 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Approach for Large Language Models Debugging
Apr 24, 2026Large language models (LLMs) have become central to modern AI workflows, powering applications from open-ended text generation to complex agent-based reasoning. However, debugging these models remains a persistent challenge due to their opaque and probabilistic nature and the difficulty of diagnosing errors across diverse tasks and settings. This paper introduces a systematic approach for LLM debugging that treats models as observable systems, providing structured, model-agnostic methods from issue detection to model refinement. By unifying evaluation, interpretability, and error-analysis practices, our approach enables practitioners to iteratively diagnose model weaknesses, refine prompts and model parameters, and adapt data for fine-tuning or assessment, while remaining effective in contexts where standardized benchmarks and evaluation criteria are lacking. We argue that such a structured methodology not only accelerates troubleshooting but also fosters reproducibility, transparency, and scalability in the deployment of LLM-based systems.
QnAMaker: Data to Bot in 2 Minutes
Mar 19, 2020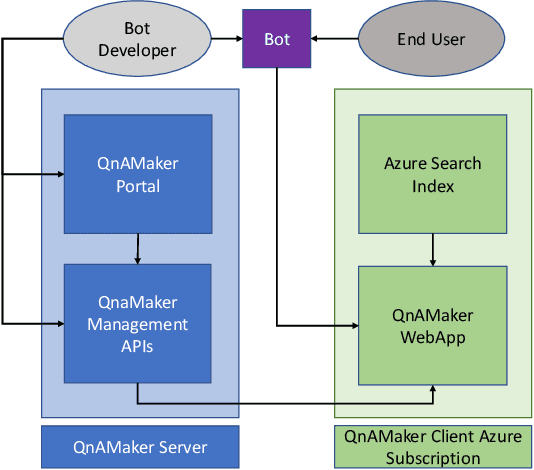
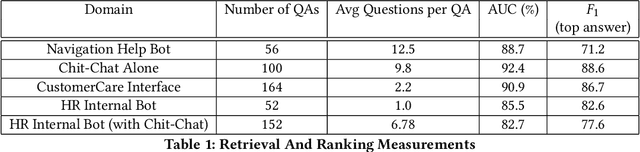
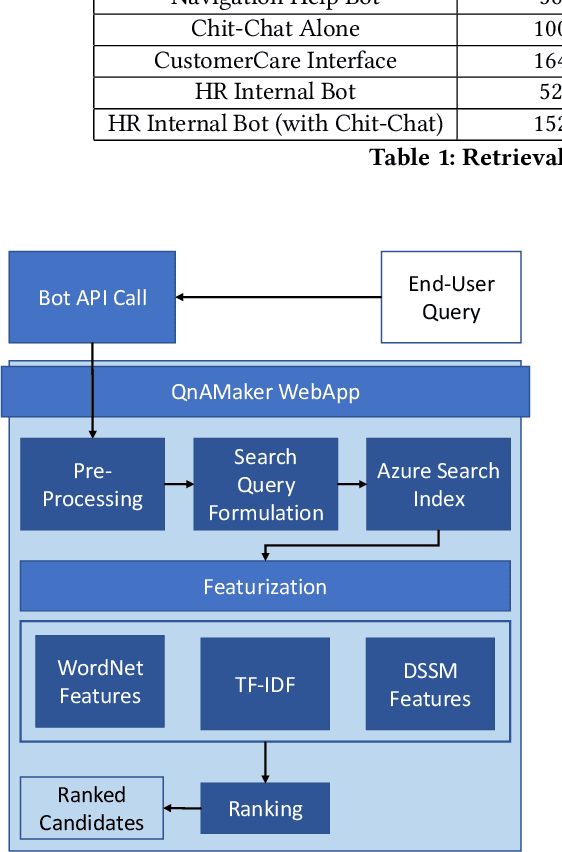
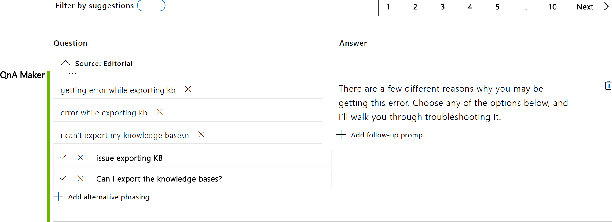
Having a bot for seamless conversations is a much-desired feature that products and services today seek for their websites and mobile apps. These bots help reduce traffic received by human support significantly by handling frequent and directly answerable known questions. Many such services have huge reference documents such as FAQ pages, which makes it hard for users to browse through this data. A conversation layer over such raw data can lower traffic to human support by a great margin. We demonstrate QnAMaker, a service that creates a conversational layer over semi-structured data such as FAQ pages, product manuals, and support documents. QnAMaker is the popular choice for Extraction and Question-Answering as a service and is used by over 15,000 bots in production. It is also used by search interfaces and not just bots.