 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarger Probes Tell a Different Story: Extending Psycholinguistic Datasets Via In-Context Learning
Mar 29, 2023



Language model probing is often used to test specific capabilities of these models. However, conclusions from such studies may be limited when the probing benchmarks are small and lack statistical power. In this work, we introduce new, larger datasets for negation (NEG-1500-SIMP) and role reversal (ROLE-1500) inspired by psycholinguistic studies. We dramatically extend existing NEG-136 and ROLE-88 benchmarks using GPT3, increasing their size from 18 and 44 sentence pairs to 750 each. We also create another version of extended negation dataset (NEG-1500-SIMP-TEMP), created using template-based generation. It consists of 770 sentence pairs. We evaluate 22 models on the extended datasets, seeing model performance dip 20-57% compared to the original smaller benchmarks. We observe high levels of negation sensitivity in models like BERT and ALBERT demonstrating that previous findings might have been skewed due to smaller test sets. Finally, we observe that while GPT3 has generated all the examples in ROLE-1500 is only able to solve 24.6% of them during probing.
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
Mar 28, 2023



This paper presents a systematic overview and comparison of parameter-efficient fine-tuning methods covering over 40 papers published between February 2019 and February 2023. These methods aim to resolve the infeasibility and impracticality of fine-tuning large language models by only training a small set of parameters. We provide a taxonomy that covers a broad range of methods and present a detailed method comparison with a specific focus on real-life efficiency and fine-tuning multibillion-scale language models.
Reasoning Circuits: Few-shot Multihop Question Generation with Structured Rationales
Nov 15, 2022



Multi-hop Question Generation is the task of generating questions which require the reader to reason over and combine information spread across multiple passages using several reasoning steps. Chain-of-thought rationale generation has been shown to improve performance on multi-step reasoning tasks and make model predictions more interpretable. However, few-shot performance gains from including rationales have been largely observed only in +100B language models, and otherwise require large scale manual rationale annotation. In this work, we introduce a new framework for applying chain-of-thought inspired structured rationale generation to multi-hop question generation under a very low supervision regime (8- to 128-shot). We propose to annotate a small number of examples following our proposed multi-step rationale schema, treating each reasoning step as a separate task to be performed by a generative language model. We show that our framework leads to improved control over the difficulty of the generated questions and better performance compared to baselines trained without rationales, both on automatic evaluation metrics and in human evaluation. Importantly, we show that this is achievable with a modest model size.
On Task-Adaptive Pretraining for Dialogue Response Selection
Oct 08, 2022
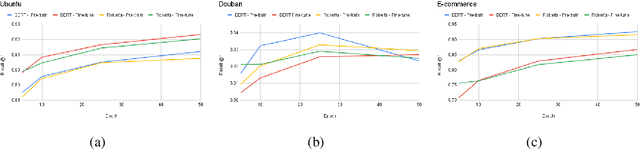
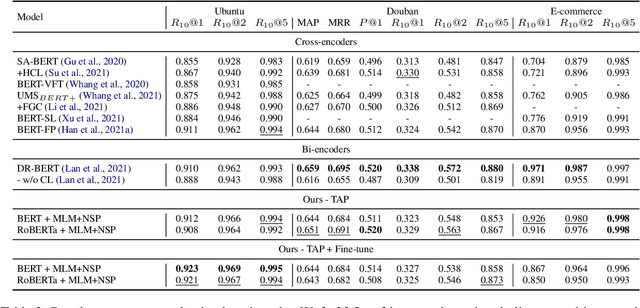
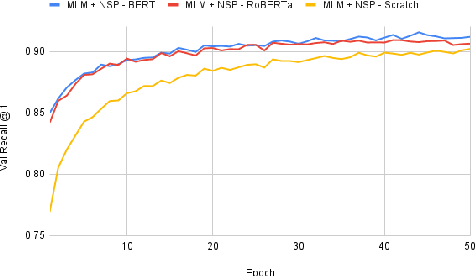
Recent advancements in dialogue response selection (DRS) are based on the \textit{task-adaptive pre-training (TAP)} approach, by first initializing their model with BERT~\cite{devlin-etal-2019-bert}, and adapt to dialogue data with dialogue-specific or fine-grained pre-training tasks. However, it is uncertain whether BERT is the best initialization choice, or whether the proposed dialogue-specific fine-grained learning tasks are actually better than MLM+NSP. This paper aims to verify assumptions made in previous works and understand the source of improvements for DRS. We show that initializing with RoBERTa achieve similar performance as BERT, and MLM+NSP can outperform all previously proposed TAP tasks, during which we also contribute a new state-of-the-art on the Ubuntu corpus. Additional analyses shows that the main source of improvements comes from the TAP step, and that the NSP task is crucial to DRS, different from common NLU tasks.
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
Aug 03, 2022


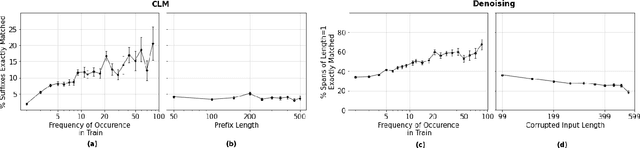
In this work, we demonstrate that multilingual large-scale sequence-to-sequence (seq2seq) models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various tasks. In particular, we train a 20 billion parameter multilingual seq2seq model called Alexa Teacher Model (AlexaTM 20B) and show that it achieves state-of-the-art (SOTA) performance on 1-shot summarization tasks, outperforming a much larger 540B PaLM decoder model. AlexaTM 20B also achieves SOTA in 1-shot machine translation, especially for low-resource languages, across almost all language pairs supported by the model (Arabic, English, French, German, Hindi, Italian, Japanese, Marathi, Portuguese, Spanish, Tamil, and Telugu) on Flores-101 dataset. We also show in zero-shot setting, AlexaTM 20B outperforms GPT3 (175B) on SuperGLUE and SQuADv2 datasets and provides SOTA performance on multilingual tasks such as XNLI, XCOPA, Paws-X, and XWinograd. Overall, our results present a compelling case for seq2seq models as a powerful alternative to decoder-only models for Large-scale Language Model (LLM) training.
Learning to Ask Like a Physician
Jun 06, 2022
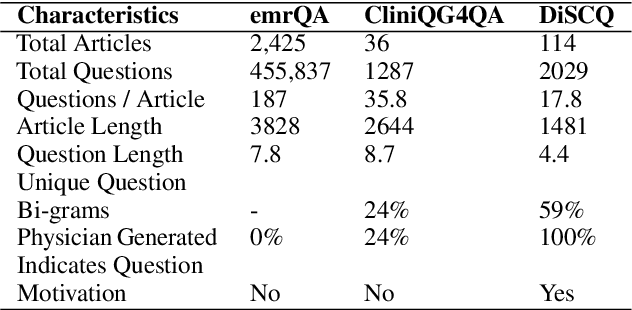

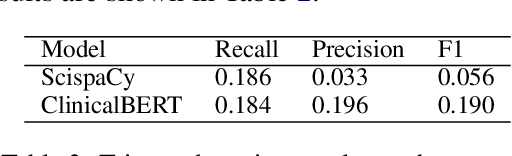
Existing question answering (QA) datasets derived from electronic health records (EHR) are artificially generated and consequently fail to capture realistic physician information needs. We present Discharge Summary Clinical Questions (DiSCQ), a newly curated question dataset composed of 2,000+ questions paired with the snippets of text (triggers) that prompted each question. The questions are generated by medical experts from 100+ MIMIC-III discharge summaries. We analyze this dataset to characterize the types of information sought by medical experts. We also train baseline models for trigger detection and question generation (QG), paired with unsupervised answer retrieval over EHRs. Our baseline model is able to generate high quality questions in over 62% of cases when prompted with human selected triggers. We release this dataset (and all code to reproduce baseline model results) to facilitate further research into realistic clinical QA and QG: https://github.com/elehman16/discq.
Life after BERT: What do Other Muppets Understand about Language?
May 21, 2022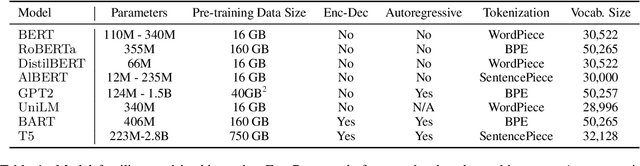
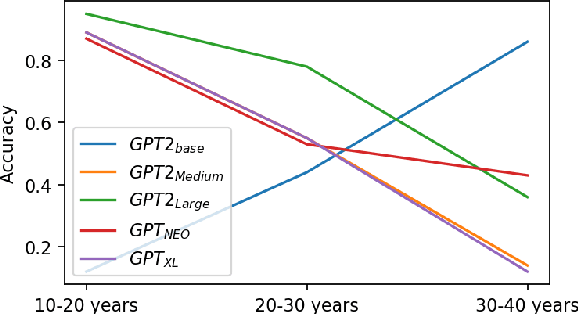

Existing pre-trained transformer analysis works usually focus only on one or two model families at a time, overlooking the variability of the architecture and pre-training objectives. In our work, we utilize the oLMpics benchmark and psycholinguistic probing datasets for a diverse set of 29 models including T5, BART, and ALBERT. Additionally, we adapt the oLMpics zero-shot setup for autoregressive models and evaluate GPT networks of different sizes. Our findings show that none of these models can resolve compositional questions in a zero-shot fashion, suggesting that this skill is not learnable using existing pre-training objectives. Furthermore, we find that global model decisions such as architecture, directionality, size of the dataset, and pre-training objective are not predictive of a model's linguistic capabilities.
Down and Across: Introducing Crossword-Solving as a New NLP Benchmark
May 20, 2022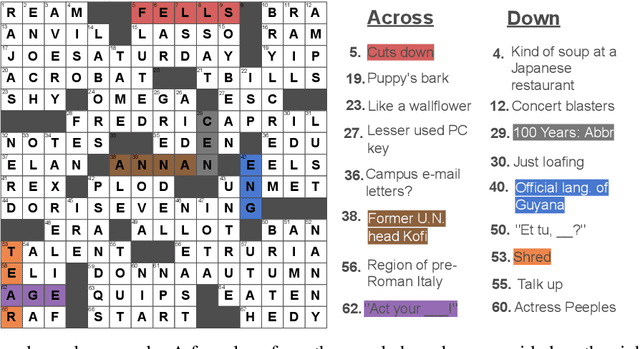
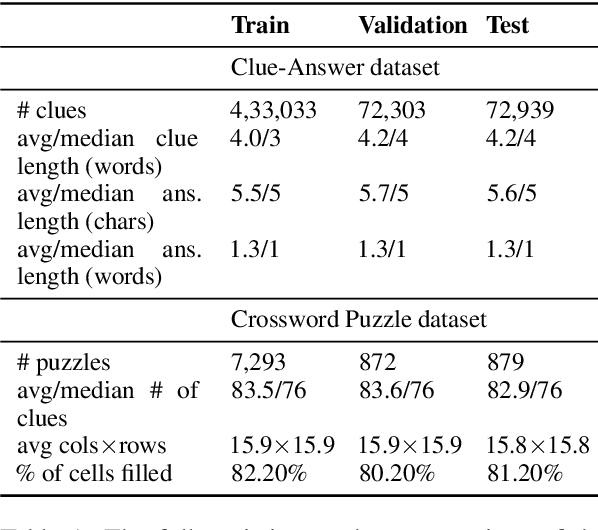
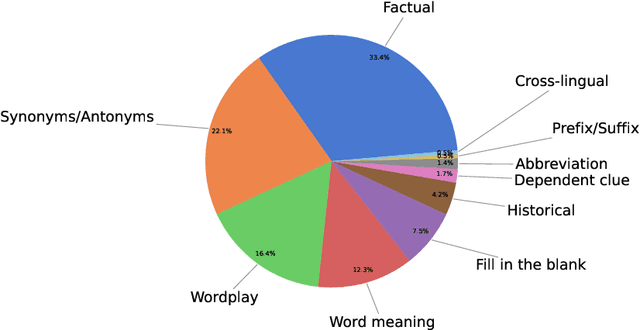

Solving crossword puzzles requires diverse reasoning capabilities, access to a vast amount of knowledge about language and the world, and the ability to satisfy the constraints imposed by the structure of the puzzle. In this work, we introduce solving crossword puzzles as a new natural language understanding task. We release the specification of a corpus of crossword puzzles collected from the New York Times daily crossword spanning 25 years and comprised of a total of around nine thousand puzzles. These puzzles include a diverse set of clues: historic, factual, word meaning, synonyms/antonyms, fill-in-the-blank, abbreviations, prefixes/suffixes, wordplay, and cross-lingual, as well as clues that depend on the answers to other clues. We separately release the clue-answer pairs from these puzzles as an open-domain question answering dataset containing over half a million unique clue-answer pairs. For the question answering task, our baselines include several sequence-to-sequence and retrieval-based generative models. We also introduce a non-parametric constraint satisfaction baseline for solving the entire crossword puzzle. Finally, we propose an evaluation framework which consists of several complementary performance metrics.
Federated Learning with Noisy User Feedback
May 06, 2022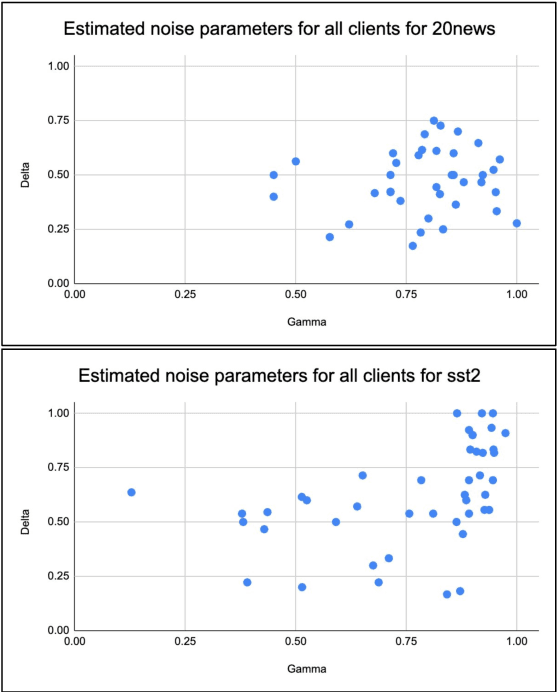
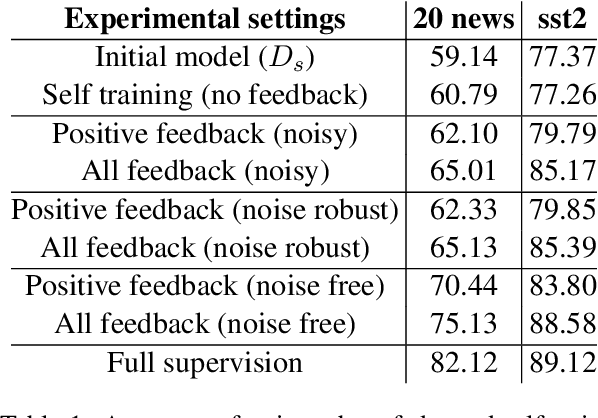
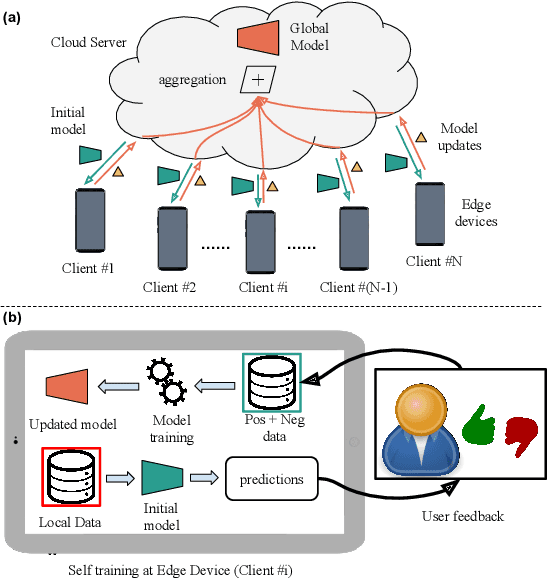
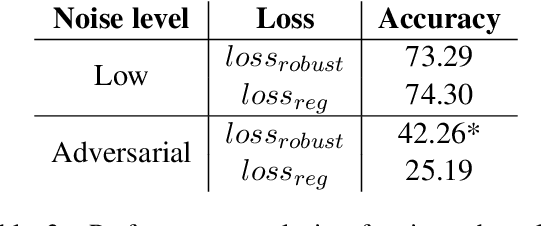
Machine Learning (ML) systems are getting increasingly popular, and drive more and more applications and services in our daily life. This has led to growing concerns over user privacy, since human interaction data typically needs to be transmitted to the cloud in order to train and improve such systems. Federated learning (FL) has recently emerged as a method for training ML models on edge devices using sensitive user data and is seen as a way to mitigate concerns over data privacy. However, since ML models are most commonly trained with label supervision, we need a way to extract labels on edge to make FL viable. In this work, we propose a strategy for training FL models using positive and negative user feedback. We also design a novel framework to study different noise patterns in user feedback, and explore how well standard noise-robust objectives can help mitigate this noise when training models in a federated setting. We evaluate our proposed training setup through detailed experiments on two text classification datasets and analyze the effects of varying levels of user reliability and feedback noise on model performance. We show that our method improves substantially over a self-training baseline, achieving performance closer to models trained with full supervision.
Multi-Stream Transformers
Jul 21, 2021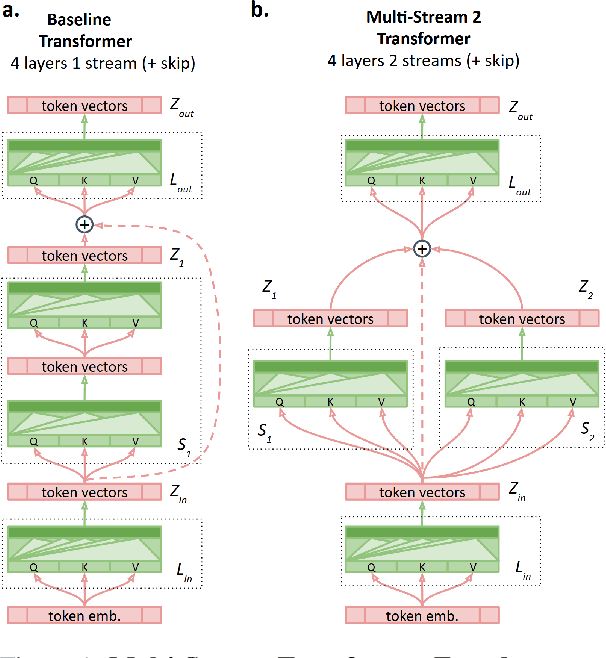

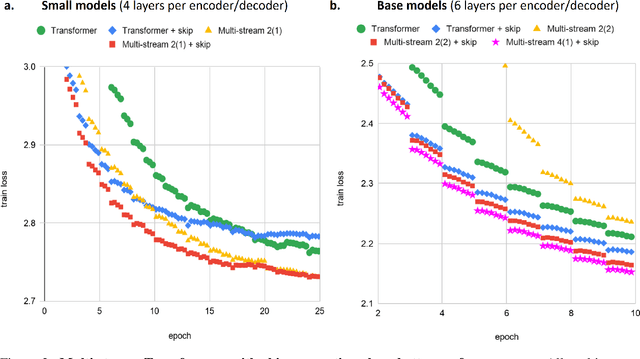
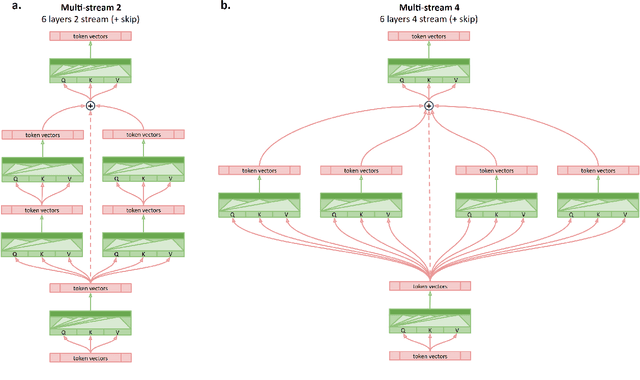
Transformer-based encoder-decoder models produce a fused token-wise representation after every encoder layer. We investigate the effects of allowing the encoder to preserve and explore alternative hypotheses, combined at the end of the encoding process. To that end, we design and examine a $\textit{Multi-stream Transformer}$ architecture and find that splitting the Transformer encoder into multiple encoder streams and allowing the model to merge multiple representational hypotheses improves performance, with further improvement obtained by adding a skip connection between the first and the final encoder layer.