 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNodeSynth: Socially Aligned Synthetic Data for AI Evaluation
May 14, 2026Recent advancements in generative AI facilitate large-scale synthetic data generation for model evaluation. However, without targeted approaches, these datasets often lack the sociotechnical nuance required for sensitive domains. We introduce NodeSynth, an evidence-grounded methodology that generates socially relevant synthetic queries by leveraging a fine-tuned taxonomy generator (TaG) anchored in real-world evidence. Evaluated against four mainstream LLMs (e.g., Claude 4.5 Haiku), NodeSynth elicited failure rates up to five times higher than human-authored benchmarks. Ablation studies confirm that our granular taxonomic expansion significantly drives these failure rates, while independent validation reveals critical deficiencies in prominent guard models (e.g., Llama-Guard-3). We open-source our end-to-end research prototype and datasets to enable scalable, high-stakes model evaluation and targeted safety interventions (https://github.com/google-research/nodesynth).
ISACL: Internal State Analyzer for Copyrighted Training Data Leakage
Aug 25, 2025



Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but pose risks of inadvertently exposing copyrighted or proprietary data, especially when such data is used for training but not intended for distribution. Traditional methods address these leaks only after content is generated, which can lead to the exposure of sensitive information. This study introduces a proactive approach: examining LLMs' internal states before text generation to detect potential leaks. By using a curated dataset of copyrighted materials, we trained a neural network classifier to identify risks, allowing for early intervention by stopping the generation process or altering outputs to prevent disclosure. Integrated with a Retrieval-Augmented Generation (RAG) system, this framework ensures adherence to copyright and licensing requirements while enhancing data privacy and ethical standards. Our results show that analyzing internal states effectively mitigates the risk of copyrighted data leakage, offering a scalable solution that fits smoothly into AI workflows, ensuring compliance with copyright regulations while maintaining high-quality text generation. The implementation is available on GitHub.\footnote{https://github.com/changhu73/Internal_states_leakage}
ALinFiK: Learning to Approximate Linearized Future Influence Kernel for Scalable Third-Parity LLM Data Valuation
Mar 02, 2025Large Language Models (LLMs) heavily rely on high-quality training data, making data valuation crucial for optimizing model performance, especially when working within a limited budget. In this work, we aim to offer a third-party data valuation approach that benefits both data providers and model developers. We introduce a linearized future influence kernel (LinFiK), which assesses the value of individual data samples in improving LLM performance during training. We further propose ALinFiK, a learning strategy to approximate LinFiK, enabling scalable data valuation. Our comprehensive evaluations demonstrate that this approach surpasses existing baselines in effectiveness and efficiency, demonstrating significant scalability advantages as LLM parameters increase.
Semantically Constrained Memory Allocation (SCMA) for Embedding in Efficient Recommendation Systems
Feb 24, 2021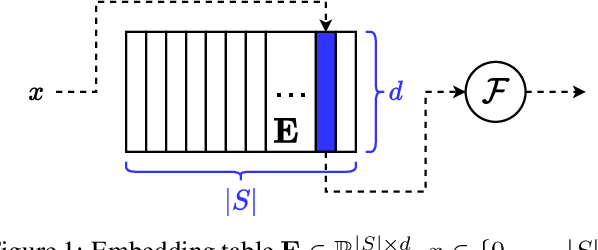
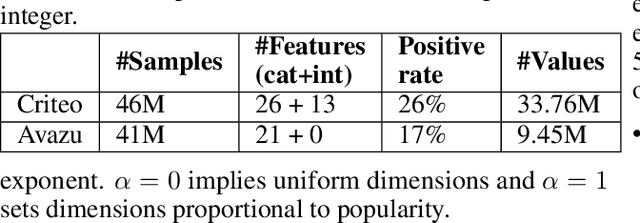
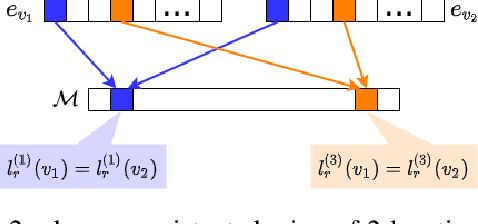
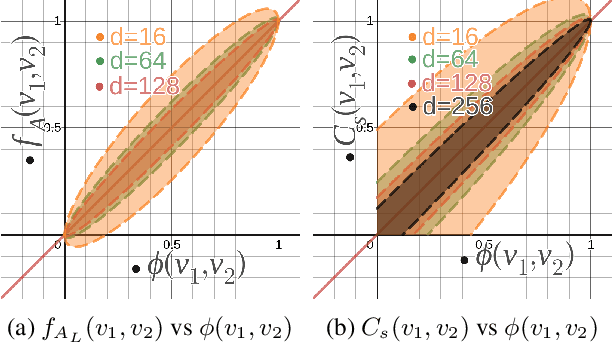
Deep learning-based models are utilized to achieve state-of-the-art performance for recommendation systems. A key challenge for these models is to work with millions of categorical classes or tokens. The standard approach is to learn end-to-end, dense latent representations or embeddings for each token. The resulting embeddings require large amounts of memory that blow up with the number of tokens. Training and inference with these models create storage, and memory bandwidth bottlenecks leading to significant computing and energy consumption when deployed in practice. To this end, we present the problem of \textit{Memory Allocation} under budget for embeddings and propose a novel formulation of memory shared embedding, where memory is shared in proportion to the overlap in semantic information. Our formulation admits a practical and efficient randomized solution with Locality sensitive hashing based Memory Allocation (LMA). We demonstrate a significant reduction in the memory footprint while maintaining performance. In particular, our LMA embeddings achieve the same performance compared to standard embeddings with a 16$\times$ reduction in memory footprint. Moreover, LMA achieves an average improvement of over 0.003 AUC across different memory regimes than standard DLRM models on Criteo and Avazu datasets