 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCount, Crop and Recognise: Fine-Grained Recognition in the Wild
Oct 09, 2019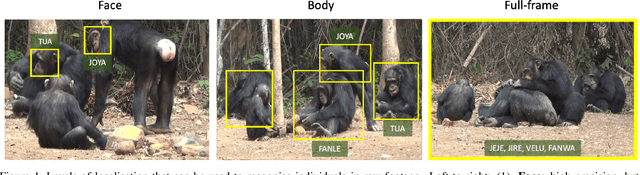
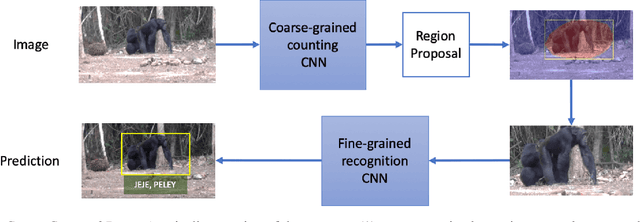


The goal of this paper is to label all the animal individuals present in every frame of a video. Unlike previous methods that have principally concentrated on labelling face tracks, we aim to label individuals even when their faces are not visible. We make the following contributions: (i) we introduce a 'Count, Crop and Recognise' (CCR) multistage recognition process for frame level labelling. The Count and Recognise stages involve specialised CNNs for the task, and we show that this simple staging gives a substantial boost in performance; (ii) we compare the recall using frame based labelling to both face and body track based labelling, and demonstrate the advantage of frame based with CCR for the specified goal; (iii) we introduce a new dataset for chimpanzee recognition in the wild; and (iv) we apply a high-granularity visualisation technique to further understand the learned CNN features for the recognition of chimpanzee individuals.
Video Representation Learning by Dense Predictive Coding
Sep 27, 2019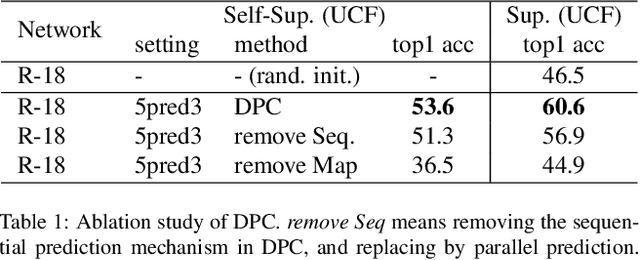
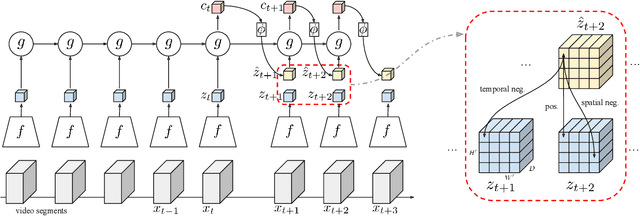

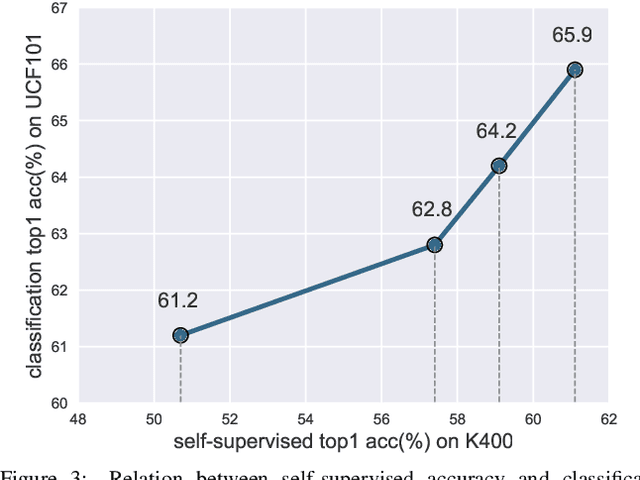
The objective of this paper is self-supervised learning of spatio-temporal embeddings from video, suitable for human action recognition. We make three contributions: First, we introduce the Dense Predictive Coding (DPC) framework for self-supervised representation learning on videos. This learns a dense encoding of spatio-temporal blocks by recurrently predicting future representations; Second, we propose a curriculum training scheme to predict further into the future with progressively less temporal context. This encourages the model to only encode slowly varying spatial-temporal signals, therefore leading to semantic representations; Third, we evaluate the approach by first training the DPC model on the Kinetics-400 dataset with self-supervised learning, and then finetuning the representation on a downstream task, i.e. action recognition. With single stream (RGB only), DPC pretrained representations achieve state-of-the-art self-supervised performance on both UCF101(75.7% top1 acc) and HMDB51(35.7% top1 acc), outperforming all previous learning methods by a significant margin, and approaching the performance of a baseline pre-trained on ImageNet.
Geometry-Aware Video Object Detection for Static Cameras
Sep 06, 2019
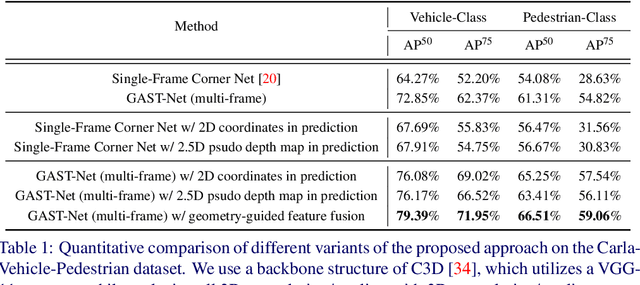
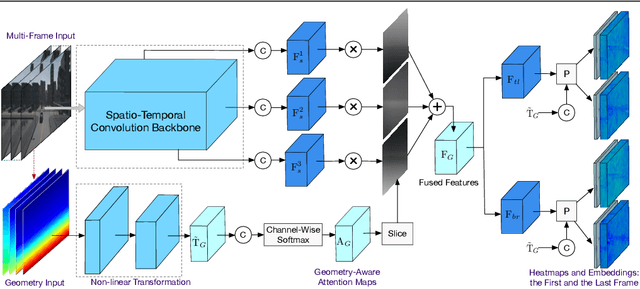
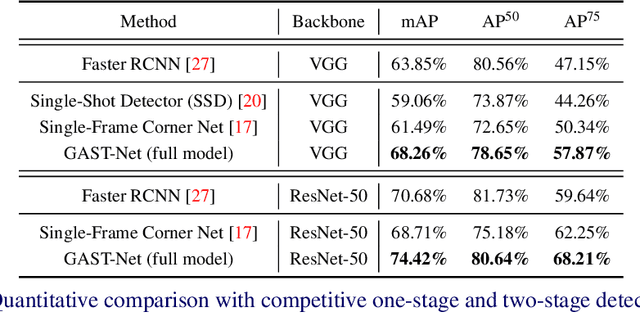
In this paper we propose a geometry-aware model for video object detection. Specifically, we consider the setting that cameras can be well approximated as static, e.g. in video surveillance scenarios, and scene pseudo depth maps can therefore be inferred easily from the object scale on the image plane. We make the following contributions: First, we extend the recent anchor-free detector (CornerNet [17]) to video object detections. In order to exploit the spatial-temporal information while maintaining high efficiency, the proposed model accepts video clips as input, and only makes predictions for the starting and the ending frames, i.e. heatmaps of object bounding box corners and the corresponding embeddings for grouping. Second, to tackle the challenge from scale variations in object detection, scene geometry information, e.g. derived depth maps, is explicitly incorporated into deep networks for multi-scale feature selection and for the network prediction. Third, we validate the proposed architectures on an autonomous driving dataset generated from the Carla simulator [5], and on a real dataset for human detection (DukeMTMC dataset [28]). When comparing with the existing competitive single-stage or two-stage detectors, the proposed geometry-aware spatio-temporal network achieves significantly better results.
Learning to Discover Novel Visual Categories via Deep Transfer Clustering
Aug 26, 2019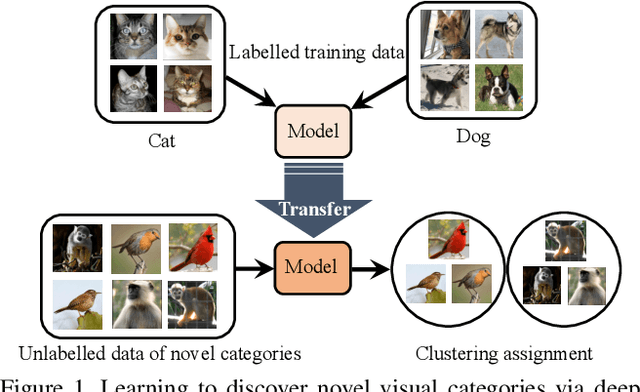
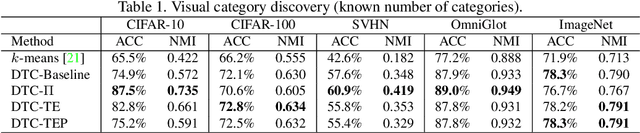

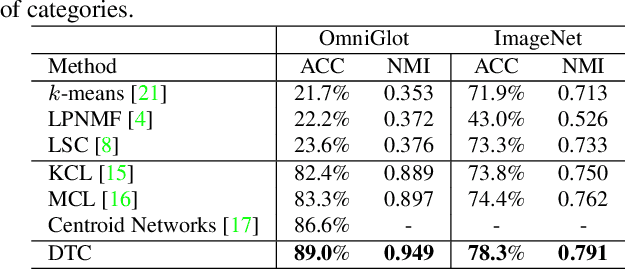
We consider the problem of discovering novel object categories in an image collection. While these images are unlabelled, we also assume prior knowledge of related but different image classes. We use such prior knowledge to reduce the ambiguity of clustering, and improve the quality of the newly discovered classes. Our contributions are twofold. The first contribution is to extend Deep Embedded Clustering to a transfer learning setting; we also improve the algorithm by introducing a representation bottleneck, temporal ensembling, and consistency. The second contribution is a method to estimate the number of classes in the unlabelled data. This also transfers knowledge from the known classes, using them as probes to diagnose different choices for the number of classes in the unlabelled subset. We thoroughly evaluate our method, substantially outperforming state-of-the-art techniques in a large number of benchmarks, including ImageNet, OmniGlot, CIFAR-100, CIFAR-10, and SVHN.
EPIC-Fusion: Audio-Visual Temporal Binding for Egocentric Action Recognition
Aug 22, 2019
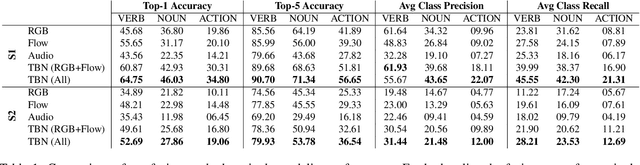
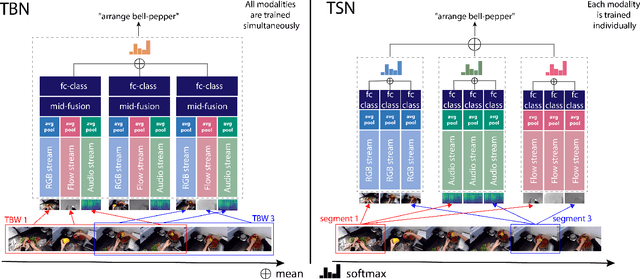
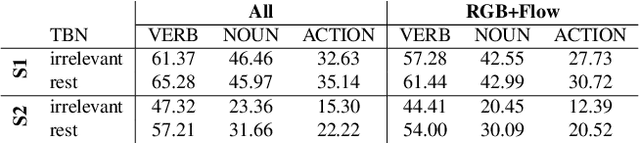
We focus on multi-modal fusion for egocentric action recognition, and propose a novel architecture for multi-modal temporal-binding, i.e. the combination of modalities within a range of temporal offsets. We train the architecture with three modalities -- RGB, Flow and Audio -- and combine them with mid-level fusion alongside sparse temporal sampling of fused representations. In contrast with previous works, modalities are fused before temporal aggregation, with shared modality and fusion weights over time. Our proposed architecture is trained end-to-end, outperforming individual modalities as well as late-fusion of modalities. We demonstrate the importance of audio in egocentric vision, on per-class basis, for identifying actions as well as interacting objects. Our method achieves state of the art results on both the seen and unseen test sets of the largest egocentric dataset: EPIC-Kitchens, on all metrics using the public leaderboard.
AutoCorrect: Deep Inductive Alignment of Noisy Geometric Annotations
Aug 14, 2019
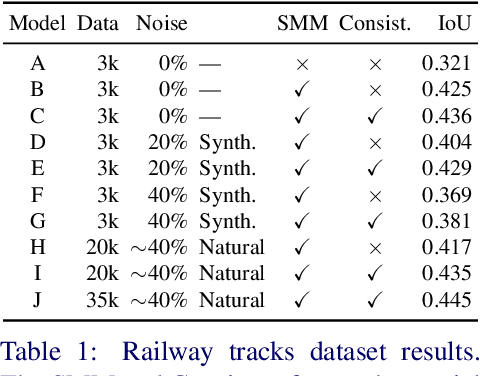
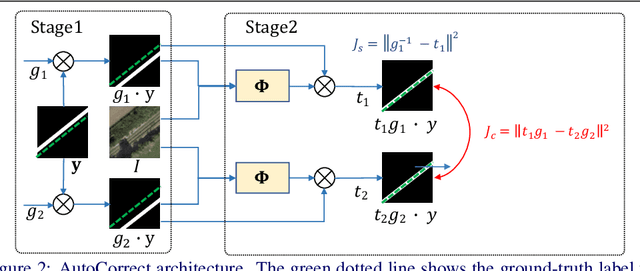
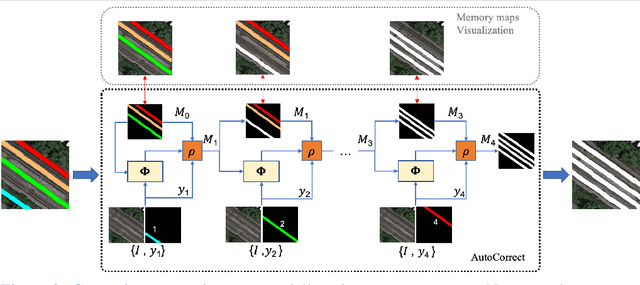
We propose AutoCorrect, a method to automatically learn object-annotation alignments from a dataset with annotations affected by geometric noise. The method is based on a consistency loss that enables deep neural networks to be trained, given only noisy annotations as input, to correct the annotations. When some noise-free annotations are available, we show that the consistency loss reduces to a stricter self-supervised loss. We also show that the method can implicitly leverage object symmetries to reduce the ambiguity arising in correcting noisy annotations. When multiple object-annotation pairs are present in an image, we introduce a spatial memory map that allows the network to correct annotations sequentially, one at a time, while accounting for all other annotations in the image and corrections performed so far. Through ablation, we show the benefit of these contributions, demonstrating excellent results on geo-spatial imagery. Specifically, we show results using a new Railway tracks dataset as well as the public INRIA Buildings benchmarks, achieving new state-of-the-art results for the latter.
Use What You Have: Video Retrieval Using Representations From Collaborative Experts
Jul 31, 2019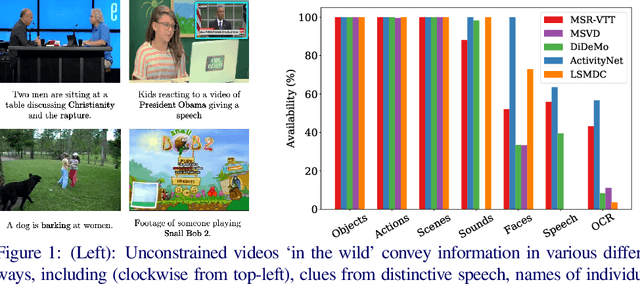
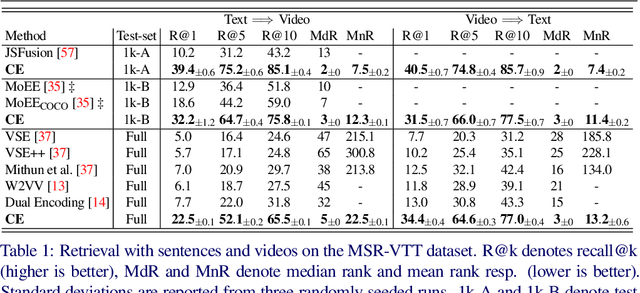
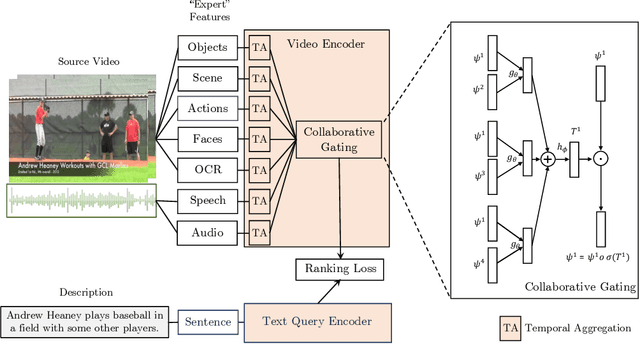
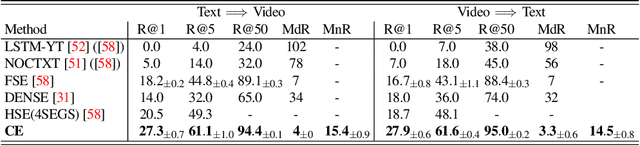
The rapid growth of video on the internet has made searching for video content using natural language queries a significant challenge. Human generated queries for video datasets `in the wild' vary a lot in terms of degree of specificity, with some queries describing `specific details' such as the names of famous identities, content from speech, or text available on the screen. Our goal is to condense the multi-modal, extremely high dimensional information from videos into a single, compact video representation for the task of video retrieval using free-form text queries, where the degree of specificity is open-ended. For this we exploit existing knowledge in the form of pretrained semantic embeddings which include `general' features such as motion, appearance, and scene features from visual content, and more `specific' cues from ASR and OCR which may not always be available, but allow for more fine-grained disambiguation when present. We propose a collaborative experts model to aggregate information effectively from these different pretrained experts. The effectiveness of our approach is demonstrated empirically, setting new state-of-the-art performances on five retrieval benchmarks: MSR-VTT, LSMDC, MSVD, DiDeMo, and ActivityNet, while simultaneously reducing the number of parameters used by prior work. Code and data can be found at www.robots.ox.ac.uk/~vgg/research/collaborative-experts/.
A Short Note on the Kinetics-700 Human Action Dataset
Jul 15, 2019
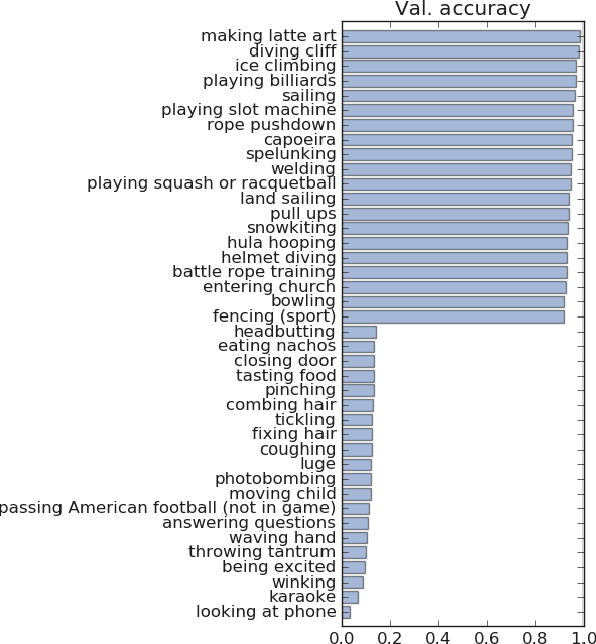
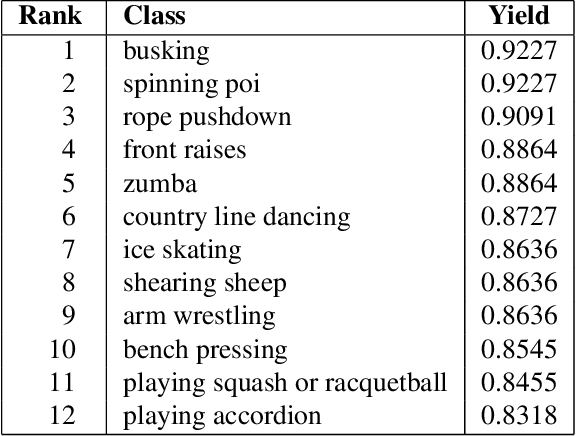

We describe an extension of the DeepMind Kinetics human action dataset from 600 classes to 700 classes, where for each class there are at least 600 video clips from different YouTube videos. This paper details the changes introduced for this new release of the dataset, and includes a comprehensive set of statistics as well as baseline results using the I3D neural network architecture.
My lips are concealed: Audio-visual speech enhancement through obstructions
Jul 11, 2019
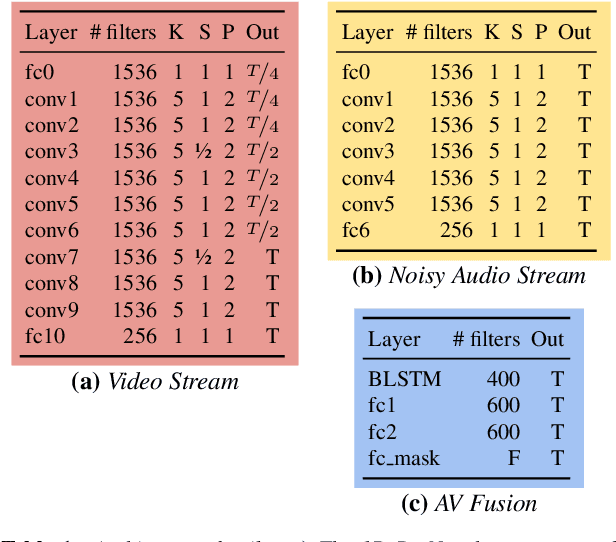
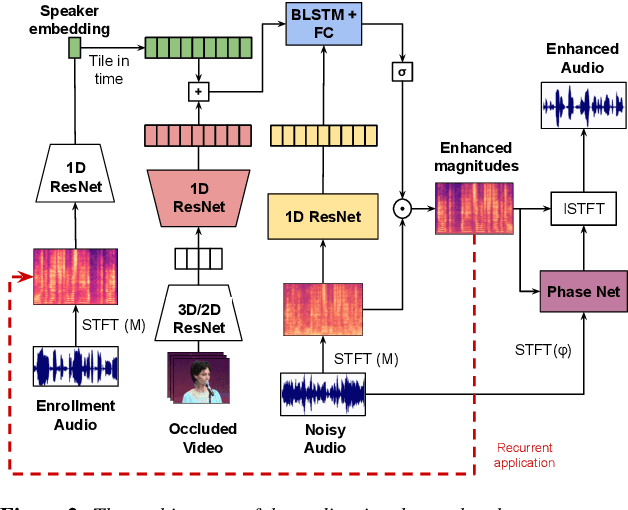
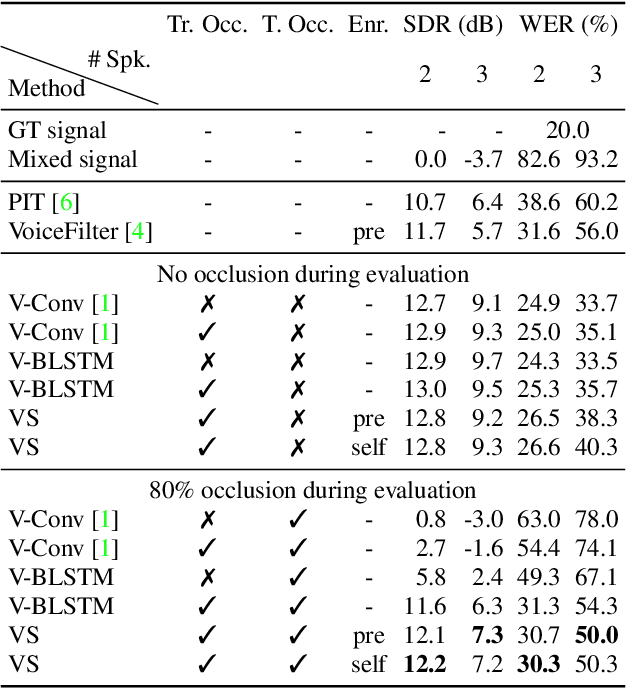
Our objective is an audio-visual model for separating a single speaker from a mixture of sounds such as other speakers and background noise. Moreover, we wish to hear the speaker even when the visual cues are temporarily absent due to occlusion. To this end we introduce a deep audio-visual speech enhancement network that is able to separate a speaker's voice by conditioning on both the speaker's lip movements and/or a representation of their voice. The voice representation can be obtained by either (i) enrollment, or (ii) by self-enrollment -- learning the representation on-the-fly given sufficient unobstructed visual input. The model is trained by blending audios, and by introducing artificial occlusions around the mouth region that prevent the visual modality from dominating. The method is speaker-independent, and we demonstrate it on real examples of speakers unheard (and unseen) during training. The method also improves over previous models in particular for cases of occlusion in the visual modality.
Sim2real transfer learning for 3D pose estimation: motion to the rescue
Jul 04, 2019
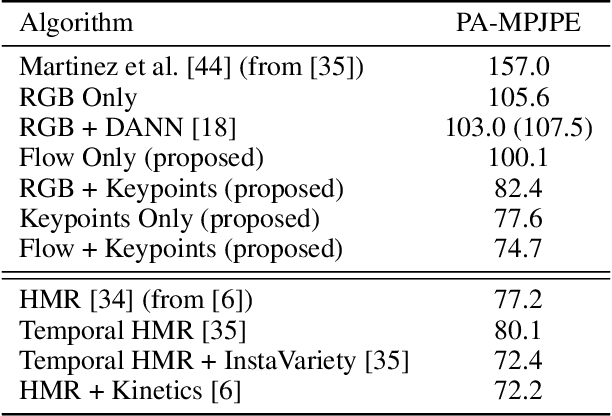
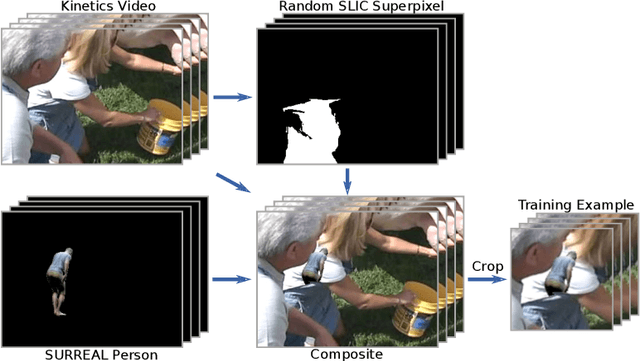

Simulation is an anonymous, low-bias source of data where annotation can often be done automatically; however, for some tasks, current models trained on synthetic data generalize poorly to real data. The task of 3D human pose estimation is a particularly interesting example of this sim2real problem, because learning-based approaches perform reasonably well given real training data, yet labeled 3D poses are extremely difficult to obtain in the wild, limiting scalability. In this paper, we show that standard neural-network approaches, which perform poorly when trained on synthetic RGB images, can perform well when the data is pre-processed to extract cues about the person's motion, notably as optical flow and the motion of 2D keypoints. Therefore, our results suggest that motion can be a simple way to bridge a sim2real gap when video is available. We evaluate on the 3D Poses in the Wild dataset, the most challenging modern standard of 3D pose estimation, where we show full 3D mesh recovery that is on par with state-of-the-art methods trained on real 3D sequences, despite training only on synthetic humans from the SURREAL dataset.