 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClipFace: Text-guided Editing of Textured 3D Morphable Models
Dec 02, 2022We propose ClipFace, a novel self-supervised approach for text-guided editing of textured 3D morphable model of faces. Specifically, we employ user-friendly language prompts to enable control of the expressions as well as appearance of 3D faces. We leverage the geometric expressiveness of 3D morphable models, which inherently possess limited controllability and texture expressivity, and develop a self-supervised generative model to jointly synthesize expressive, textured, and articulated faces in 3D. We enable high-quality texture generation for 3D faces by adversarial self-supervised training, guided by differentiable rendering against collections of real RGB images. Controllable editing and manipulation are given by language prompts to adapt texture and expression of the 3D morphable model. To this end, we propose a neural network that predicts both texture and expression latent codes of the morphable model. Our model is trained in a self-supervised fashion by exploiting differentiable rendering and losses based on a pre-trained CLIP model. Once trained, our model jointly predicts face textures in UV-space, along with expression parameters to capture both geometry and texture changes in facial expressions in a single forward pass. We further show the applicability of our method to generate temporally changing textures for a given animation sequence.
Forecasting Actions and Characteristic 3D Poses
Nov 25, 2022



We propose to model longer-term future human behavior by jointly predicting action labels and 3D characteristic poses (3D poses representative of the associated actions). While previous work has considered action and 3D pose forecasting separately, we observe that the nature of the two tasks is coupled, and thus we predict them together. Starting from an input 2D video observation, we jointly predict a future sequence of actions along with 3D poses characterizing these actions. Since coupled action labels and 3D pose annotations are difficult and expensive to acquire for videos of complex action sequences, we train our approach with action labels and 2D pose supervision from two existing action video datasets, in tandem with an adversarial loss that encourages likely 3D predicted poses. Our experiments demonstrate the complementary nature of joint action and characteristic 3D pose prediction: our joint approach outperforms each task treated individually, enables robust longer-term sequence prediction, and outperforms alternative approaches to forecast actions and characteristic 3D poses.
Learning 3D Scene Priors with 2D Supervision
Nov 25, 2022Holistic 3D scene understanding entails estimation of both layout configuration and object geometry in a 3D environment. Recent works have shown advances in 3D scene estimation from various input modalities (e.g., images, 3D scans), by leveraging 3D supervision (e.g., 3D bounding boxes or CAD models), for which collection at scale is expensive and often intractable. To address this shortcoming, we propose a new method to learn 3D scene priors of layout and shape without requiring any 3D ground truth. Instead, we rely on 2D supervision from multi-view RGB images. Our method represents a 3D scene as a latent vector, from which we can progressively decode to a sequence of objects characterized by their class categories, 3D bounding boxes, and meshes. With our trained autoregressive decoder representing the scene prior, our method facilitates many downstream applications, including scene synthesis, interpolation, and single-view reconstruction. Experiments on 3D-FRONT and ScanNet show that our method outperforms state of the art in single-view reconstruction, and achieves state-of-the-art results in scene synthesis against baselines which require for 3D supervision.
Neural Poisson: Indicator Functions for Neural Fields
Nov 25, 2022Implicit neural field generating signed distance field representations (SDFs) of 3D shapes have shown remarkable progress in 3D shape reconstruction and generation. We introduce a new paradigm for neural field representations of 3D scenes; rather than characterizing surfaces as SDFs, we propose a Poisson-inspired characterization for surfaces as indicator functions optimized by neural fields. Crucially, for reconstruction of real scan data, the indicator function representation enables simple and effective constraints based on common range sensing inputs, which indicate empty space based on line of sight. Such empty space information is intrinsic to the scanning process, and incorporating this knowledge enables more accurate surface reconstruction. We show that our approach demonstrates state-of-the-art reconstruction performance on both synthetic and real scanned 3D scene data, with 9.5% improvement in Chamfer distance over state of the art.
PatchComplete: Learning Multi-Resolution Patch Priors for 3D Shape Completion on Unseen Categories
Jun 10, 2022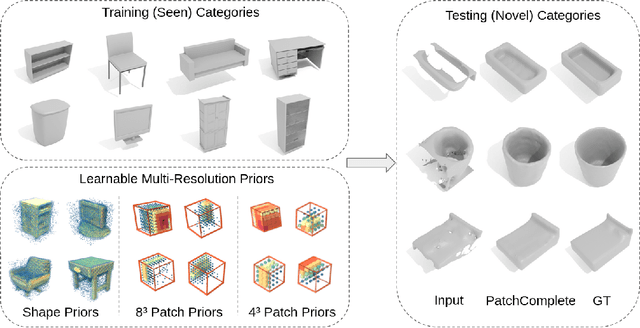
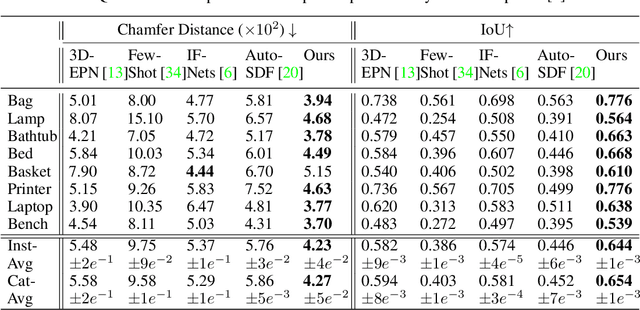
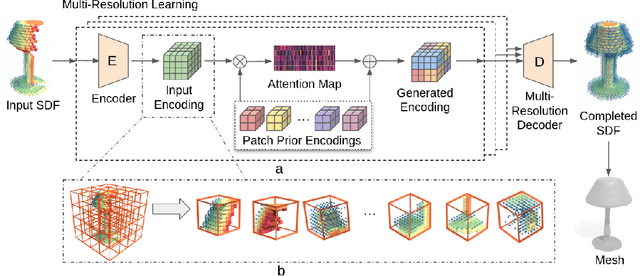
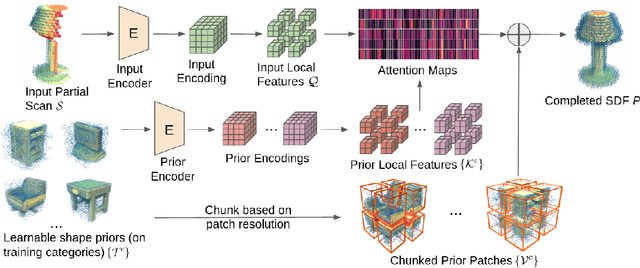
While 3D shape representations enable powerful reasoning in many visual and perception applications, learning 3D shape priors tends to be constrained to the specific categories trained on, leading to an inefficient learning process, particularly for general applications with unseen categories. Thus, we propose PatchComplete, which learns effective shape priors based on multi-resolution local patches, which are often more general than full shapes (e.g., chairs and tables often both share legs) and thus enable geometric reasoning about unseen class categories. To learn these shared substructures, we learn multi-resolution patch priors across all train categories, which are then associated to input partial shape observations by attention across the patch priors, and finally decoded into a complete shape reconstruction. Such patch-based priors avoid overfitting to specific train categories and enable reconstruction on entirely unseen categories at test time. We demonstrate the effectiveness of our approach on synthetic ShapeNet data as well as challenging real-scanned objects from ScanNet, which include noise and clutter, improving over state of the art in novel-category shape completion by 19.3% in chamfer distance on ShapeNet, and 9.0% for ScanNet.
Language-Grounded Indoor 3D Semantic Segmentation in the Wild
Apr 16, 2022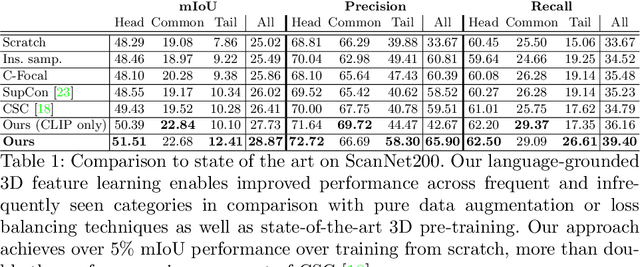
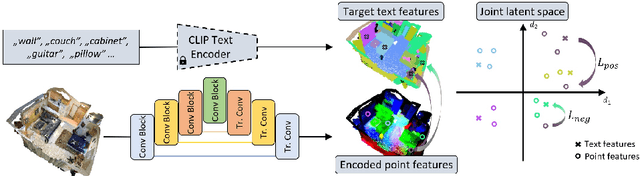
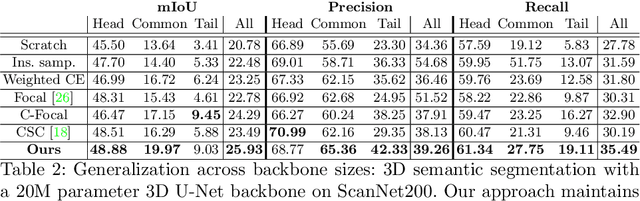
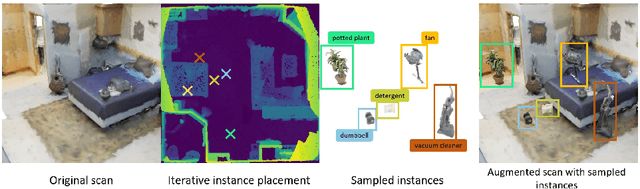
Recent advances in 3D semantic segmentation with deep neural networks have shown remarkable success, with rapid performance increase on available datasets. However, current 3D semantic segmentation benchmarks contain only a small number of categories -- less than 30 for ScanNet and SemanticKITTI, for instance, which are not enough to reflect the diversity of real environments (e.g., semantic image understanding covers hundreds to thousands of classes). Thus, we propose to study a larger vocabulary for 3D semantic segmentation with a new extended benchmark on ScanNet data with 200 class categories, an order of magnitude more than previously studied. This large number of class categories also induces a large natural class imbalance, both of which are challenging for existing 3D semantic segmentation methods. To learn more robust 3D features in this context, we propose a language-driven pre-training method to encourage learned 3D features that might have limited training examples to lie close to their pre-trained text embeddings. Extensive experiments show that our approach consistently outperforms state-of-the-art 3D pre-training for 3D semantic segmentation on our proposed benchmark (+9% relative mIoU), including limited-data scenarios with +25% relative mIoU using only 5% annotations.
Texturify: Generating Textures on 3D Shape Surfaces
Apr 05, 2022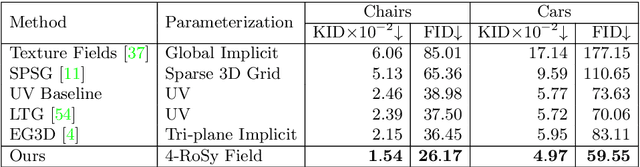
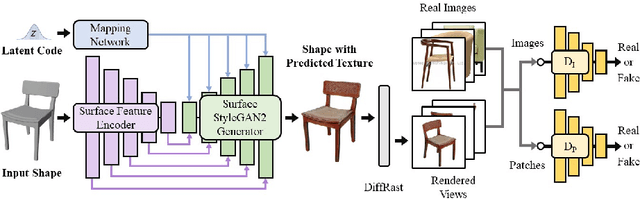

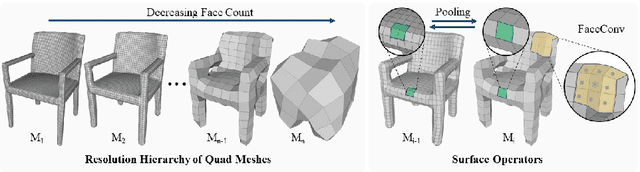
Texture cues on 3D objects are key to compelling visual representations, with the possibility to create high visual fidelity with inherent spatial consistency across different views. Since the availability of textured 3D shapes remains very limited, learning a 3D-supervised data-driven method that predicts a texture based on the 3D input is very challenging. We thus propose Texturify, a GAN-based method that leverages a 3D shape dataset of an object class and learns to reproduce the distribution of appearances observed in real images by generating high-quality textures. In particular, our method does not require any 3D color supervision or correspondence between shape geometry and images to learn the texturing of 3D objects. Texturify operates directly on the surface of the 3D objects by introducing face convolutional operators on a hierarchical 4-RoSy parametrization to generate plausible object-specific textures. Employing differentiable rendering and adversarial losses that critique individual views and consistency across views, we effectively learn the high-quality surface texturing distribution from real-world images. Experiments on car and chair shape collections show that our approach outperforms state of the art by an average of 22% in FID score.
Weakly-Supervised End-to-End CAD Retrieval to Scan Objects
Mar 24, 2022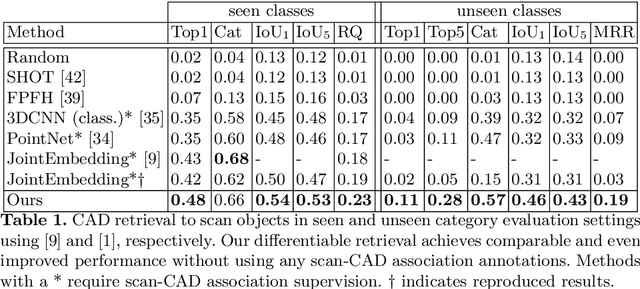
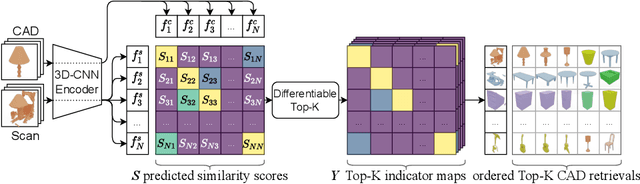
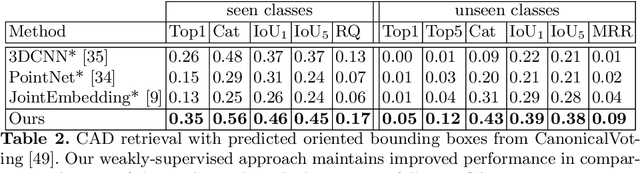
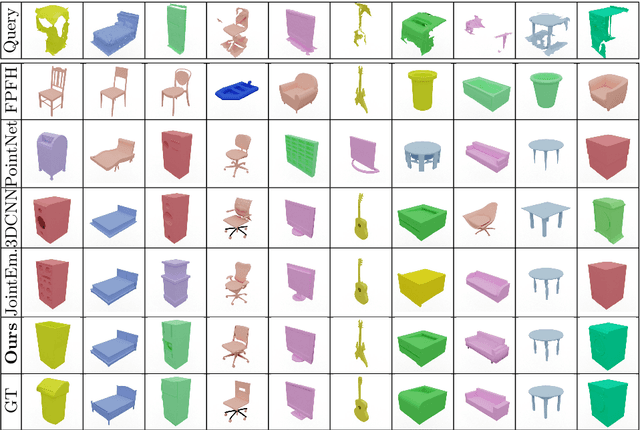
CAD model retrieval to real-world scene observations has shown strong promise as a basis for 3D perception of objects and a clean, lightweight mesh-based scene representation; however, current approaches to retrieve CAD models to a query scan rely on expensive manual annotations of 1:1 associations of CAD-scan objects, which typically contain strong lower-level geometric differences. We thus propose a new weakly-supervised approach to retrieve semantically and structurally similar CAD models to a query 3D scanned scene without requiring any CAD-scan associations, and only object detection information as oriented bounding boxes. Our approach leverages a fully-differentiable top-$k$ retrieval layer, enabling end-to-end training guided by geometric and perceptual similarity of the top retrieved CAD models to the scan queries. We demonstrate that our weakly-supervised approach can outperform fully-supervised retrieval methods on challenging real-world ScanNet scans, and maintain robustness for unseen class categories, achieving significantly improved performance over fully-supervised state of the art in zero-shot CAD retrieval.
Neural Part Priors: Learning to Optimize Part-Based Object Completion in RGB-D Scans
Mar 17, 2022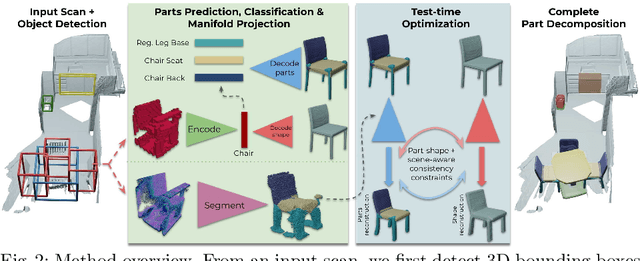
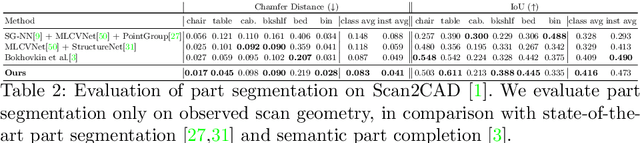
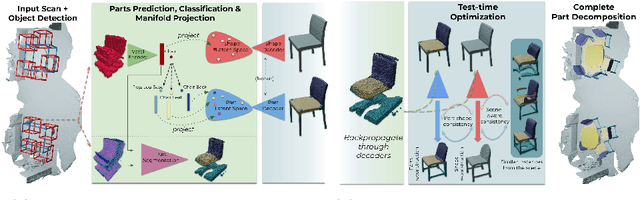
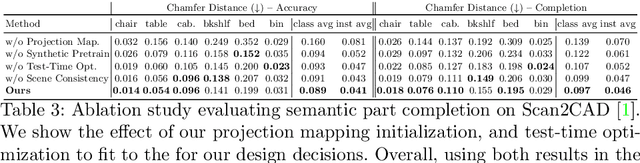
3D object recognition has seen significant advances in recent years, showing impressive performance on real-world 3D scan benchmarks, but lacking in object part reasoning, which is fundamental to higher-level scene understanding such as inter-object similarities or object functionality. Thus, we propose to leverage large-scale synthetic datasets of 3D shapes annotated with part information to learn Neural Part Priors (NPPs), optimizable spaces characterizing geometric part priors. Crucially, we can optimize over the learned part priors in order to fit to real-world scanned 3D scenes at test time, enabling robust part decomposition of the real objects in these scenes that also estimates the complete geometry of the object while fitting accurately to the observed real geometry. Moreover, this enables global optimization over geometrically similar detected objects in a scene, which often share strong geometric commonalities, enabling scene-consistent part decompositions. Experiments on the ScanNet dataset demonstrate that NPPs significantly outperforms state of the art in part decomposition and object completion in real-world scenes.
SPAMs: Structured Implicit Parametric Models
Jan 20, 2022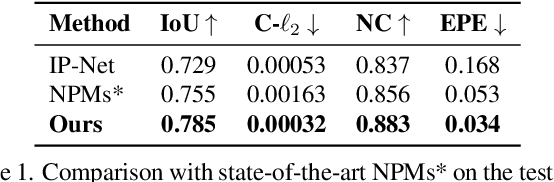
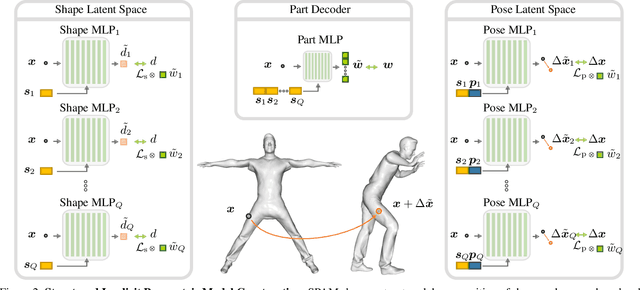
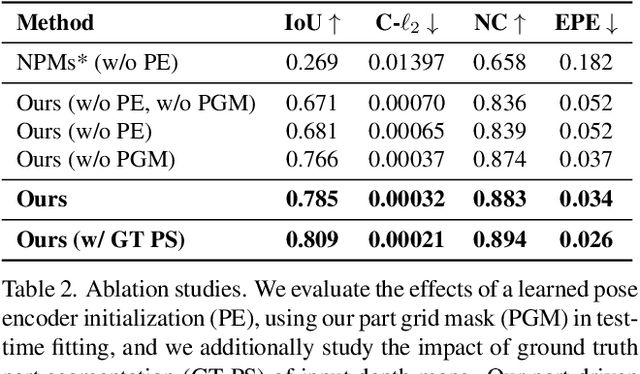

Parametric 3D models have formed a fundamental role in modeling deformable objects, such as human bodies, faces, and hands; however, the construction of such parametric models requires significant manual intervention and domain expertise. Recently, neural implicit 3D representations have shown great expressibility in capturing 3D shape geometry. We observe that deformable object motion is often semantically structured, and thus propose to learn Structured-implicit PArametric Models (SPAMs) as a deformable object representation that structurally decomposes non-rigid object motion into part-based disentangled representations of shape and pose, with each being represented by deep implicit functions. This enables a structured characterization of object movement, with part decomposition characterizing a lower-dimensional space in which we can establish coarse motion correspondence. In particular, we can leverage the part decompositions at test time to fit to new depth sequences of unobserved shapes, by establishing part correspondences between the input observation and our learned part spaces; this guides a robust joint optimization between the shape and pose of all parts, even under dramatic motion sequences. Experiments demonstrate that our part-aware shape and pose understanding lead to state-of-the-art performance in reconstruction and tracking of depth sequences of complex deforming object motion. We plan to release models to the public at https://pablopalafox.github.io/spams.