 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiVQABench: A Knowledge-Grounded Visual Question Answering Benchmark from Wikipedia and Wikidata
May 20, 2026Visual Question Answering (VQA) benchmarks have largely emphasized perception-based tasks that can be solved from visual content alone. In contrast, many real-world scenarios require external knowledge that is not directly observable in the image to answer correctly. We introduce WikiVQABench, a human-curated knowledge-grounded VQA benchmark constructed by systematically combining Wikipedia images, their associated article captions, and structured knowledge from Wikidata. Our pipeline uses large language models (LLMs) to generate candidate multiple-choice image-question-answer sets. All generated instances are subsequently reviewed and curated by human annotators to ensure factual correctness, visual-text consistency, and that each question requires external knowledge in addition to visual evidence for correct resolution. WikiVQABench comprises a substantial collection of Wikipedia images with curated multiple-choice questions designed to benchmark knowledge-aware vision-language models (VLMs). Evaluation of fifteen VLMs (256M-90B parameters) reveals a wide performance range (24.7%-75.6% accuracy), demonstrating that the benchmark effectively discriminates model capabilities on knowledge-intensive reasoning. The dataset and benchmarking code are publicly available.
A Systematic Approach for Large Language Models Debugging
Apr 24, 2026Large language models (LLMs) have become central to modern AI workflows, powering applications from open-ended text generation to complex agent-based reasoning. However, debugging these models remains a persistent challenge due to their opaque and probabilistic nature and the difficulty of diagnosing errors across diverse tasks and settings. This paper introduces a systematic approach for LLM debugging that treats models as observable systems, providing structured, model-agnostic methods from issue detection to model refinement. By unifying evaluation, interpretability, and error-analysis practices, our approach enables practitioners to iteratively diagnose model weaknesses, refine prompts and model parameters, and adapt data for fine-tuning or assessment, while remaining effective in contexts where standardized benchmarks and evaluation criteria are lacking. We argue that such a structured methodology not only accelerates troubleshooting but also fosters reproducibility, transparency, and scalability in the deployment of LLM-based systems.
SAUCE: Truncated Sparse Document Signature Bit-Vectors for Fast Web-Scale Corpus Expansion
Aug 26, 2021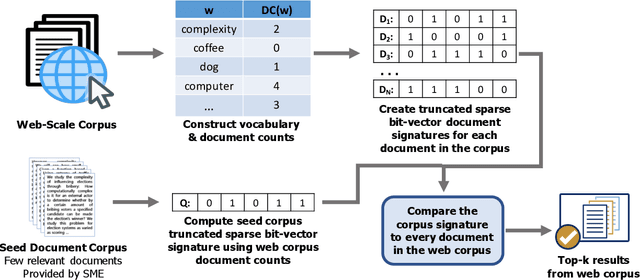
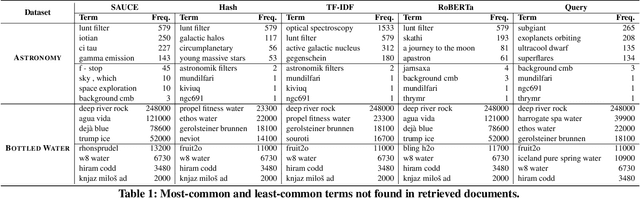
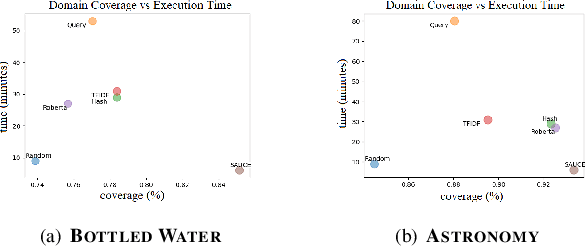
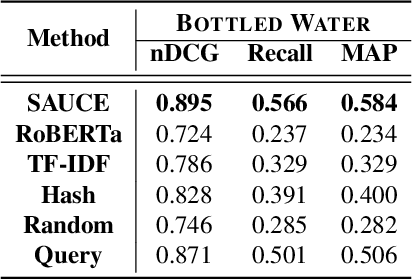
Recent advances in text representation have shown that training on large amounts of text is crucial for natural language understanding. However, models trained without predefined notions of topical interest typically require careful fine-tuning when transferred to specialized domains. When a sufficient amount of within-domain text may not be available, expanding a seed corpus of relevant documents from large-scale web data poses several challenges. First, corpus expansion requires scoring and ranking each document in the collection, an operation that can quickly become computationally expensive as the web corpora size grows. Relying on dense vector spaces and pairwise similarity adds to the computational expense. Secondly, as the domain concept becomes more nuanced, capturing the long tail of domain-specific rare terms becomes non-trivial, especially under limited seed corpora scenarios. In this paper, we consider the problem of fast approximate corpus expansion given a small seed corpus with a few relevant documents as a query, with the goal of capturing the long tail of a domain-specific set of concept terms. To efficiently collect large-scale domain-specific corpora with limited relevance feedback, we propose a novel truncated sparse document bit-vector representation, termed Signature Assisted Unsupervised Corpus Expansion (SAUCE). Experimental results show that SAUCE can reduce the computational burden while ensuring high within-domain lexical coverage.