 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Offset Block Embedding Array (ROBE) for CriteoTB Benchmark MLPerf DLRM Model : 1000$\times$ Compression and 2.7$\times$ Faster Inference
Aug 04, 2021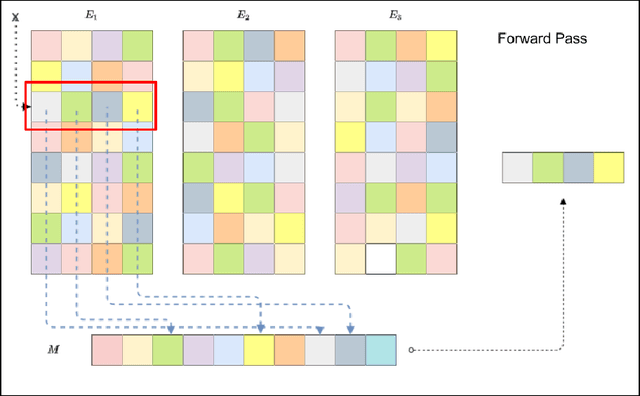

Deep learning for recommendation data is the one of the most pervasive and challenging AI workload in recent times. State-of-the-art recommendation models are one of the largest models rivalling the likes of GPT-3 and Switch Transformer. Challenges in deep learning recommendation models (DLRM) stem from learning dense embeddings for each of the categorical values. These embedding tables in industrial scale models can be as large as hundreds of terabytes. Such large models lead to a plethora of engineering challenges, not to mention prohibitive communication overheads, and slower training and inference times. Of these, slower inference time directly impacts user experience. Model compression for DLRM is gaining traction and the community has recently shown impressive compression results. In this paper, we present Random Offset Block Embedding Array (ROBE) as a low memory alternative to embedding tables which provide orders of magnitude reduction in memory usage while maintaining accuracy and boosting execution speed. ROBE is a simple fundamental approach in improving both cache performance and the variance of randomized hashing, which could be of independent interest in itself. We demonstrate that we can successfully train DLRM models with same accuracy while using $1000 \times$ less memory. A $1000\times$ compressed model directly results in faster inference without any engineering. In particular, we show that we can train DLRM model using ROBE Array of size 100MB on a single GPU to achieve AUC of 0.8025 or higher as required by official MLPerf CriteoTB benchmark DLRM model of 100GB while achieving about $2.7\times$ (170\%) improvement in inference throughput.
Efficient Inference via Universal LSH Kernel
Jun 21, 2021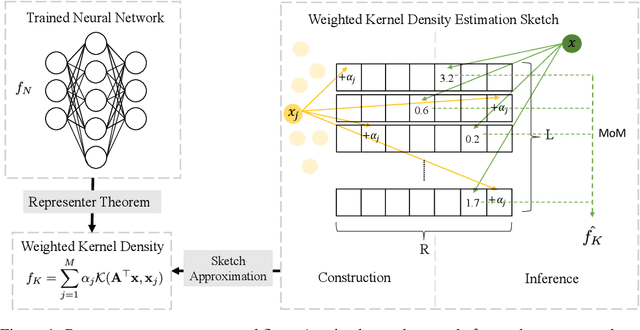
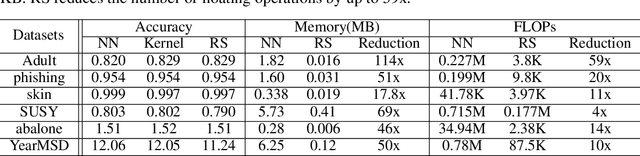
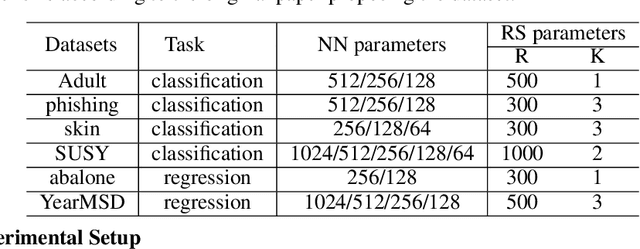
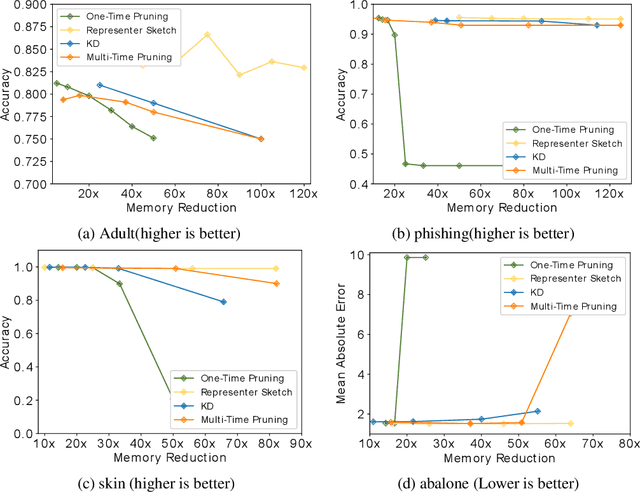
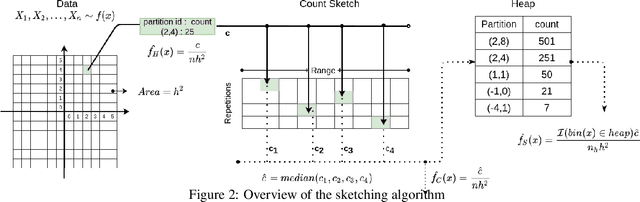
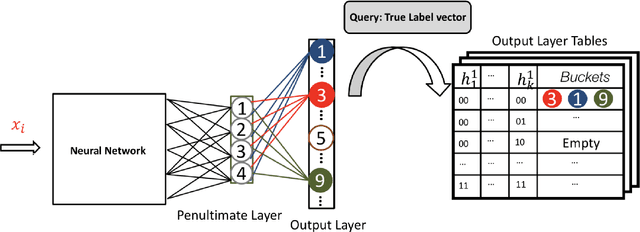
Large machine learning models achieve unprecedented performance on various tasks and have evolved as the go-to technique. However, deploying these compute and memory hungry models on resource constraint environments poses new challenges. In this work, we propose mathematically provable Representer Sketch, a concise set of count arrays that can approximate the inference procedure with simple hashing computations and aggregations. Representer Sketch builds upon the popular Representer Theorem from kernel literature, hence the name, providing a generic fundamental alternative to the problem of efficient inference that goes beyond the popular approach such as quantization, iterative pruning and knowledge distillation. A neural network function is transformed to its weighted kernel density representation, which can be very efficiently estimated with our sketching algorithm. Empirically, we show that Representer Sketch achieves up to 114x reduction in storage requirement and 59x reduction in computation complexity without any drop in accuracy.
PairConnect: A Compute-Efficient MLP Alternative to Attention
Jun 15, 2021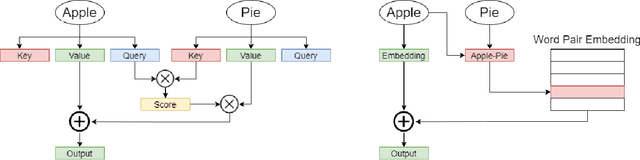
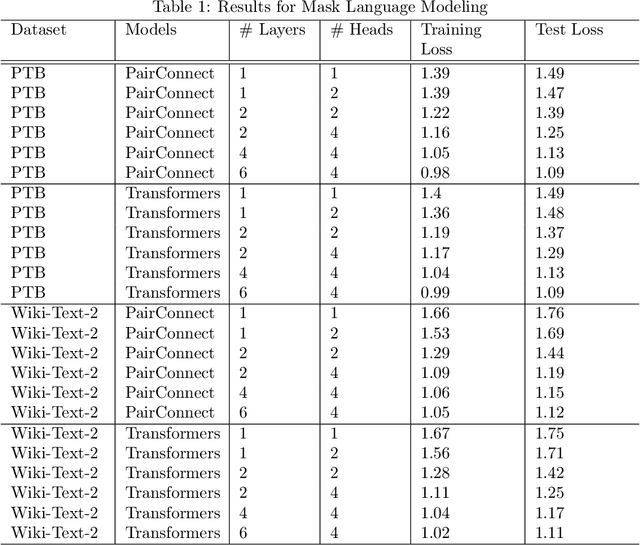
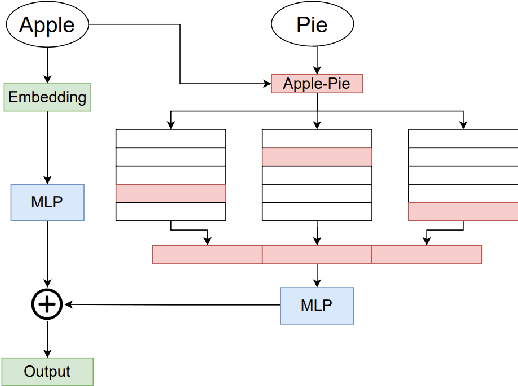
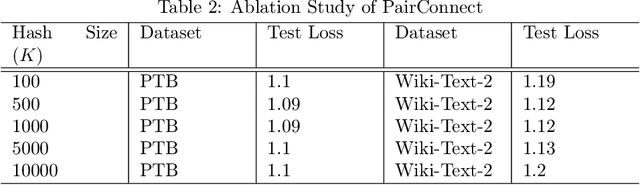
Transformer models have demonstrated superior performance in natural language processing. The dot product self-attention in Transformer allows us to model interactions between words. However, this modeling comes with significant computational overhead. In this work, we revisit the memory-compute trade-off associated with Transformer, particularly multi-head attention, and show a memory-heavy but significantly more compute-efficient alternative to Transformer. Our proposal, denoted as PairConnect, a multilayer perceptron (MLP), models the pairwise interaction between words by explicit pairwise word embeddings. As a result, PairConnect substitutes self dot product with a simple embedding lookup. We show mathematically that despite being an MLP, our compute-efficient PairConnect is strictly more expressive than Transformer. Our experiment on language modeling tasks suggests that PairConnect could achieve comparable results with Transformer while reducing the computational cost associated with inference significantly.
Sublinear Least-Squares Value Iteration via Locality Sensitive Hashing
Jun 08, 2021
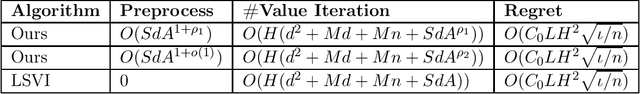

We present the first provable Least-Squares Value Iteration (LSVI) algorithms that have runtime complexity sublinear in the number of actions. We formulate the value function estimation procedure in value iteration as an approximate maximum inner product search problem and propose a locality sensitive hashing (LSH) [Indyk and Motwani STOC'98, Andoni and Razenshteyn STOC'15, Andoni, Laarhoven, Razenshteyn and Waingarten SODA'17] type data structure to solve this problem with sublinear time complexity. Moreover, we build the connections between the theory of approximate maximum inner product search and the regret analysis of reinforcement learning. We prove that, with our choice of approximation factor, our Sublinear LSVI algorithms maintain the same regret as the original LSVI algorithms while reducing the runtime complexity to sublinear in the number of actions. To the best of our knowledge, this is the first work that combines LSH with reinforcement learning resulting in provable improvements. We hope that our novel way of combining data-structures and iterative algorithm will open the door for further study into cost reduction in optimization.
IRLI: Iterative Re-partitioning for Learning to Index
Mar 17, 2021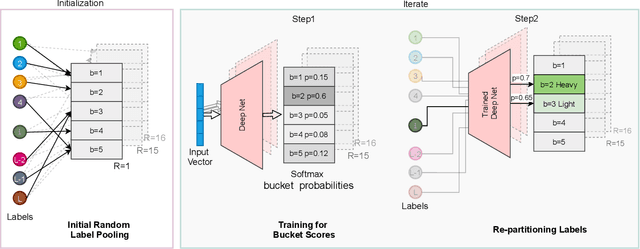
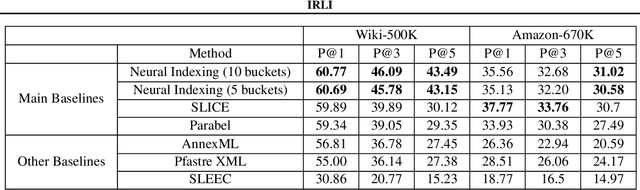
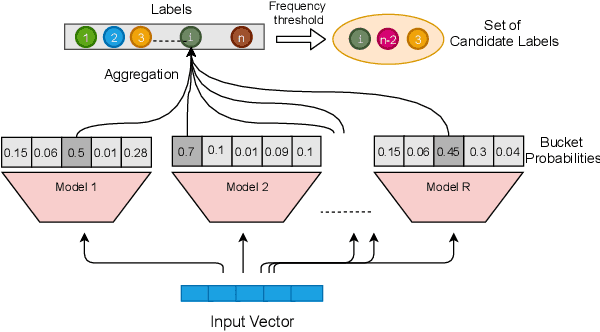
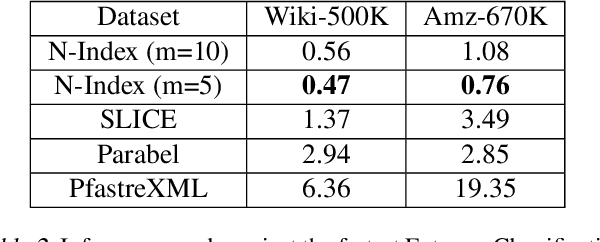
Neural models have transformed the fundamental information retrieval problem of mapping a query to a giant set of items. However, the need for efficient and low latency inference forces the community to reconsider efficient approximate near-neighbor search in the item space. To this end, learning to index is gaining much interest in recent times. Methods have to trade between obtaining high accuracy while maintaining load balance and scalability in distributed settings. We propose a novel approach called IRLI (pronounced `early'), which iteratively partitions the items by learning the relevant buckets directly from the query-item relevance data. Furthermore, IRLI employs a superior power-of-$k$-choices based load balancing strategy. We mathematically show that IRLI retrieves the correct item with high probability under very natural assumptions and provides superior load balancing. IRLI surpasses the best baseline's precision on multi-label classification while being $5x$ faster on inference. For near-neighbor search tasks, the same method outperforms the state-of-the-art Learned Hashing approach NeuralLSH by requiring only ~ {1/6}^th of the candidates for the same recall. IRLI is both data and model parallel, making it ideal for distributed GPU implementation. We demonstrate this advantage by indexing 100 million dense vectors and surpassing the popular FAISS library by >10% on recall.
Accelerating SLIDE Deep Learning on Modern CPUs: Vectorization, Quantizations, Memory Optimizations, and More
Mar 06, 2021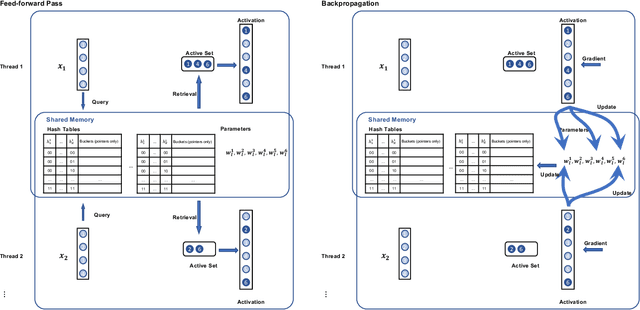


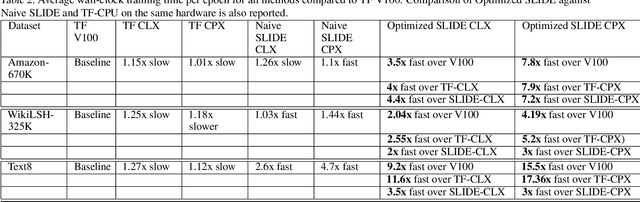
Deep learning implementations on CPUs (Central Processing Units) are gaining more traction. Enhanced AI capabilities on commodity x86 architectures are commercially appealing due to the reuse of existing hardware and virtualization ease. A notable work in this direction is the SLIDE system. SLIDE is a C++ implementation of a sparse hash table based back-propagation, which was shown to be significantly faster than GPUs in training hundreds of million parameter neural models. In this paper, we argue that SLIDE's current implementation is sub-optimal and does not exploit several opportunities available in modern CPUs. In particular, we show how SLIDE's computations allow for a unique possibility of vectorization via AVX (Advanced Vector Extensions)-512. Furthermore, we highlight opportunities for different kinds of memory optimization and quantizations. Combining all of them, we obtain up to 7x speedup in the computations on the same hardware. Our experiments are focused on large (hundreds of millions of parameters) recommendation and NLP models. Our work highlights several novel perspectives and opportunities for implementing randomized algorithms for deep learning on modern CPUs. We provide the code and benchmark scripts at https://github.com/RUSH-LAB/SLIDE
Beyond Convolutions: A Novel Deep Learning Approach for Raw Seismic Data Ingestion
Feb 26, 2021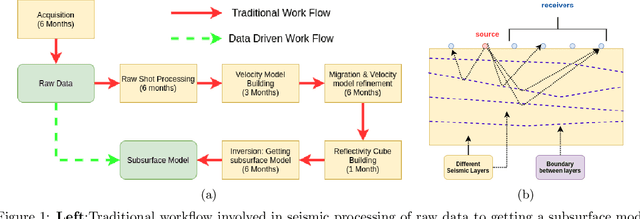

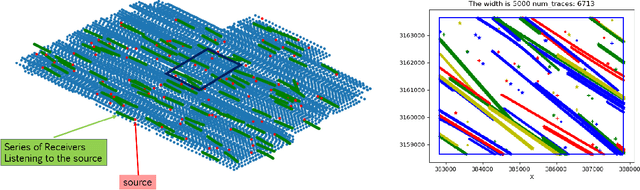
Traditional seismic processing workflows (SPW) are expensive, requiring over a year of human and computational effort. Deep learning (DL) based data-driven seismic workflows (DSPW) hold the potential to reduce these timelines to a few minutes. Raw seismic data (terabytes) and required subsurface prediction (gigabytes) are enormous. This large-scale, spatially irregular time-series data poses seismic data ingestion (SDI) as an unconventional yet fundamental problem in DSPW. Current DL research is limited to small-scale simplified synthetic datasets as they treat seismic data like images and process them with convolution networks. Real seismic data, however, is at least 5D. Applying 5D convolutions to this scale is computationally prohibitive. Moreover, raw seismic data is highly unstructured and hence inherently non-image like. We propose a fundamental shift to move away from convolutions and introduce SESDI: Set Embedding based SDI approach. SESDI first breaks down the mammoth task of large-scale prediction into an efficient compact auxiliary task. SESDI gracefully incorporates irregularities in data with its novel model architecture. We believe SESDI is the first successful demonstration of end-to-end learning on real seismic data. SESDI achieves SSIM of over 0.8 on velocity inversion task on real proprietary data from the Gulf of Mexico and outperforms the state-of-the-art U-Net model on synthetic datasets.
Semantically Constrained Memory Allocation (SCMA) for Embedding in Efficient Recommendation Systems
Feb 24, 2021
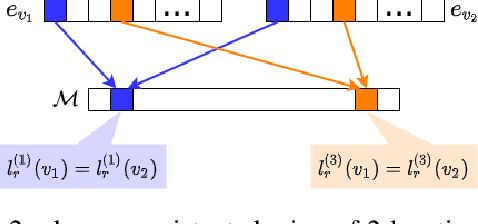
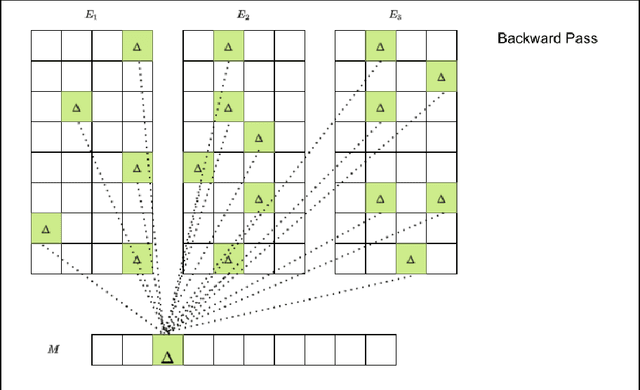
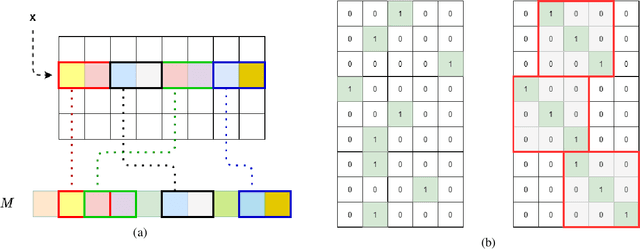
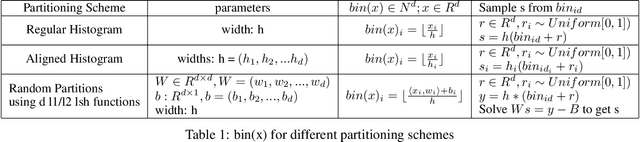
Deep learning-based models are utilized to achieve state-of-the-art performance for recommendation systems. A key challenge for these models is to work with millions of categorical classes or tokens. The standard approach is to learn end-to-end, dense latent representations or embeddings for each token. The resulting embeddings require large amounts of memory that blow up with the number of tokens. Training and inference with these models create storage, and memory bandwidth bottlenecks leading to significant computing and energy consumption when deployed in practice. To this end, we present the problem of \textit{Memory Allocation} under budget for embeddings and propose a novel formulation of memory shared embedding, where memory is shared in proportion to the overlap in semantic information. Our formulation admits a practical and efficient randomized solution with Locality sensitive hashing based Memory Allocation (LMA). We demonstrate a significant reduction in the memory footprint while maintaining performance. In particular, our LMA embeddings achieve the same performance compared to standard embeddings with a 16$\times$ reduction in memory footprint. Moreover, LMA achieves an average improvement of over 0.003 AUC across different memory regimes than standard DLRM models on Criteo and Avazu datasets
Density Sketches for Sampling and Estimation
Feb 24, 2021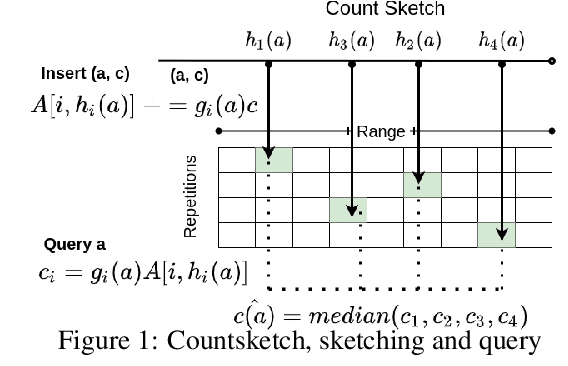
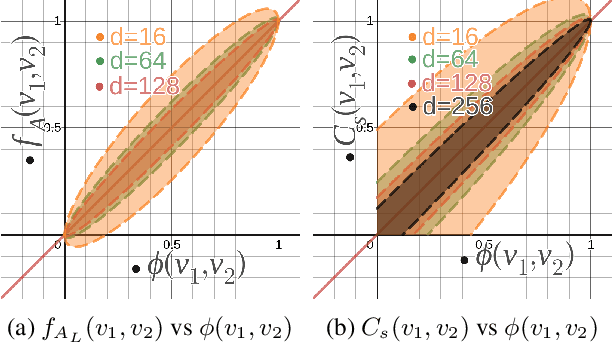
We introduce Density sketches (DS): a succinct online summary of the data distribution. DS can accurately estimate point wise probability density. Interestingly, DS also provides a capability to sample unseen novel data from the underlying data distribution. Thus, analogous to popular generative models, DS allows us to succinctly replace the real-data in almost all machine learning pipelines with synthetic examples drawn from the same distribution as the original data. However, unlike generative models, which do not have any statistical guarantees, DS leads to theoretically sound asymptotically converging consistent estimators of the underlying density function. Density sketches also have many appealing properties making them ideal for large-scale distributed applications. DS construction is an online algorithm. The sketches are additive, i.e., the sum of two sketches is the sketch of the combined data. These properties allow data to be collected from distributed sources, compressed into a density sketch, efficiently transmitted in the sketch form to a central server, merged, and re-sampled into a synthetic database for modeling applications. Thus, density sketches can potentially revolutionize how we store, communicate, and distribute data.
A Constant-time Adaptive Negative Sampling
Dec 31, 2020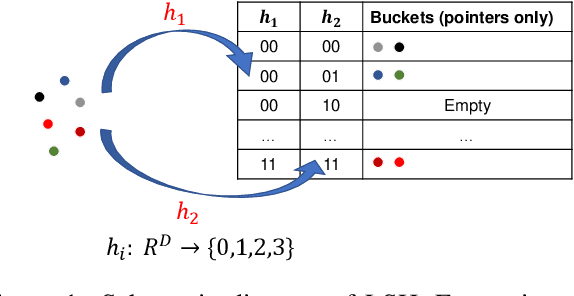

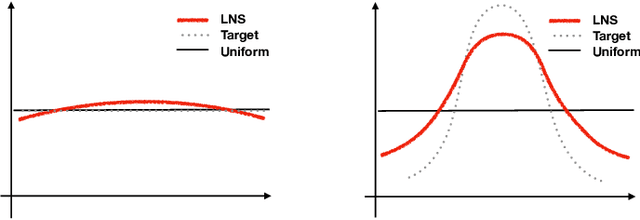
Softmax classifiers with a very large number of classes naturally occur in many applications such as natural language processing and information retrieval. The calculation of full-softmax is very expensive from the computational and energy perspective. There have been a variety of sampling approaches to overcome this challenge, popularly known as negative sampling (NS). Ideally, NS should sample negative classes from a distribution that is dependent on the input data, the current parameters, and the correct positive class. Unfortunately, due to the dynamically updated parameters and data samples, there does not exist any sampling scheme that is truly adaptive and also samples the negative classes in constant time every iteration. Therefore, alternative heuristics like random sampling, static frequency-based sampling, or learning-based biased sampling, which primarily trade either the sampling cost or the adaptivity of samples per iteration, are adopted. In this paper, we show a class of distribution where the sampling scheme is truly adaptive and provably generates negative samples in constant time. Our implementation in C++ on commodity CPU is significantly faster, in terms of wall clock time, compared to the most optimized TensorFlow implementations of standard softmax or other sampling approaches on modern GPUs (V100s).