 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Logic Imitation: Learning Plan-Satisficing Motion Policies from Demonstrations
Jun 09, 2022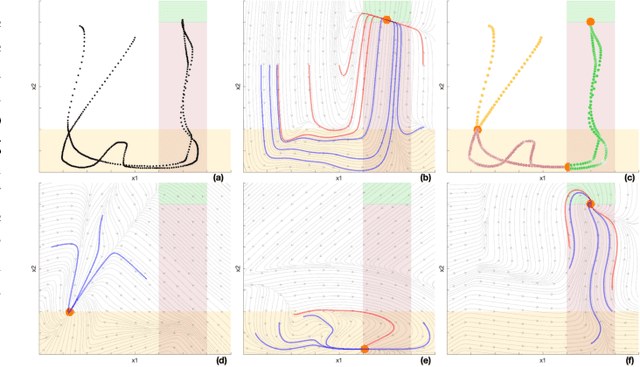
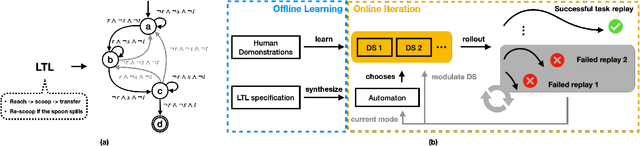
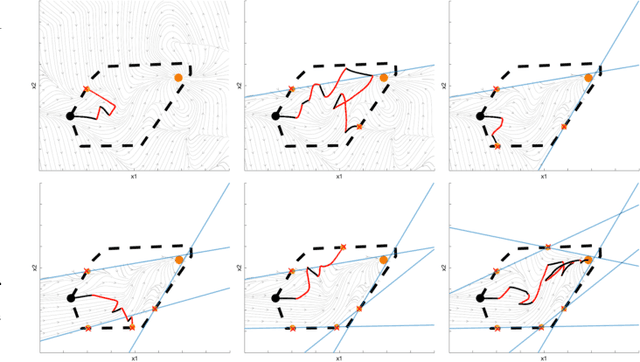
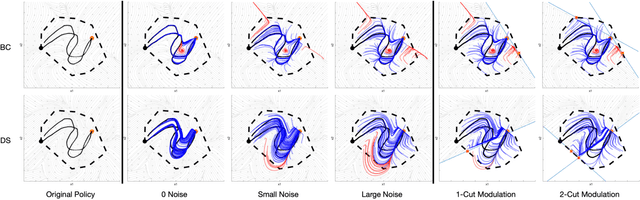
Learning from demonstration (LfD) methods have shown promise for solving multi-step tasks; however, these approaches do not guarantee successful reproduction of the task given disturbances. In this work, we identify the roots of such a challenge as the failure of the learned continuous policy to satisfy the discrete plan implicit in the demonstration. By utilizing modes (rather than subgoals) as the discrete abstraction and motion policies with both mode invariance and goal reachability properties, we prove our learned continuous policy can simulate any discrete plan specified by a Linear Temporal Logic (LTL) formula. Consequently, the imitator is robust to both task- and motion-level disturbances and guaranteed to achieve task success. Project page: https://sites.google.com/view/ltl-ds
Financial Time Series Data Augmentation with Generative Adversarial Networks and Extended Intertemporal Return Plots
May 19, 2022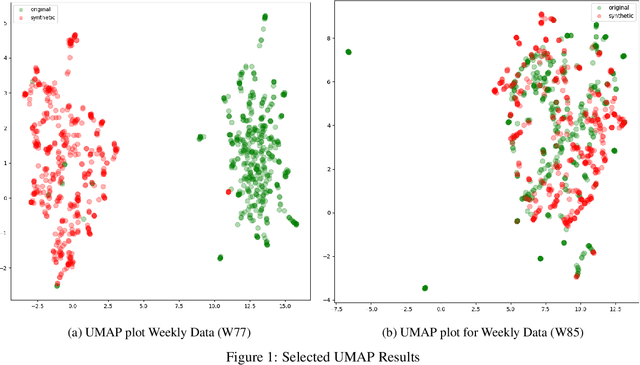
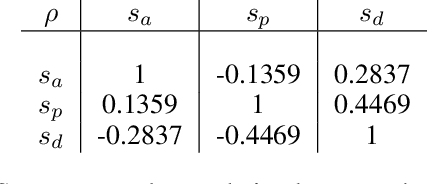
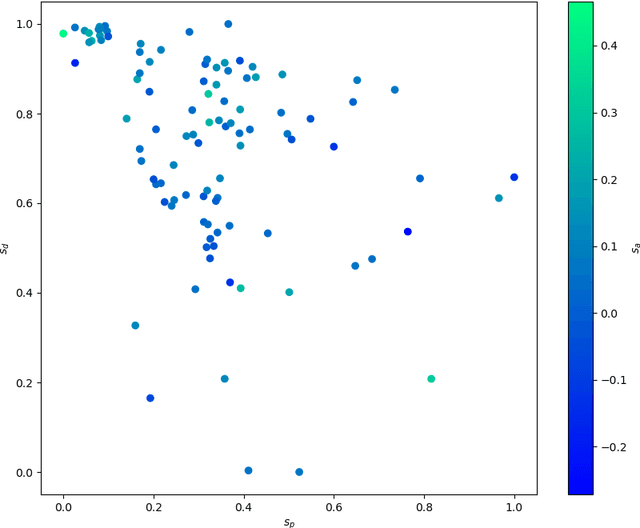
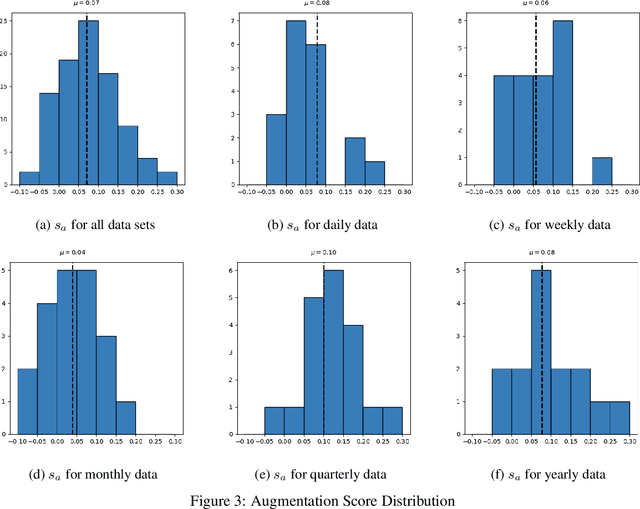
Data augmentation is a key regularization method to support the forecast and classification performance of highly parameterized models in computer vision. In the time series domain however, regularization in terms of augmentation is not equally common even though these methods have proven to mitigate effects from small sample size or non-stationarity. In this paper we apply state-of-the art image-based generative models for the task of data augmentation and introduce the extended intertemporal return plot (XIRP), a new image representation for time series. Multiple tests are conducted to assess the quality of the augmentation technique regarding its ability to synthesize time series effectively and improve forecast results on a subset of the M4 competition. We further investigate the relationship between data set characteristics and sampling results via Shapley values for feature attribution on the performance metrics and the optimal ratio of augmented data. Over all data sets, our approach proves to be effective in reducing the return forecast error by 7% on 79% of the financial data sets with varying statistical properties and frequencies.
On the pragmatism of using binary classifiers over data intensive neural network classifiers for detection of COVID-19 from voice
Apr 11, 2022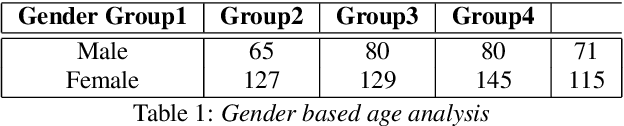
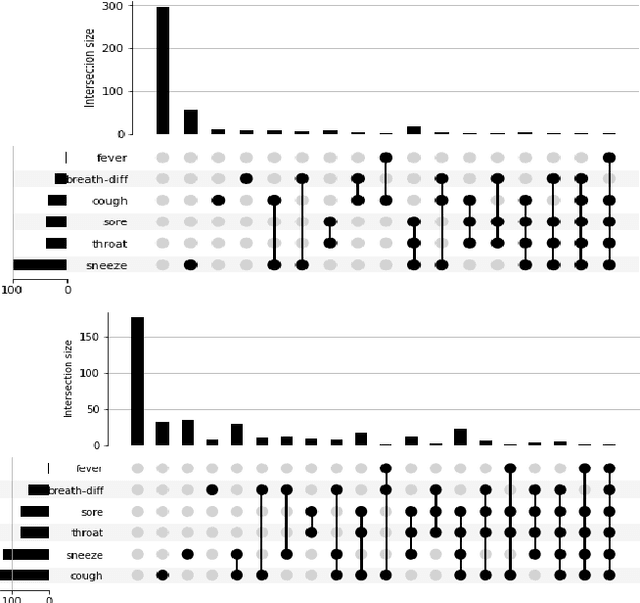
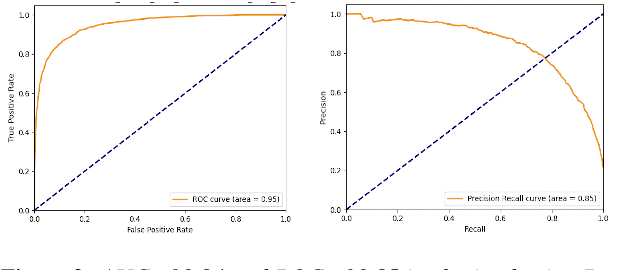

Lately, there has been a global effort by multiple research groups to detect COVID-19 from voice. Different researchers use different kinds of information from the voice signal to achieve this. Various types of phonated sounds and the sound of cough and breath have all been used with varying degrees of success in automated voice-based COVID-19 detection apps. In this paper, we show that detecting COVID-19 from voice does not require custom-made non-standard features or complicated neural network classifiers rather it can be successfully done with just standard features and simple binary classifiers. In fact, we show that the latter is not only more accurate and interpretable and also more computationally efficient in that they can be run locally on small devices. We demonstrate this from a human-curated dataset collected and calibrated in clinical settings. On this dataset which comprises over 1000 speakers, a simple binary classifier is able to achieve 94% detection accuracy.
Ontological Learning from Weak Labels
Mar 04, 2022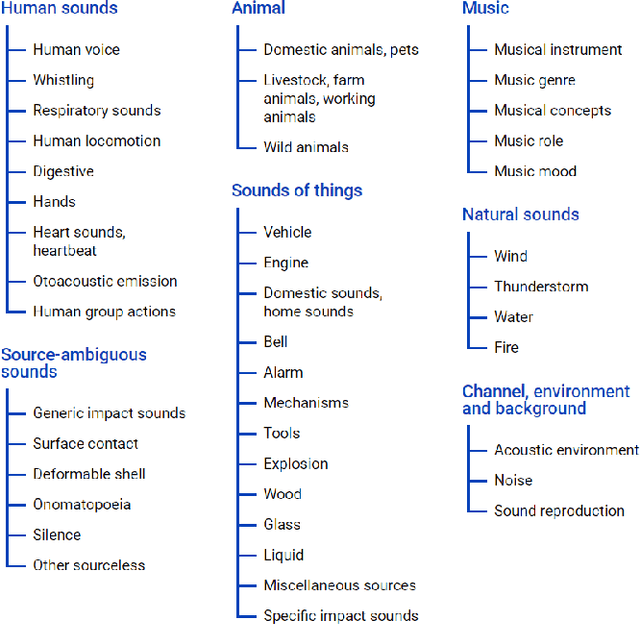


Ontologies encompass a formal representation of knowledge through the definition of concepts or properties of a domain, and the relationships between those concepts. In this work, we seek to investigate whether using this ontological information will improve learning from weakly labeled data, which are easier to collect since it requires only the presence or absence of an event to be known. We use the AudioSet ontology and dataset, which contains audio clips weakly labeled with the ontology concepts and the ontology providing the "Is A" relations between the concepts. We first re-implemented the model proposed by soundevent_ontology with modification to fit the multi-label scenario and then expand on that idea by using a Graph Convolutional Network (GCN) to model the ontology information to learn the concepts. We find that the baseline Siamese does not perform better by incorporating ontology information in the weak and multi-label scenario, but that the GCN does capture the ontology knowledge better for weak, multi-labeled data. In our experiments, we also investigate how different modules can tolerate noises introduced from weak labels and better incorporate ontology information. Our best Siamese-GCN model achieves mAP=0.45 and AUC=0.87 for lower-level concepts and mAP=0.72 and AUC=0.86 for higher-level concepts, which is an improvement over the baseline Siamese but about the same as our models that do not use ontology information.
An Overview of Techniques for Biomarker Discovery in Voice Signal
Oct 10, 2021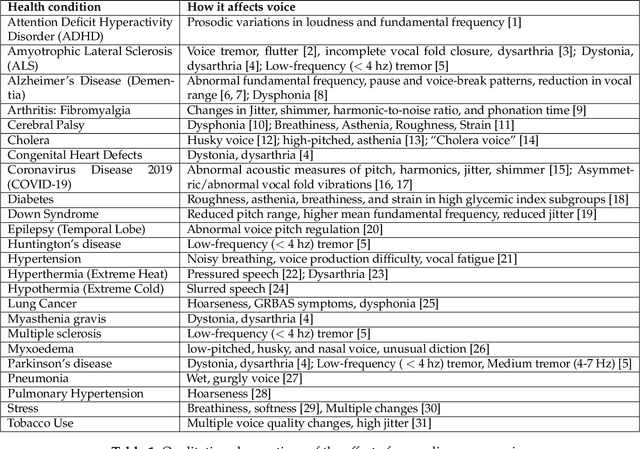

This paper reflects on the effect of several categories of medical conditions on human voice, focusing on those that may be hypothesized to have effects on voice, but for which the changes themselves may be subtle enough to have eluded observation in standard analytical examinations of the voice signal. It presents three categories of techniques that can potentially uncover such elusive biomarkers and allow them to be measured and used for predictive and diagnostic purposes. These approaches include proxy techniques, model-based analytical techniques and data-driven AI techniques.
Supervised Bayesian Specification Inference from Demonstrations
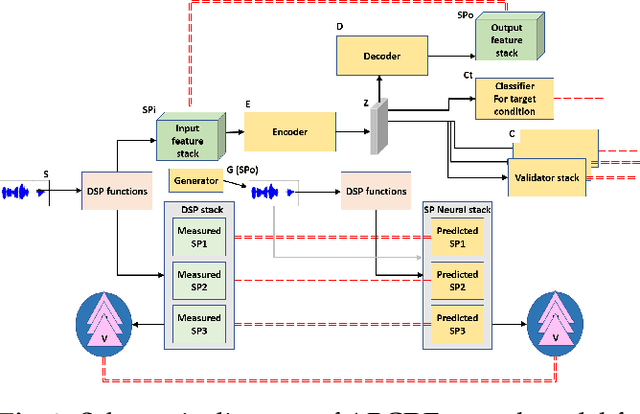
Jul 06, 2021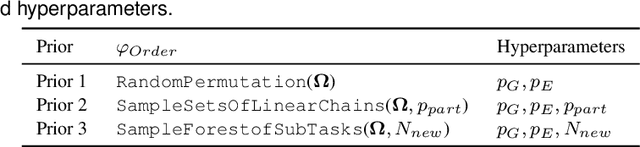
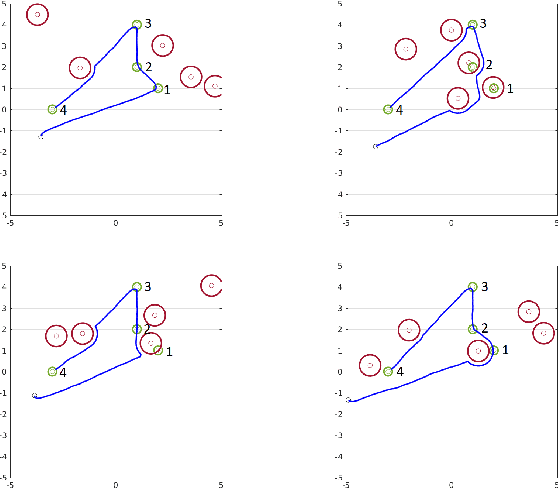
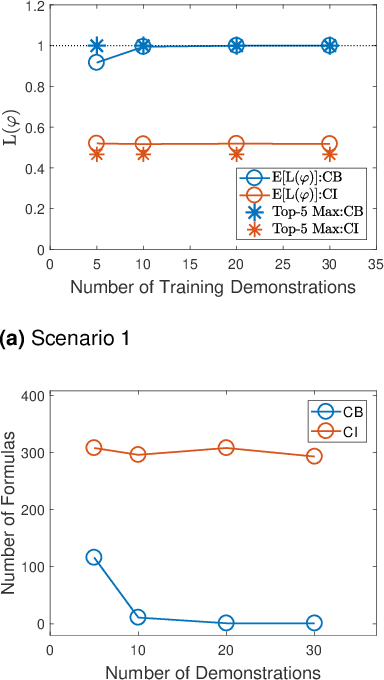
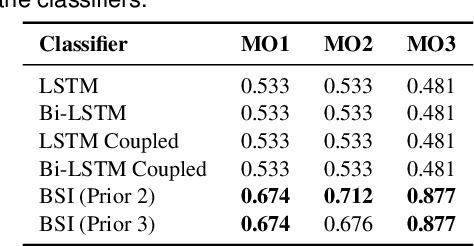
When observing task demonstrations, human apprentices are able to identify whether a given task is executed correctly long before they gain expertise in actually performing that task. Prior research into learning from demonstrations (LfD) has failed to capture this notion of the acceptability of a task's execution; meanwhile, temporal logics provide a flexible language for expressing task specifications. Inspired by this, we present Bayesian specification inference, a probabilistic model for inferring task specification as a temporal logic formula. We incorporate methods from probabilistic programming to define our priors, along with a domain-independent likelihood function to enable sampling-based inference. We demonstrate the efficacy of our model for inferring specifications, with over 90% similarity observed between the inferred specification and the ground truth, both within a synthetic domain and during a real-world table setting task.
Feature extraction and evaluation for BioMedical Question Answering
May 28, 2021

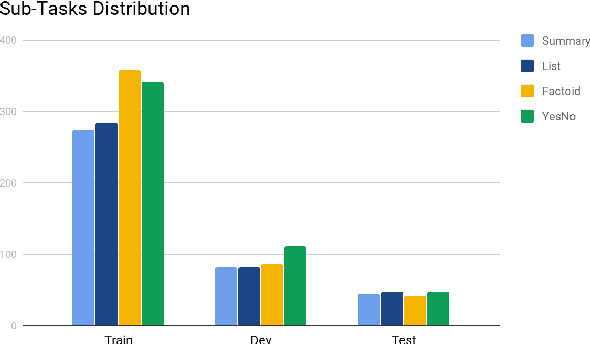
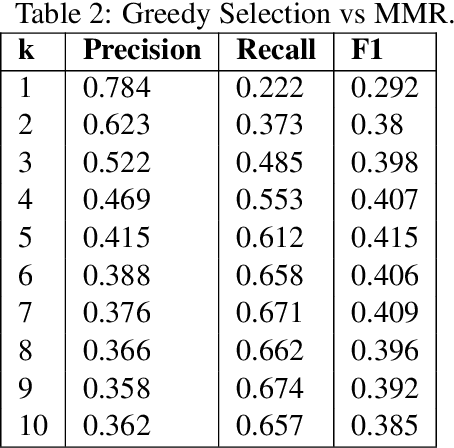
In this paper, we present our work on the BioASQ pipeline. The goal is to answer four types of questions: summary, yes/no, factoids, and list. Our goal is to empirically evaluate different modules involved: the feature extractor and the sentence selection block. We used our pipeline to test the effectiveness of each module for all kinds of question types and perform error analysis. We defined metrics that are useful for future research related to the BioASQ pipeline critical to improve the performance of the training pipeline.
Training image classifiers using Semi-Weak Label Data
Mar 19, 2021

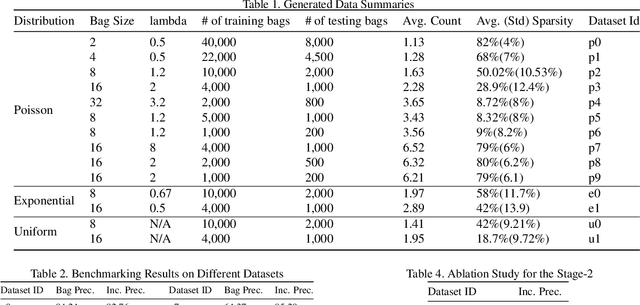

In Multiple Instance learning (MIL), weak labels are provided at the bag level with only presence/absence information known. However, there is a considerable gap in performance in comparison to a fully supervised model, limiting the practical applicability of MIL approaches. Thus, this paper introduces a novel semi-weak label learning paradigm as a middle ground to mitigate the problem. We define semi-weak label data as data where we know the presence or absence of a given class and the exact count of each class as opposed to knowing the label proportions. We then propose a two-stage framework to address the problem of learning from semi-weak labels. It leverages the fact that counting information is non-negative and discrete. Experiments are conducted on generated samples from CIFAR-10. We compare our model with a fully-supervised setting baseline, a weakly-supervised setting baseline and learning from pro-portion (LLP) baseline. Our framework not only outperforms both baseline models for MIL-based weakly super-vised setting and learning from proportion setting, but also gives comparable results compared to the fully supervised model. Further, we conduct thorough ablation studies to analyze across datasets and variation with batch size, losses architectural changes, bag size and regularization
A Reinforcement Learning Approach for Rebalancing Electric Vehicle Sharing Systems
Oct 05, 2020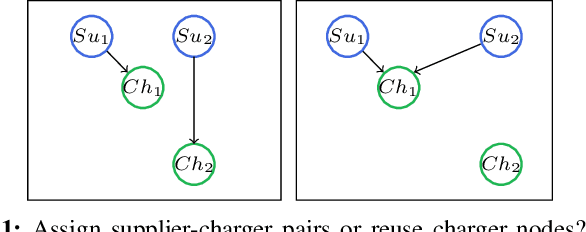
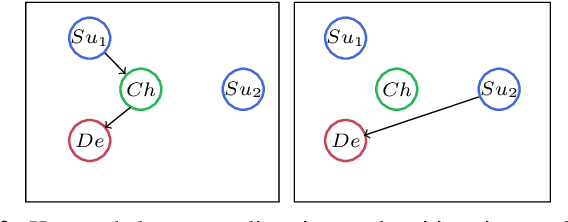
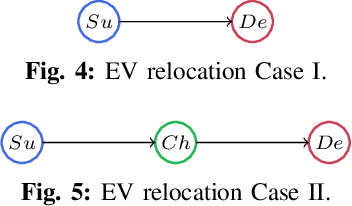
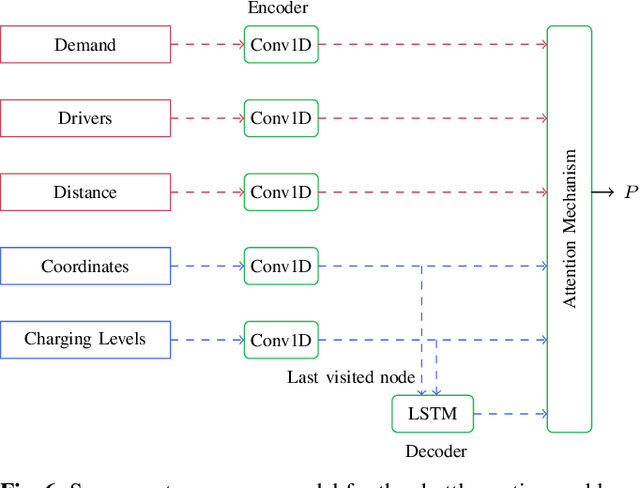
This paper proposes a reinforcement learning approach for nightly offline rebalancing operations in free-floating electric vehicle sharing systems (FFEVSS). Due to sparse demand in a network, FFEVSS require relocation of electrical vehicles (EVs) to charging stations and demander nodes, which is typically done by a group of drivers. A shuttle is used to pick up and drop off drivers throughout the network. The objective of this study is to solve the shuttle routing problem to finish the rebalancing work in the minimal time. We consider a reinforcement learning framework for the problem, in which a central controller determines the routing policies of a fleet of multiple shuttles. We deploy a policy gradient method for training recurrent neural networks and compare the obtained policy results with heuristic solutions. Our numerical studies show that unlike the existing solutions in the literature, the proposed methods allow to solve the general version of the problem with no restrictions on the urban EV network structure and charging requirements of EVs. Moreover, the learned policies offer a wide range of flexibility resulting in a significant reduction in the time needed to rebalance the network.
Interactive Robot Training for Non-Markov Tasks
Mar 04, 2020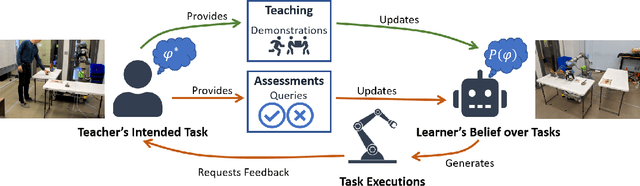
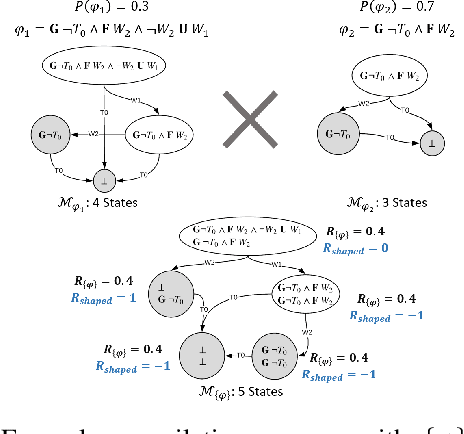
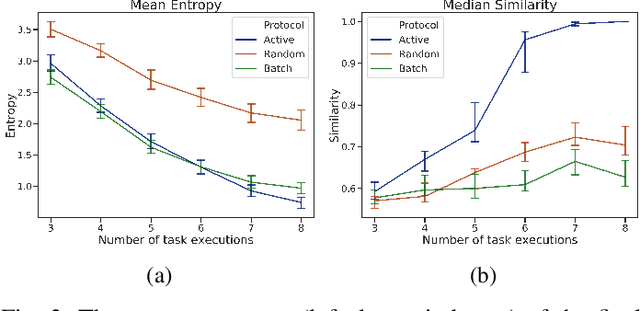

Defining sound and complete specifications for robots using formal languages is challenging, while learning formal specifications directly from demonstrations can lead to over-constrained task policies. In this paper, we propose a Bayesian interactive robot training framework that allows the robot to learn from both demonstrations provided by a teacher, and that teacher's assessments of the robot's task executions. We also present an active learning approach -- inspired by uncertainty sampling -- to identify the task execution with the most uncertain degree of acceptability. We demonstrate that active learning within our framework identifies a teacher's intended task specification to a greater degree of similarity when compared with an approach that learns purely from demonstrations. Finally, we also conduct a user-study that demonstrates the efficacy of our active learning framework in learning a table-setting task from a human teacher.