 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation Strategies for Discriminative Speech Recognition Rescoring
Jun 15, 2023



Second-pass rescoring is employed in most state-of-the-art speech recognition systems. Recently, BERT based models have gained popularity for re-ranking the n-best hypothesis by exploiting the knowledge from masked language model pre-training. Further, fine-tuning with discriminative loss such as minimum word error rate (MWER) has shown to perform better than likelihood-based loss. Streaming applications with low latency requirements impose significant constraints on the size of the models, thereby limiting the word error rate (WER) performance gains. In this paper, we propose effective strategies for distilling from large models discriminatively trained with the MWER objective. We experiment on Librispeech and production scale internal dataset for voice-assistant. Our results demonstrate relative improvements of upto 7% WER over student models trained with MWER. We also show that the proposed distillation can reduce the WER gap between the student and the teacher by 62% upto 100%.
Streaming Speech-to-Confusion Network Speech Recognition
Jun 02, 2023



In interactive automatic speech recognition (ASR) systems, low-latency requirements limit the amount of search space that can be explored during decoding, particularly in end-to-end neural ASR. In this paper, we present a novel streaming ASR architecture that outputs a confusion network while maintaining limited latency, as needed for interactive applications. We show that 1-best results of our model are on par with a comparable RNN-T system, while the richer hypothesis set allows second-pass rescoring to achieve 10-20\% lower word error rate on the LibriSpeech task. We also show that our model outperforms a strong RNN-T baseline on a far-field voice assistant task.
Robust Acoustic and Semantic Contextual Biasing in Neural Transducers for Speech Recognition
May 09, 2023Attention-based contextual biasing approaches have shown significant improvements in the recognition of generic and/or personal rare-words in End-to-End Automatic Speech Recognition (E2E ASR) systems like neural transducers. These approaches employ cross-attention to bias the model towards specific contextual entities injected as bias-phrases to the model. Prior approaches typically relied on subword encoders for encoding the bias phrases. However, subword tokenizations are coarse and fail to capture granular pronunciation information which is crucial for biasing based on acoustic similarity. In this work, we propose to use lightweight character representations to encode fine-grained pronunciation features to improve contextual biasing guided by acoustic similarity between the audio and the contextual entities (termed acoustic biasing). We further integrate pretrained neural language model (NLM) based encoders to encode the utterance's semantic context along with contextual entities to perform biasing informed by the utterance's semantic context (termed semantic biasing). Experiments using a Conformer Transducer model on the Librispeech dataset show a 4.62% - 9.26% relative WER improvement on different biasing list sizes over the baseline contextual model when incorporating our proposed acoustic and semantic biasing approach. On a large-scale in-house dataset, we observe 7.91% relative WER improvement compared to our baseline model. On tail utterances, the improvements are even more pronounced with 36.80% and 23.40% relative WER improvements on Librispeech rare words and an in-house testset respectively.
PROCTER: PROnunciation-aware ConTextual adaptER for personalized speech recognition in neural transducers
Mar 30, 2023



End-to-End (E2E) automatic speech recognition (ASR) systems used in voice assistants often have difficulties recognizing infrequent words personalized to the user, such as names and places. Rare words often have non-trivial pronunciations, and in such cases, human knowledge in the form of a pronunciation lexicon can be useful. We propose a PROnunCiation-aware conTextual adaptER (PROCTER) that dynamically injects lexicon knowledge into an RNN-T model by adding a phonemic embedding along with a textual embedding. The experimental results show that the proposed PROCTER architecture outperforms the baseline RNN-T model by improving the word error rate (WER) by 44% and 57% when measured on personalized entities and personalized rare entities, respectively, while increasing the model size (number of trainable parameters) by only 1%. Furthermore, when evaluated in a zero-shot setting to recognize personalized device names, we observe 7% WER improvement with PROCTER, as compared to only 1% WER improvement with text-only contextual attention
On-the-fly Text Retrieval for End-to-End ASR Adaptation
Mar 20, 2023



End-to-end speech recognition models are improved by incorporating external text sources, typically by fusion with an external language model. Such language models have to be retrained whenever the corpus of interest changes. Furthermore, since they store the entire corpus in their parameters, rare words can be challenging to recall. In this work, we propose augmenting a transducer-based ASR model with a retrieval language model, which directly retrieves from an external text corpus plausible completions for a partial ASR hypothesis. These completions are then integrated into subsequent predictions by an adapter, which is trained once, so that the corpus of interest can be switched without incurring the computational overhead of retraining. Our experiments show that the proposed model significantly improves the performance of a transducer baseline on a pair of question-answering datasets. Further, it outperforms shallow fusion on recognition of named entities by about 7 relative; when the two are combined, the relative improvement increases to 13%.
USTED: Improving ASR with a Unified Speech and Text Encoder-Decoder
Feb 12, 2022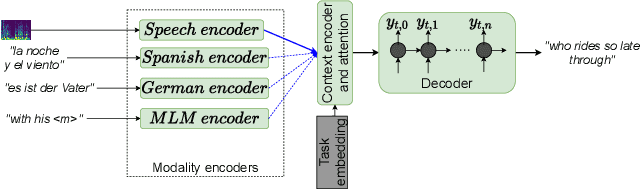
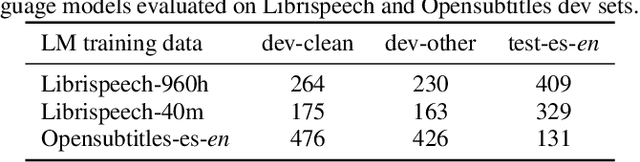
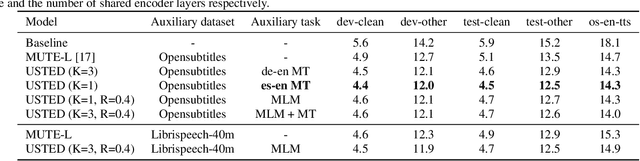
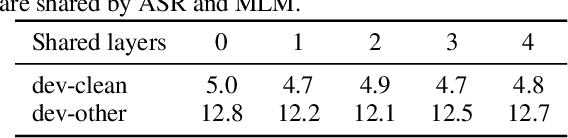
Improving end-to-end speech recognition by incorporating external text data has been a longstanding research topic. There has been a recent focus on training E2E ASR models that get the performance benefits of external text data without incurring the extra cost of evaluating an external language model at inference time. In this work, we propose training ASR model jointly with a set of text-to-text auxiliary tasks with which it shares a decoder and parts of the encoder. When we jointly train ASR and masked language model with the 960-hour Librispeech and Opensubtitles data respectively, we observe WER reductions of 16% and 20% on test-other and test-clean respectively over an ASR-only baseline without any extra cost at inference time, and reductions of 6% and 8% compared to a stronger MUTE-L baseline which trains the decoder with the same text data as our model. We achieve further improvements when we train masked language model on Librispeech data or when we use machine translation as the auxiliary task, without significantly sacrificing performance on the task itself.
RescoreBERT: Discriminative Speech Recognition Rescoring with BERT
Feb 07, 2022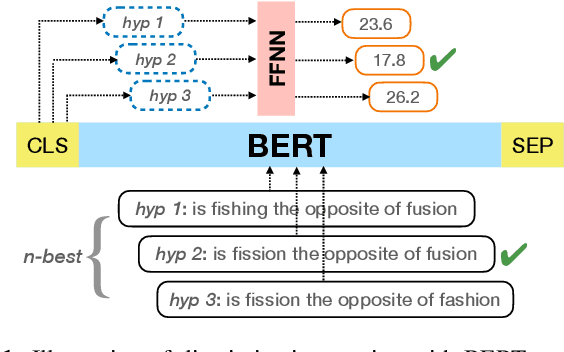
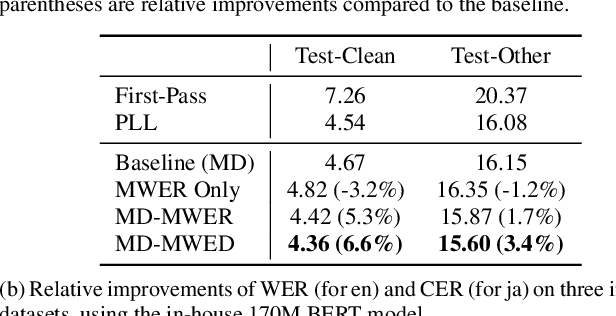

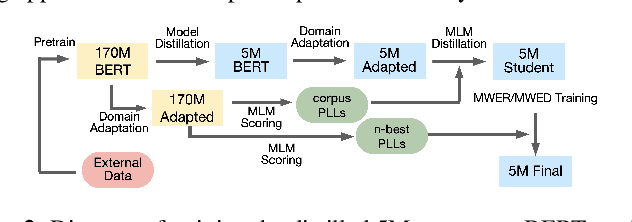
Second-pass rescoring is an important component in automatic speech recognition (ASR) systems that is used to improve the outputs from a first-pass decoder by implementing a lattice rescoring or $n$-best re-ranking. While pretraining with a masked language model (MLM) objective has received great success in various natural language understanding (NLU) tasks, it has not gained traction as a rescoring model for ASR. Specifically, training a bidirectional model like BERT on a discriminative objective such as minimum WER (MWER) has not been explored. Here we show how to train a BERT-based rescoring model with MWER loss, to incorporate the improvements of a discriminative loss into fine-tuning of deep bidirectional pretrained models for ASR. Specifically, we propose a fusion strategy that incorporates the MLM into the discriminative training process to effectively distill knowledge from a pretrained model. We further propose an alternative discriminative loss. We name this approach RescoreBERT. On the LibriSpeech corpus, it reduces WER by 6.6%/3.4% relative on clean/other test sets over a BERT baseline without discriminative objective. We also evaluate our method on an internal dataset from a conversational agent and find that it reduces both latency and WER (by 3 to 8% relative) over an LSTM rescoring model.
A Likelihood Ratio based Domain Adaptation Method for E2E Models
Jan 10, 2022


End-to-end (E2E) automatic speech recognition models like Recurrent Neural Networks Transducer (RNN-T) are becoming a popular choice for streaming ASR applications like voice assistants. While E2E models are very effective at learning representation of the training data they are trained on, their accuracy on unseen domains remains a challenging problem. Additionally, these models require paired audio and text training data, are computationally expensive and are difficult to adapt towards the fast evolving nature of conversational speech. In this work, we explore a contextual biasing approach using likelihood-ratio that leverages text data sources to adapt RNN-T model to new domains and entities. We show that this method is effective in improving rare words recognition, and results in a relative improvement of 10% in 1-best word error rate (WER) and 10% in n-best Oracle WER (n=8) on multiple out-of-domain datasets without any degradation on a general dataset. We also show that complementing the contextual biasing adaptation with adaptation of a second-pass rescoring model gives additive WER improvements.
Domain Prompts: Towards memory and compute efficient domain adaptation of ASR systems
Dec 16, 2021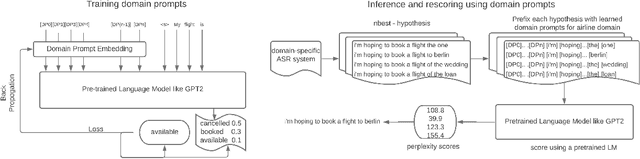

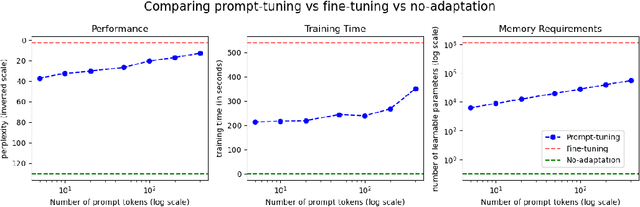
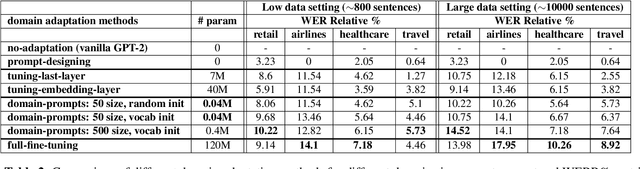
Automatic Speech Recognition (ASR) systems have found their use in numerous industrial applications in very diverse domains. Since domain-specific systems perform better than their generic counterparts on in-domain evaluation, the need for memory and compute-efficient domain adaptation is obvious. Particularly, adapting parameter-heavy transformer-based language models used for rescoring ASR hypothesis is challenging. In this work, we introduce domain-prompts, a methodology that trains a small number of domain token embedding parameters to prime a transformer-based LM to a particular domain. With just a handful of extra parameters per domain, we achieve 7-14% WER improvement over the baseline of using an unadapted LM. Despite being parameter-efficient, these improvements are comparable to those of fully-fine-tuned models with hundreds of millions of parameters. With ablations on prompt-sizes, dataset sizes, initializations and domains, we provide evidence for the benefits of using domain-prompts in ASR systems.
Lattention: Lattice-attention in ASR rescoring
Nov 19, 2021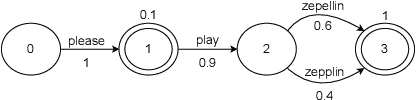
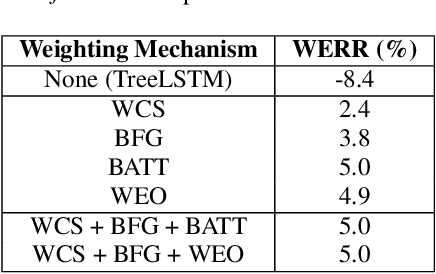
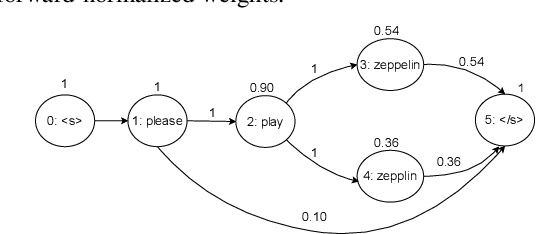
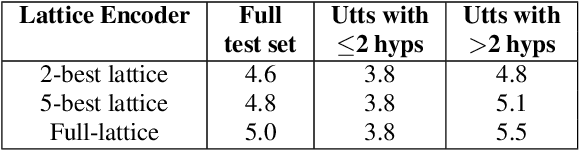
Lattices form a compact representation of multiple hypotheses generated from an automatic speech recognition system and have been shown to improve performance of downstream tasks like spoken language understanding and speech translation, compared to using one-best hypothesis. In this work, we look into the effectiveness of lattice cues for rescoring n-best lists in second-pass. We encode lattices with a recurrent network and train an attention encoder-decoder model for n-best rescoring. The rescoring model with attention to lattices achieves 4-5% relative word error rate reduction over first-pass and 6-8% with attention to both lattices and acoustic features. We show that rescoring models with attention to lattices outperform models with attention to n-best hypotheses. We also study different ways to incorporate lattice weights in the lattice encoder and demonstrate their importance for n-best rescoring.