 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntoLogX: Ontology-Guided Knowledge Graph Extraction from Cybersecurity Logs with Large Language Models
Oct 01, 2025System logs represent a valuable source of Cyber Threat Intelligence (CTI), capturing attacker behaviors, exploited vulnerabilities, and traces of malicious activity. Yet their utility is often limited by lack of structure, semantic inconsistency, and fragmentation across devices and sessions. Extracting actionable CTI from logs therefore requires approaches that can reconcile noisy, heterogeneous data into coherent and interoperable representations. We introduce OntoLogX, an autonomous Artificial Intelligence (AI) agent that leverages Large Language Models (LLMs) to transform raw logs into ontology-grounded Knowledge Graphs (KGs). OntoLogX integrates a lightweight log ontology with Retrieval Augmented Generation (RAG) and iterative correction steps, ensuring that generated KGs are syntactically and semantically valid. Beyond event-level analysis, the system aggregates KGs into sessions and employs a LLM to predict MITRE ATT&CK tactics, linking low-level log evidence to higher-level adversarial objectives. We evaluate OntoLogX on both logs from a public benchmark and a real-world honeypot dataset, demonstrating robust KG generation across multiple KGs backends and accurate mapping of adversarial activity to ATT&CK tactics. Results highlight the benefits of retrieval and correction for precision and recall, the effectiveness of code-oriented models in structured log analysis, and the value of ontology-grounded representations for actionable CTI extraction.
LLMs4SchemaDiscovery: A Human-in-the-Loop Workflow for Scientific Schema Mining with Large Language Models
Apr 01, 2025



Extracting structured information from unstructured text is crucial for modeling real-world processes, but traditional schema mining relies on semi-structured data, limiting scalability. This paper introduces schema-miner, a novel tool that combines large language models with human feedback to automate and refine schema extraction. Through an iterative workflow, it organizes properties from text, incorporates expert input, and integrates domain-specific ontologies for semantic depth. Applied to materials science--specifically atomic layer deposition--schema-miner demonstrates that expert-guided LLMs generate semantically rich schemas suitable for diverse real-world applications.
Procedural Text Mining with Large Language Models
Oct 05, 2023



Recent advancements in the field of Natural Language Processing, particularly the development of large-scale language models that are pretrained on vast amounts of knowledge, are creating novel opportunities within the realm of Knowledge Engineering. In this paper, we investigate the usage of large language models (LLMs) in both zero-shot and in-context learning settings to tackle the problem of extracting procedures from unstructured PDF text in an incremental question-answering fashion. In particular, we leverage the current state-of-the-art GPT-4 (Generative Pre-trained Transformer 4) model, accompanied by two variations of in-context learning that involve an ontology with definitions of procedures and steps and a limited number of samples of few-shot learning. The findings highlight both the promise of this approach and the value of the in-context learning customisations. These modifications have the potential to significantly address the challenge of obtaining sufficient training data, a hurdle often encountered in deep learning-based Natural Language Processing techniques for procedure extraction.
Knowledge Graphs
Mar 28, 2020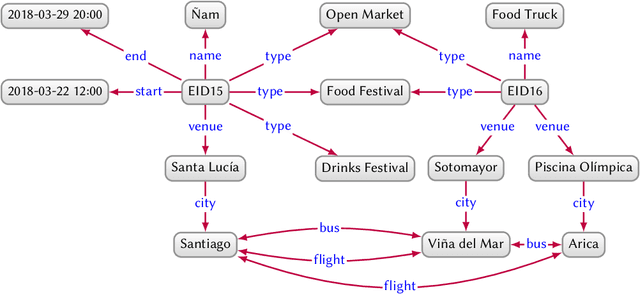
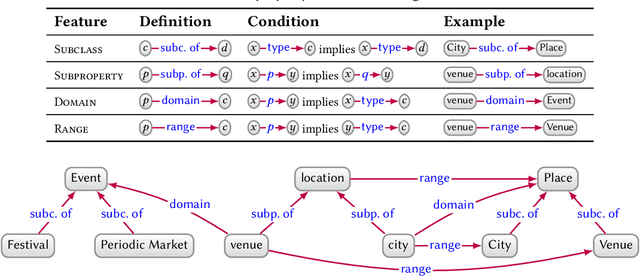
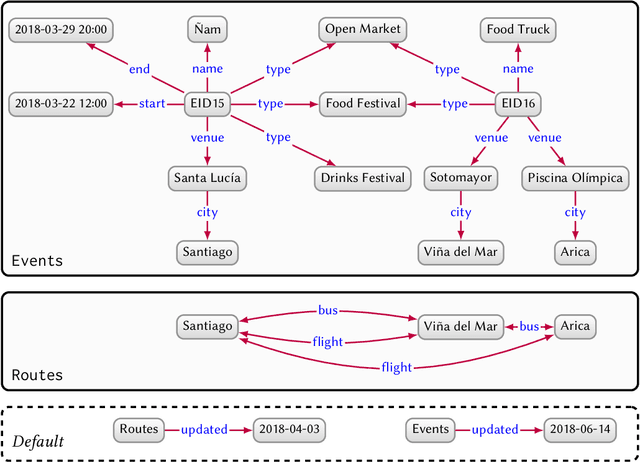
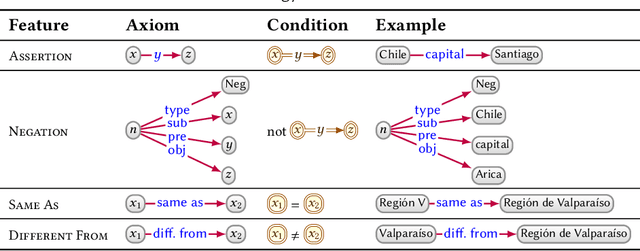
In this paper we provide a comprehensive introduction to knowledge graphs, which have recently garnered significant attention from both industry and academia in scenarios that require exploiting diverse, dynamic, large-scale collections of data. After a general introduction, we motivate and contrast various graph-based data models and query languages that are used for knowledge graphs. We discuss the roles of schema, identity, and context in knowledge graphs. We explain how knowledge can be represented and extracted using a combination of deductive and inductive techniques. We summarise methods for the creation, enrichment, quality assessment, refinement, and publication of knowledge graphs. We provide an overview of prominent open knowledge graphs and enterprise knowledge graphs, their applications, and how they use the aforementioned techniques. We conclude with high-level future research directions for knowledge graphs.