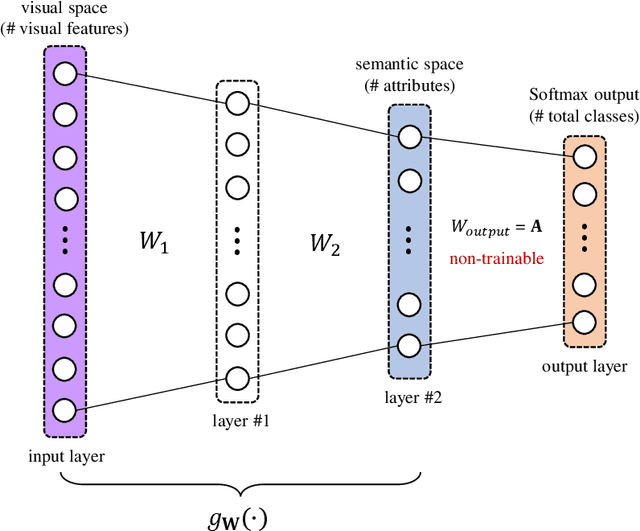
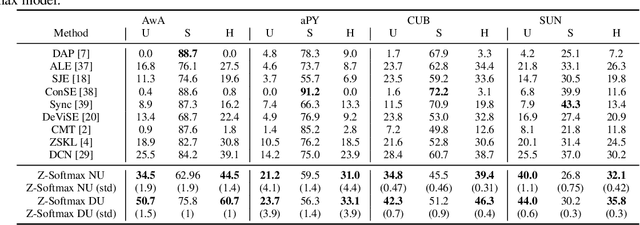
Zero-Shot Learning (ZSL) is a classification task where we do not have even a single training labeled example from a set of unseen classes. Instead, we only have prior information (or description) about seen and unseen classes, often in the form of physically realizable or descriptive attributes. Lack of any single training example from a set of classes prohibits use of standard classification techniques and losses, including the popular crossentropy loss. Currently, state-of-the-art approaches encode the prior class information into dense vectors and optimize some distance between the learned projections of the input vector and the corresponding class vector (collectively known as embedding models). In this paper, we propose a novel architecture of casting zero-shot learning as a standard neural-network with crossentropy loss. During training our approach performs soft-labeling by combining the observed training data for the seen classes with the similarity information from the attributes for which we have no training data or unseen classes. To the best of our knowledge, such similarity based soft-labeling is not explored in the field of deep learning. We evaluate the proposed model on the four benchmark datasets for zero-shot learning, AwA, aPY, SUN and CUB datasets, and show that our model achieves significant improvement over the state-of-the-art methods in Generalized-ZSL and ZSL settings on all of these datasets consistently.
RACE: Sub-Linear Memory Sketches for Approximate Near-Neighbor Search on Streaming Data
Apr 09, 2019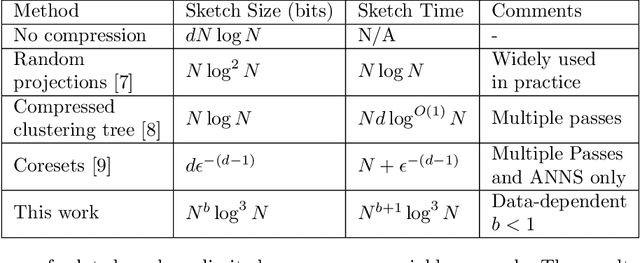
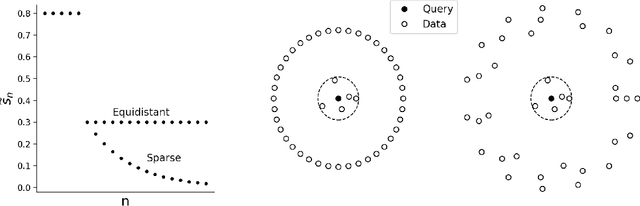
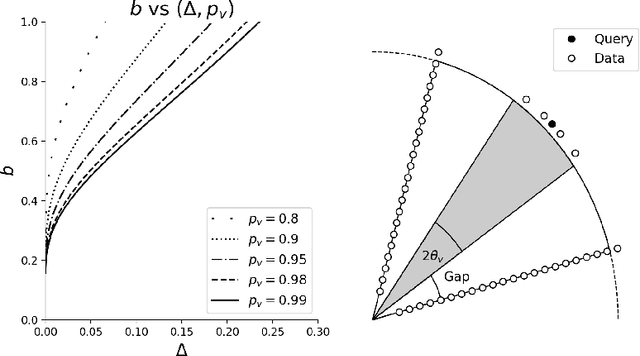
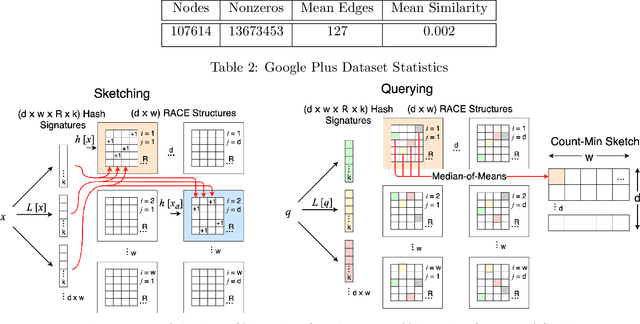
We present the first sublinear memory sketch which can be queried to find the $v$ nearest neighbors in a dataset. Our online sketching algorithm can compress an $N$-element dataset to a sketch of size $O(N^b \log^3{N})$ in $O(N^{b+1} \log^3{N})$ time, where $b < 1$ when the query satisfies a data-dependent near-neighbor stability condition. We achieve data-dependent sublinear space by combining recent advances in locality sensitive hashing (LSH)-based estimators with compressed sensing. Our results shed new light on the memory-accuracy tradeoff for near-neighbor search. The techniques presented reveal a deep connection between the fundamental compressed sensing (or heavy hitters) recovery problem and near-neighbor search, leading to new insight for geometric search problems and implications for sketching algorithms.
Using Local Experiences for Global Motion Planning
Mar 20, 2019
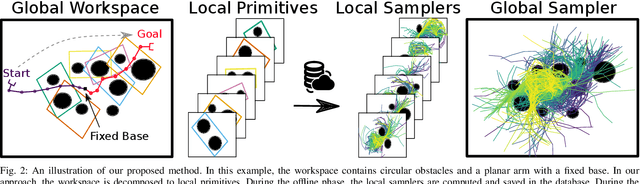
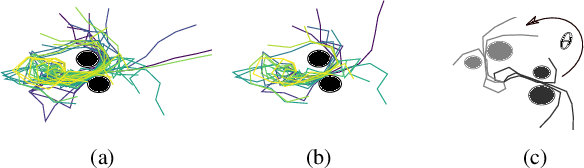
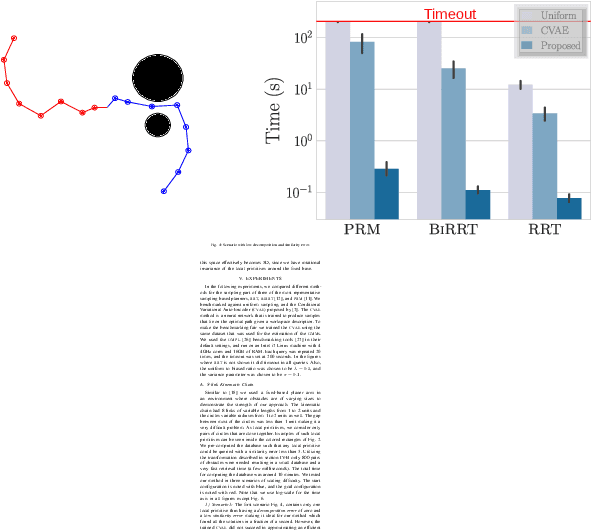
Sampling-based planners are effective in many real-world applications such as robotics manipulation, navigation, and even protein modeling. However, it is often challenging to generate a collision-free path in environments where key areas are hard to sample. In the absence of any prior information, sampling-based planners are forced to explore uniformly or heuristically, which can lead to degraded performance. One way to improve performance is to use prior knowledge of environments to adapt the sampling strategy to the problem at hand. In this work, we decompose the workspace into local primitives, memorizing local experiences by these primitives in the form of local samplers, and store them in a database. We synthesize an efficient global sampler by retrieving local experiences relevant to the given situation. Our method transfers knowledge effectively between diverse environments that share local primitives and speeds up the performance dramatically. Our results show, in terms of solution time, an improvement of multiple orders of magnitude in two traditionally challenging high-dimensional problems compared to state-of-the-art approaches.
SLIDE : In Defense of Smart Algorithms over Hardware Acceleration for Large-Scale Deep Learning Systems
Mar 07, 2019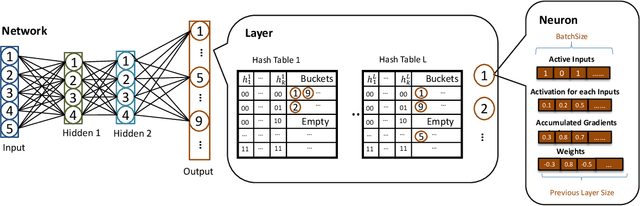

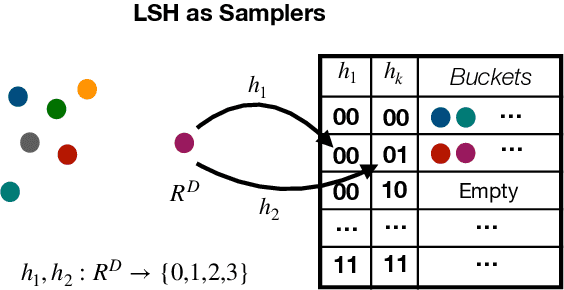
Deep Learning (DL) algorithms are the central focus of modern machine learning systems. As data volumes keep growing, it has become customary to train large neural networks with hundreds of millions of parameters with enough capacity to memorize these volumes and obtain state-of-the-art accuracy. To get around the costly computations associated with large models and data, the community is increasingly investing in specialized hardware for model training. However, with the end of Moore's law, there is a limit to such scaling. The progress on the algorithmic front has failed to demonstrate a direct advantage over powerful hardware such as NVIDIA-V100 GPUs. This paper provides an exception. We propose SLIDE (Sub-LInear Deep learning Engine) that uniquely blends smart randomized algorithms, which drastically reduce the computation during both training and inference, with simple multi-core parallelism on a modest CPU. SLIDE is an auspicious illustration of the power of smart randomized algorithms over CPUs in outperforming the best available GPU with an optimized implementation. Our evaluations on large industry-scale datasets, with some large fully connected architectures, show that training with SLIDE on a 44 core CPU is more than 2.7 times (2 hours vs. 5.5 hours) faster than the same network trained using Tensorflow on Tesla V100 at any given accuracy level. We provide codes and benchmark scripts for reproducibility.
Compressing Gradient Optimizers via Count-Sketches
Feb 26, 2019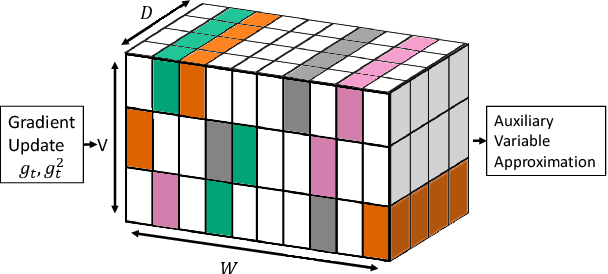

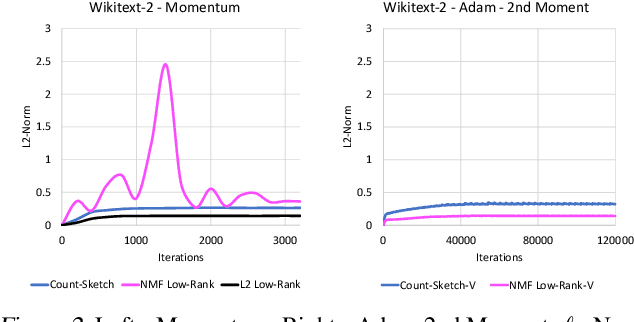
Many popular first-order optimization methods (e.g., Momentum, AdaGrad, Adam) accelerate the convergence rate of deep learning models. However, these algorithms require auxiliary parameters, which cost additional memory proportional to the number of parameters in the model. The problem is becoming more severe as deep learning models continue to grow larger in order to learn from complex, large-scale datasets. Our proposed solution is to maintain a linear sketch to compress the auxiliary variables. We demonstrate that our technique has the same performance as the full-sized baseline, while using significantly less space for the auxiliary variables. Theoretically, we prove that count-sketch optimization maintains the SGD convergence rate, while gracefully reducing memory usage for large-models. On the large-scale 1-Billion Word dataset, we save 25% of the memory used during training (8.6 GB instead of 11.7 GB) by compressing the Adam optimizer in the Embedding and Softmax layers with negligible accuracy and performance loss. For an Amazon extreme classification task with over 49.5 million classes, we also reduce the training time by 38%, by increasing the mini-batch size 3.5x using our count-sketch optimizer.