 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Aware Multi-Sentence Video Description
Aug 22, 2020
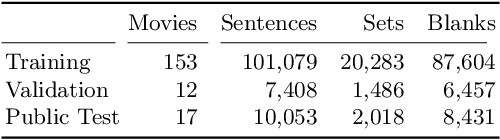


Standard video and movie description tasks abstract away from person identities, thus failing to link identities across sentences. We propose a multi-sentence Identity-Aware Video Description task, which overcomes this limitation and requires to re-identify persons locally within a set of consecutive clips. We introduce an auxiliary task of Fill-in the Identity, that aims to predict persons' IDs consistently within a set of clips, when the video descriptions are given. Our proposed approach to this task leverages a Transformer architecture allowing for coherent joint prediction of multiple IDs. One of the key components is a gender-aware textual representation as well an additional gender prediction objective in the main model. This auxiliary task allows us to propose a two-stage approach to Identity-Aware Video Description. We first generate multi-sentence video descriptions, and then apply our Fill-in the Identity model to establish links between the predicted person entities. To be able to tackle both tasks, we augment the Large Scale Movie Description Challenge (LSMDC) benchmark with new annotations suited for our problem statement. Experiments show that our proposed Fill-in the Identity model is superior to several baselines and recent works, and allows us to generate descriptions with locally re-identified people.
Are You Looking? Grounding to Multiple Modalities in Vision-and-Language Navigation
Jun 10, 2019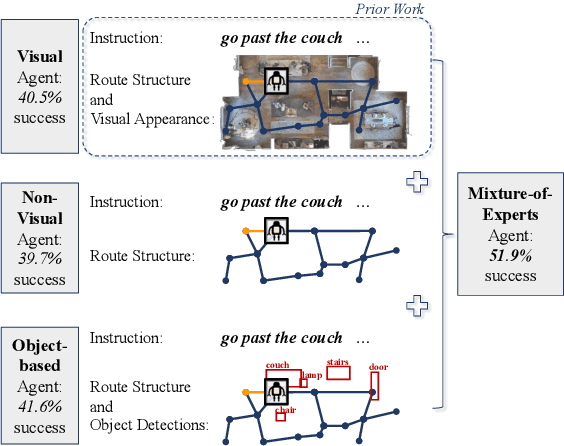
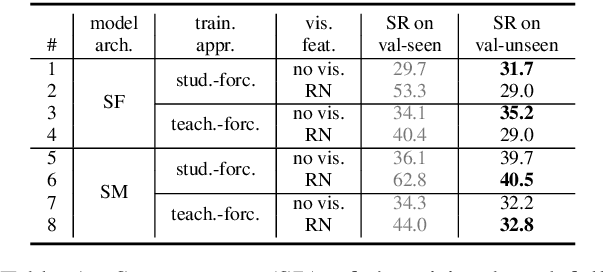
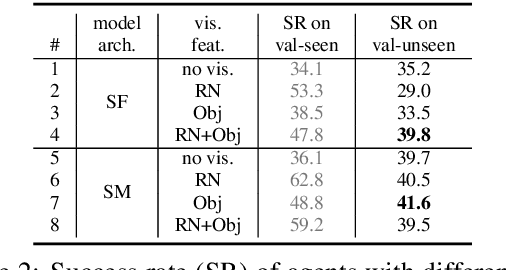
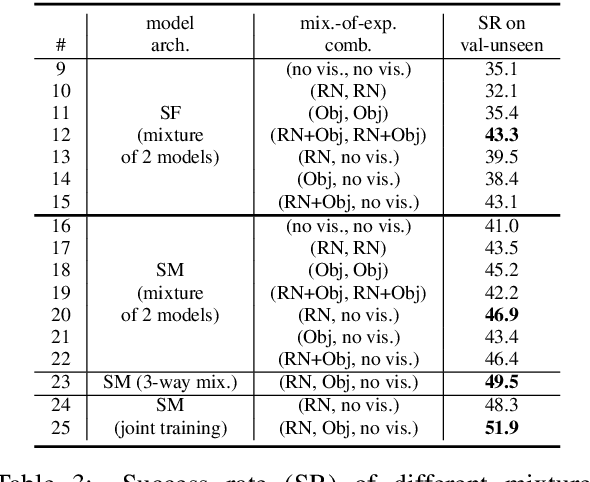
Vision-and-Language Navigation (VLN) requires grounding instructions, such as "turn right and stop at the door", to routes in a visual environment. The actual grounding can connect language to the environment through multiple modalities, e.g. "stop at the door" might ground into visual objects, while "turn right" might rely only on the geometric structure of a route. We investigate where the natural language empirically grounds under two recent state-of-the-art VLN models. Surprisingly, we discover that visual features may actually hurt these models: models which only use route structure, ablating visual features, outperform their visual counterparts in unseen new environments on the benchmark Room-to-Room dataset. To better use all the available modalities, we propose to decompose the grounding procedure into a set of expert models with access to different modalities (including object detections) and ensemble them at prediction time, improving the performance of state-of-the-art models on the VLN task.
Language-Conditioned Graph Networks for Relational Reasoning
May 10, 2019
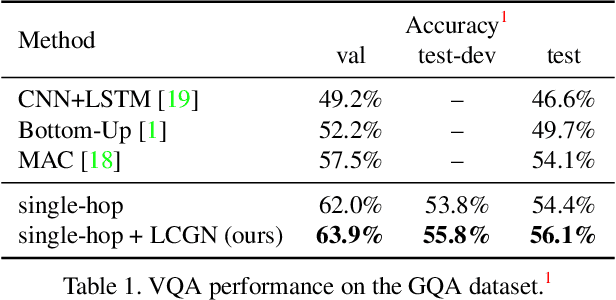
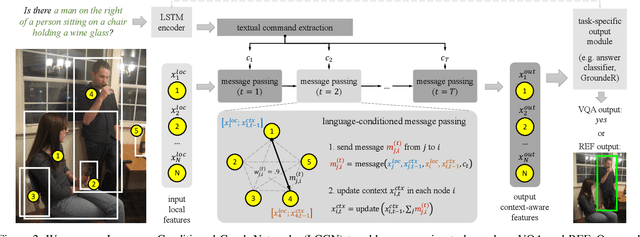
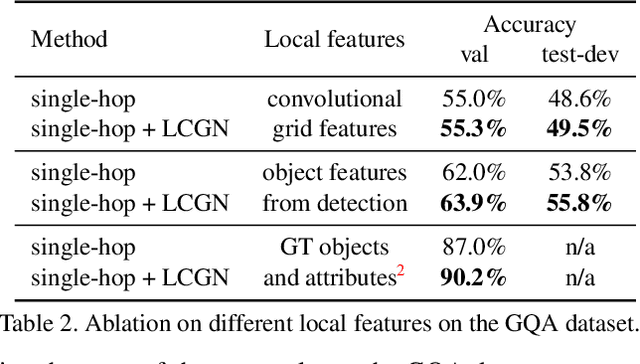
Solving grounded language tasks often requires reasoning about relationships between objects in the context of a given task. For example, to answer the question ``What color is the mug on the plate?'' we must check the color of the specific mug that satisfies the ``on'' relationship with respect to the plate. Recent work has proposed various methods capable of complex relational reasoning. However, most of their power is in the inference structure, while the scene is represented with simple local appearance features. In this paper, we take an alternate approach and build contextualized representations for objects in a visual scene to support relational reasoning. We propose a general framework of Language-Conditioned Graph Networks (LCGN), where each node represents an object, and is described by a context-aware representation from related objects through iterative message passing conditioned on the textual input. E.g., conditioning on the ``on'' relationship to the plate, the object ``mug'' gathers messages from the object ``plate'' to update its representation to ``mug on the plate'', which can be easily consumed by a simple classifier for answer prediction. We experimentally show that our LCGN approach effectively supports relational reasoning and improves performance across several tasks and datasets.
Viewpoint Invariant Change Captioning
Jan 08, 2019
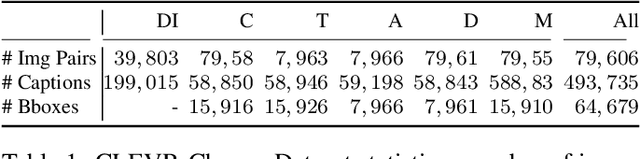
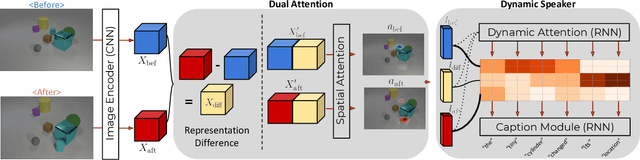
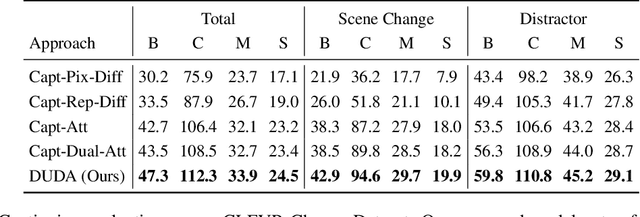
The ability to detect that something has changed in an environment is valuable, but often only if it can be accurately conveyed to a human operator. We introduce Viewpoint Invariant Change Captioning, and develop models which can both localize and describe via natural language complex changes in an environment. Moreover, we distinguish between a change in a viewpoint and an actual scene change (e.g. a change of objects' attributes). To study this new problem, we collect a Viewpoint Invariant Change Captioning Dataset (VICC), building it off the CLEVR dataset and engine. We introduce 5 types of scene changes, including changes in attributes, positions, etc. To tackle this problem, we propose an approach that distinguishes a viewpoint change from an important scene change, localizes the change between "before" and "after" images, and dynamically attends to the relevant visual features when describing the change. We benchmark a number of baselines on our new dataset, and systematically study the different change types. We show the superiority of our proposed approach in terms of change captioning and localization. Finally, we also show that our approach is general and can be applied to real images and language on the recent Spot-the-diff dataset.
Adversarial Inference for Multi-Sentence Video Description
Dec 13, 2018
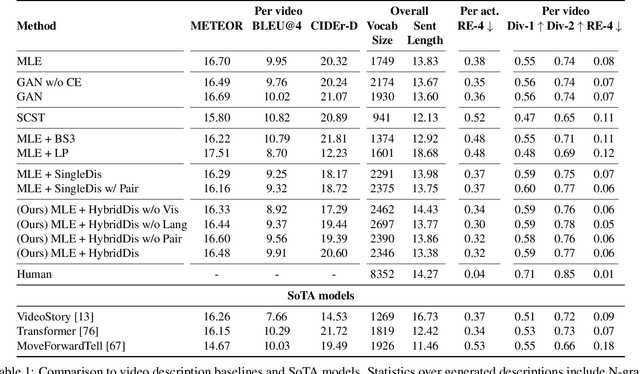
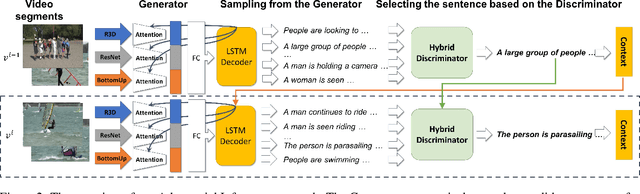
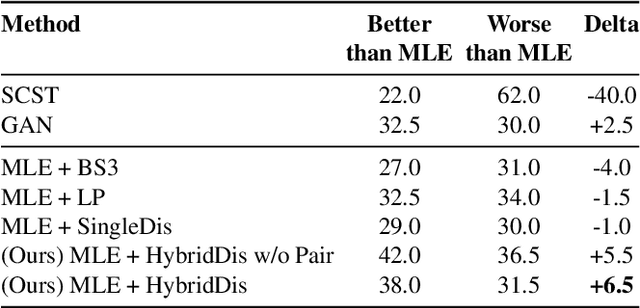
While significant progress has been made in the image captioning task, video description is still comparatively in its infancy, due to the complex nature of video data. Generating multi-sentence descriptions for long videos is even more challenging. Among the main issues are the fluency and coherence of the generated descriptions, and their relevance to the video. Recently, reinforcement and adversarial learning based methods have been explored to improve the image captioning models; however, both types of methods suffer from a number of issues, e.g. poor readability and high redundancy for RL and stability issues for GANs. In this work, we instead propose to apply adversarial techniques during inference, designing a discriminator which encourages better multi-sentence video description. In addition, we find that a multi-discriminator "hybrid" design, where each discriminator targets one aspect of a description, leads to the best results. Specifically, we decouple the discriminator to evaluate on three criteria: 1) visual relevance to the video, 2) language diversity and fluency, and 3) coherence across sentences. Our approach results in more accurate, diverse and coherent multi-sentence video descriptions, as shown by automatic as well as human evaluation on the popular ActivityNet Captions dataset.
Speaker-Follower Models for Vision-and-Language Navigation
Oct 27, 2018
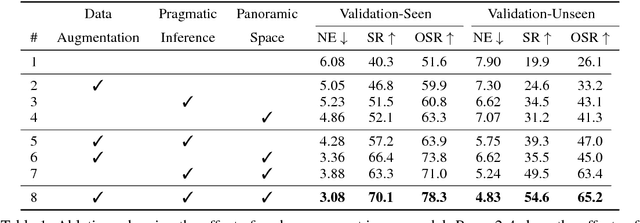
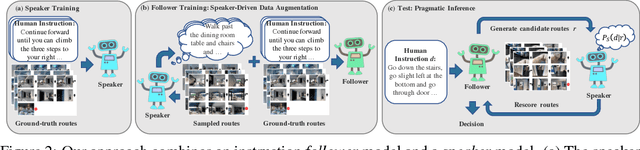
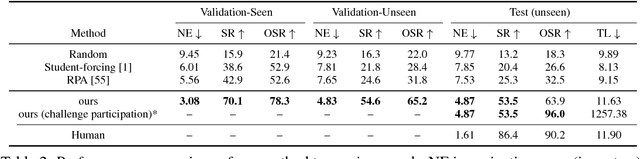
Navigation guided by natural language instructions presents a challenging reasoning problem for instruction followers. Natural language instructions typically identify only a few high-level decisions and landmarks rather than complete low-level motor behaviors; much of the missing information must be inferred based on perceptual context. In machine learning settings, this is doubly challenging: it is difficult to collect enough annotated data to enable learning of this reasoning process from scratch, and also difficult to implement the reasoning process using generic sequence models. Here we describe an approach to vision-and-language navigation that addresses both these issues with an embedded speaker model. We use this speaker model to (1) synthesize new instructions for data augmentation and to (2) implement pragmatic reasoning, which evaluates how well candidate action sequences explain an instruction. Both steps are supported by a panoramic action space that reflects the granularity of human-generated instructions. Experiments show that all three components of this approach---speaker-driven data augmentation, pragmatic reasoning and panoramic action space---dramatically improve the performance of a baseline instruction follower, more than doubling the success rate over the best existing approach on a standard benchmark.
Object Hallucination in Image Captioning
Sep 06, 2018
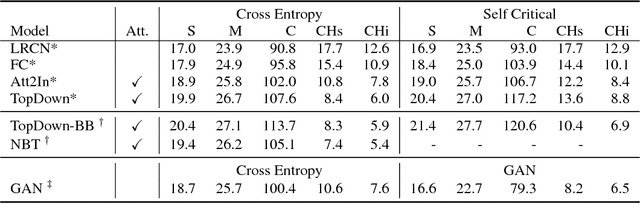

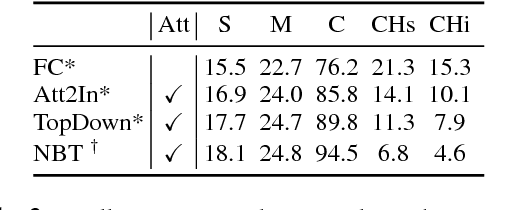
Despite continuously improving performance, contemporary image captioning models are prone to "hallucinating" objects that are not actually in a scene. One problem is that standard metrics only measure similarity to ground truth captions and may not fully capture image relevance. In this work, we propose a new image relevance metric to evaluate current models with veridical visual labels and assess their rate of object hallucination. We analyze how captioning model architectures and learning objectives contribute to object hallucination, explore when hallucination is likely due to image misclassification or language priors, and assess how well current sentence metrics capture object hallucination. We investigate these questions on the standard image caption- ing benchmark, MSCOCO, using a diverse set of models. Our analysis yields several interesting findings, including that models which score best on standard sentence metrics do not always have lower hallucination and that models which hallucinate more tend to make errors driven by language priors.
Textual Explanations for Self-Driving Vehicles
Jul 30, 2018
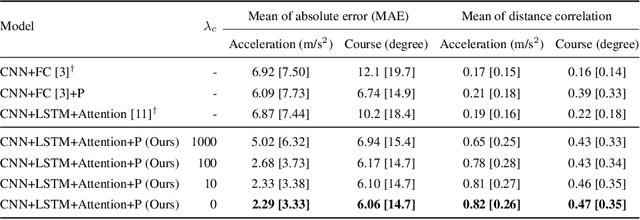
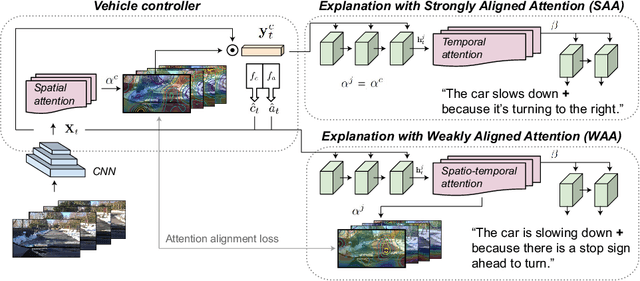
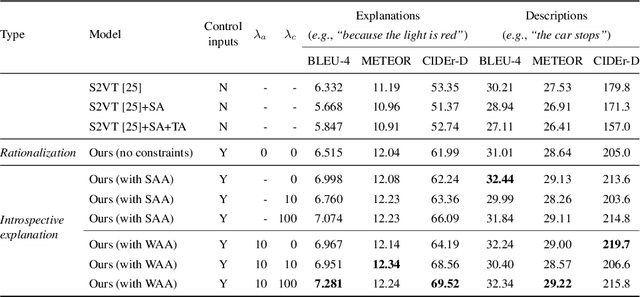
Deep neural perception and control networks have become key components of self-driving vehicles. User acceptance is likely to benefit from easy-to-interpret textual explanations which allow end-users to understand what triggered a particular behavior. Explanations may be triggered by the neural controller, namely introspective explanations, or informed by the neural controller's output, namely rationalizations. We propose a new approach to introspective explanations which consists of two parts. First, we use a visual (spatial) attention model to train a convolutional network end-to-end from images to the vehicle control commands, i.e., acceleration and change of course. The controller's attention identifies image regions that potentially influence the network's output. Second, we use an attention-based video-to-text model to produce textual explanations of model actions. The attention maps of controller and explanation model are aligned so that explanations are grounded in the parts of the scene that mattered to the controller. We explore two approaches to attention alignment, strong- and weak-alignment. Finally, we explore a version of our model that generates rationalizations, and compare with introspective explanations on the same video segments. We evaluate these models on a novel driving dataset with ground-truth human explanations, the Berkeley DeepDrive eXplanation (BDD-X) dataset. Code is available at https://github.com/JinkyuKimUCB/explainable-deep-driving.
* Accepted to ECCV 2018
Women also Snowboard: Overcoming Bias in Captioning Models (Extended Abstract)
Jul 02, 2018
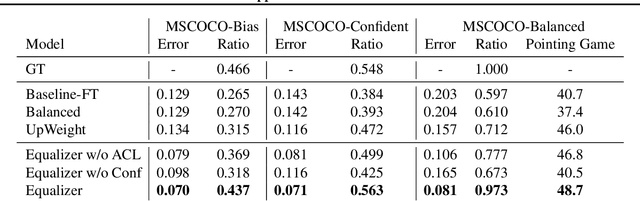
Most machine learning methods are known to capture and exploit biases of the training data. While some biases are beneficial for learning, others are harmful. Specifically, image captioning models tend to exaggerate biases present in training data. This can lead to incorrect captions in domains where unbiased captions are desired, or required, due to over reliance on the learned prior and image context. We investigate generation of gender specific caption words (e.g. man, woman) based on the person's appearance or the image context. We introduce a new Equalizer model that ensures equal gender probability when gender evidence is occluded in a scene and confident predictions when gender evidence is present. The resulting model is forced to look at a person rather than use contextual cues to make a gender specific prediction. The losses that comprise our model, the Appearance Confusion Loss and the Confident Loss, are general, and can be added to any description model in order to mitigate impacts of unwanted bias in a description dataset. Our proposed model has lower error than prior work when describing images with people and mentioning their gender and more closely matches the ground truth ratio of sentences including women to sentences including men.
Women also Snowboard: Overcoming Bias in Captioning Models
Jun 18, 2018Most machine learning methods are known to capture and exploit biases of the training data. While some biases are beneficial for learning, others are harmful. Specifically, image captioning models tend to exaggerate biases present in training data (e.g., if a word is present in 60% of training sentences, it might be predicted in 70% of sentences at test time). This can lead to incorrect captions in domains where unbiased captions are desired, or required, due to over-reliance on the learned prior and image context. In this work we investigate generation of gender-specific caption words (e.g. man, woman) based on the person's appearance or the image context. We introduce a new Equalizer model that ensures equal gender probability when gender evidence is occluded in a scene and confident predictions when gender evidence is present. The resulting model is forced to look at a person rather than use contextual cues to make a gender-specific predictions. The losses that comprise our model, the Appearance Confusion Loss and the Confident Loss, are general, and can be added to any description model in order to mitigate impacts of unwanted bias in a description dataset. Our proposed model has lower error than prior work when describing images with people and mentioning their gender and more closely matches the ground truth ratio of sentences including women to sentences including men. We also show that unlike other approaches, our model is indeed more often looking at people when predicting their gender.