 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterventions, Where and How? Experimental Design for Causal Models at Scale
Mar 03, 2022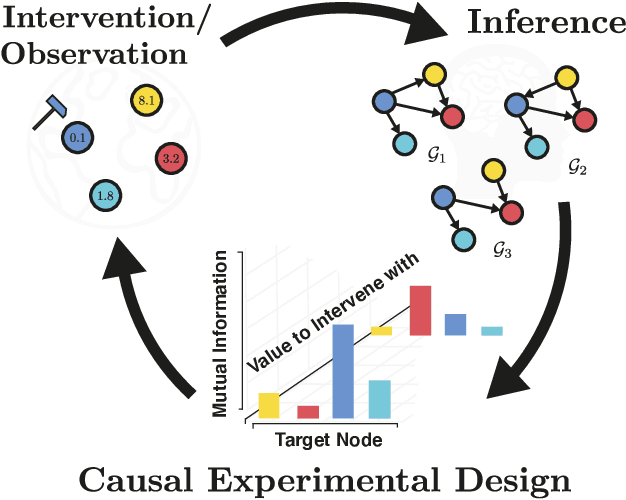
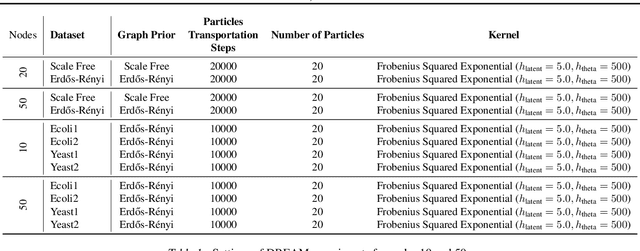
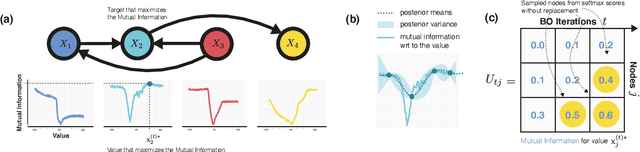
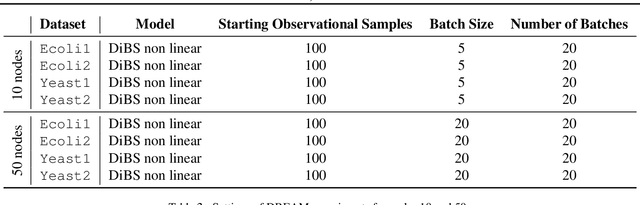
Causal discovery from observational and interventional data is challenging due to limited data and non-identifiability which introduces uncertainties in estimating the underlying structural causal model (SCM). Incorporating these uncertainties and selecting optimal experiments (interventions) to perform can help to identify the true SCM faster. Existing methods in experimental design for causal discovery from limited data either rely on linear assumptions for the SCM or select only the intervention target. In this paper, we incorporate recent advances in Bayesian causal discovery into the Bayesian optimal experimental design framework, which allows for active causal discovery of nonlinear, large SCMs, while selecting both the target and the value to intervene with. We demonstrate the performance of the proposed method on synthetic graphs (Erdos-R\`enyi, Scale Free) for both linear and nonlinear SCMs as well as on the in-silico single-cell gene regulatory network dataset, DREAM.
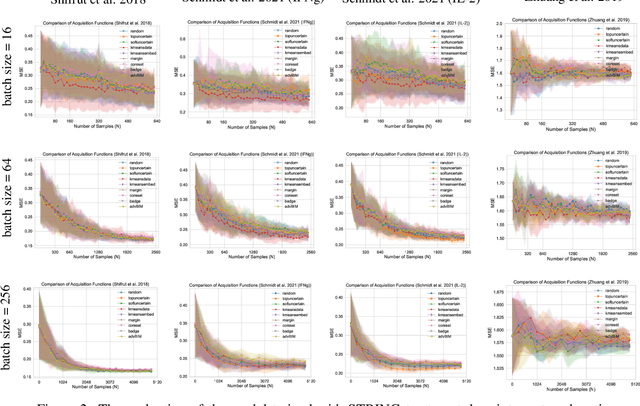
Causal-BALD: Deep Bayesian Active Learning of Outcomes to Infer Treatment-Effects from Observational Data
Nov 03, 2021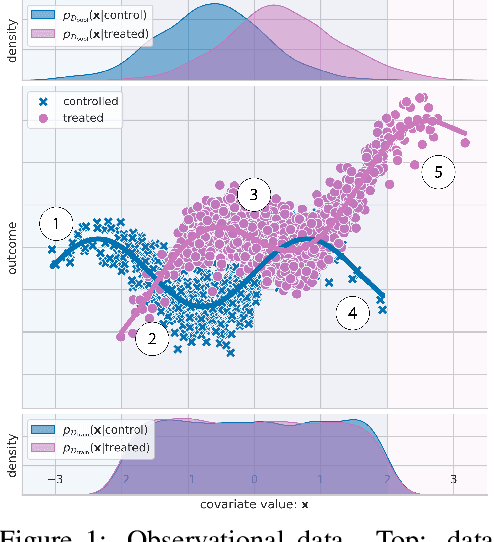
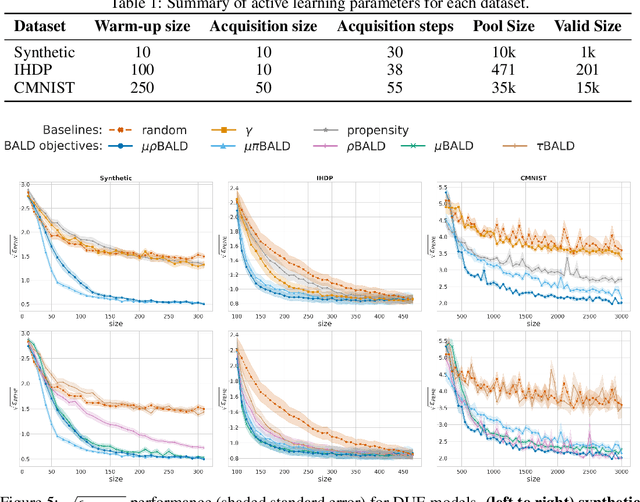
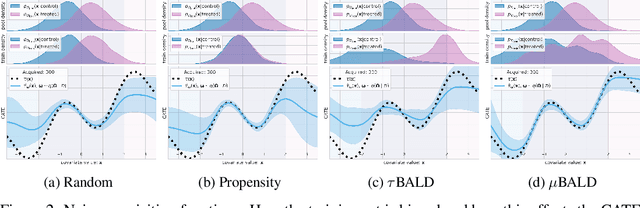

Estimating personalized treatment effects from high-dimensional observational data is essential in situations where experimental designs are infeasible, unethical, or expensive. Existing approaches rely on fitting deep models on outcomes observed for treated and control populations. However, when measuring individual outcomes is costly, as is the case of a tumor biopsy, a sample-efficient strategy for acquiring each result is required. Deep Bayesian active learning provides a framework for efficient data acquisition by selecting points with high uncertainty. However, existing methods bias training data acquisition towards regions of non-overlapping support between the treated and control populations. These are not sample-efficient because the treatment effect is not identifiable in such regions. We introduce causal, Bayesian acquisition functions grounded in information theory that bias data acquisition towards regions with overlapping support to maximize sample efficiency for learning personalized treatment effects. We demonstrate the performance of the proposed acquisition strategies on synthetic and semi-synthetic datasets IHDP and CMNIST and their extensions, which aim to simulate common dataset biases and pathologies.
Using Non-Linear Causal Models to Study Aerosol-Cloud Interactions in the Southeast Pacific
Nov 03, 2021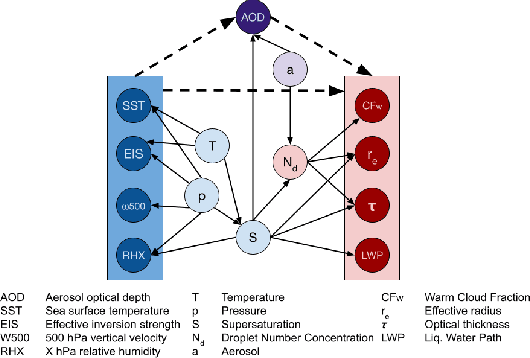

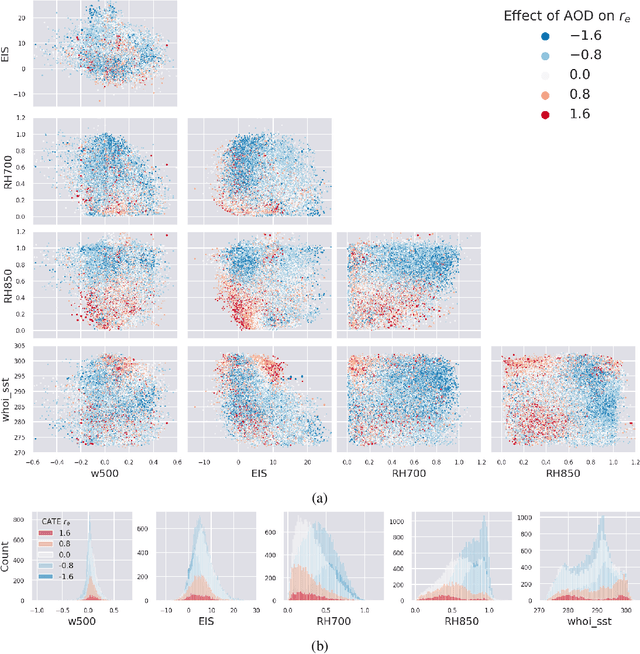
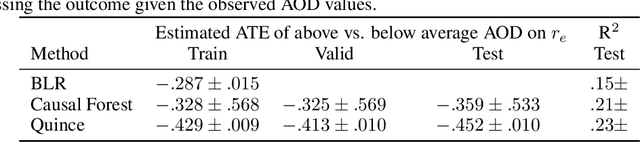
Aerosol-cloud interactions include a myriad of effects that all begin when aerosol enters a cloud and acts as cloud condensation nuclei (CCN). An increase in CCN results in a decrease in the mean cloud droplet size (r$_{e}$). The smaller droplet size leads to brighter, more expansive, and longer lasting clouds that reflect more incoming sunlight, thus cooling the earth. Globally, aerosol-cloud interactions cool the Earth, however the strength of the effect is heterogeneous over different meteorological regimes. Understanding how aerosol-cloud interactions evolve as a function of the local environment can help us better understand sources of error in our Earth system models, which currently fail to reproduce the observed relationships. In this work we use recent non-linear, causal machine learning methods to study the heterogeneous effects of aerosols on cloud droplet radius.
GeneDisco: A Benchmark for Experimental Design in Drug Discovery
Oct 22, 2021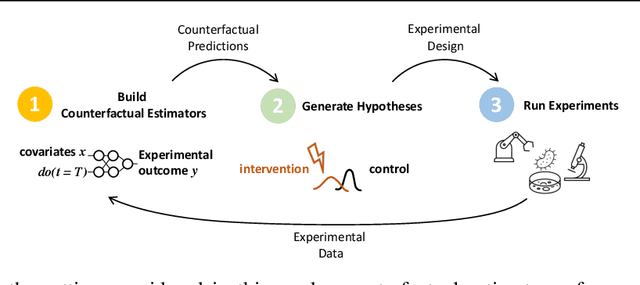
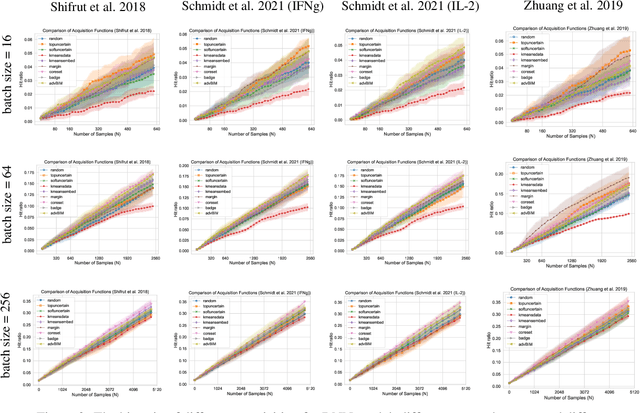
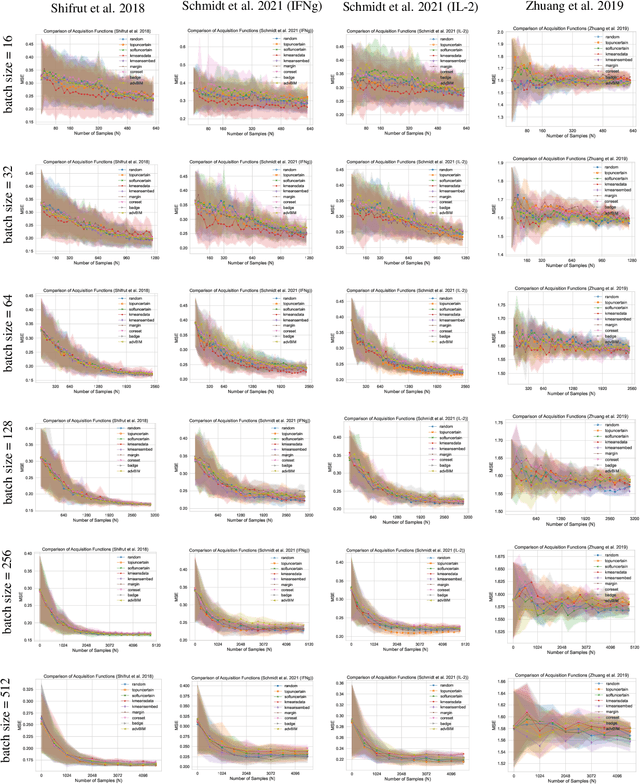
In vitro cellular experimentation with genetic interventions, using for example CRISPR technologies, is an essential step in early-stage drug discovery and target validation that serves to assess initial hypotheses about causal associations between biological mechanisms and disease pathologies. With billions of potential hypotheses to test, the experimental design space for in vitro genetic experiments is extremely vast, and the available experimental capacity - even at the largest research institutions in the world - pales in relation to the size of this biological hypothesis space. Machine learning methods, such as active and reinforcement learning, could aid in optimally exploring the vast biological space by integrating prior knowledge from various information sources as well as extrapolating to yet unexplored areas of the experimental design space based on available data. However, there exist no standardised benchmarks and data sets for this challenging task and little research has been conducted in this area to date. Here, we introduce GeneDisco, a benchmark suite for evaluating active learning algorithms for experimental design in drug discovery. GeneDisco contains a curated set of multiple publicly available experimental data sets as well as open-source implementations of state-of-the-art active learning policies for experimental design and exploration.
Quantifying Ignorance in Individual-Level Causal-Effect Estimates under Hidden Confounding
Mar 08, 2021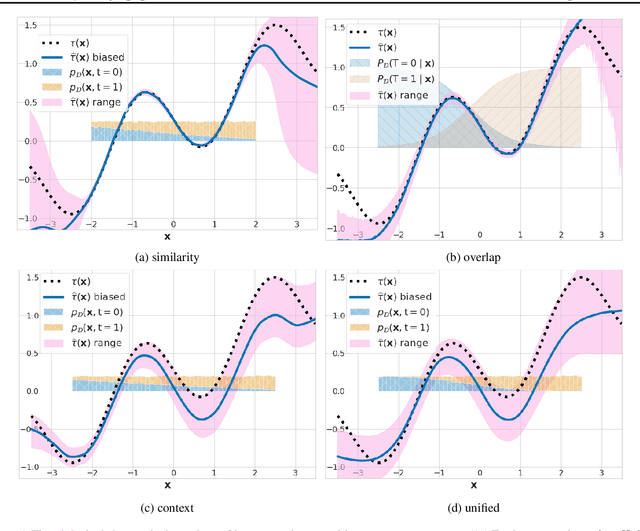

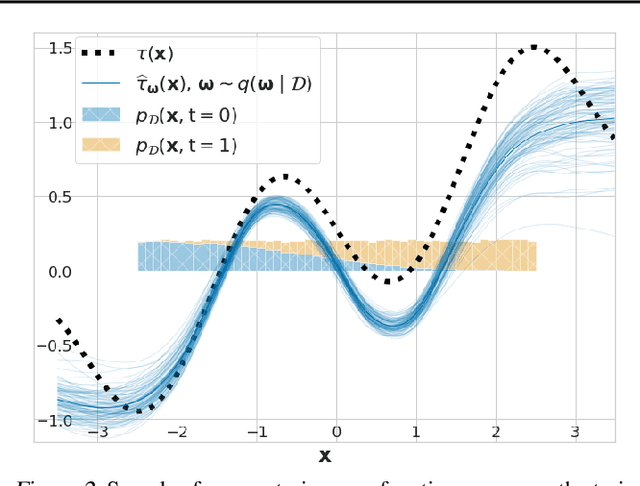
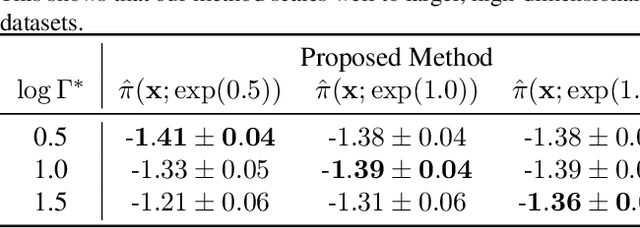
We study the problem of learning conditional average treatment effects (CATE) from high-dimensional, observational data with unobserved confounders. Unobserved confounders introduce ignorance -- a level of unidentifiability -- about an individual's response to treatment by inducing bias in CATE estimates. We present a new parametric interval estimator suited for high-dimensional data, that estimates a range of possible CATE values when given a predefined bound on the level of hidden confounding. Further, previous interval estimators do not account for ignorance about the CATE stemming from samples that may be underrepresented in the original study, or samples that violate the overlap assumption. Our novel interval estimator also incorporates model uncertainty so that practitioners can be made aware of out-of-distribution data. We prove that our estimator converges to tight bounds on CATE when there may be unobserved confounding, and assess it using semi-synthetic, high-dimensional datasets.
Improving Deterministic Uncertainty Estimation in Deep Learning for Classification and Regression
Feb 22, 2021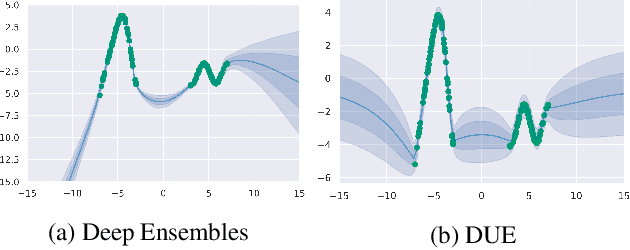

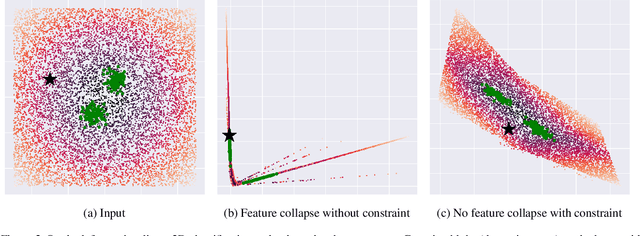
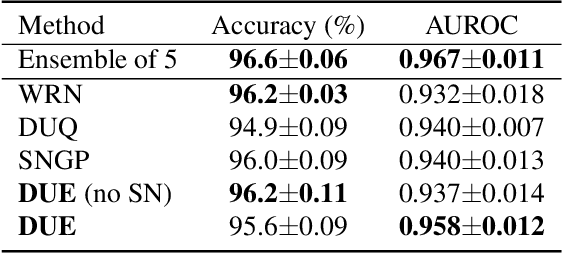
We propose a new model that estimates uncertainty in a single forward pass and works on both classification and regression problems. Our approach combines a bi-Lipschitz feature extractor with an inducing point approximate Gaussian process, offering robust and principled uncertainty estimation. This can be seen as a refinement of Deep Kernel Learning (DKL), with our changes allowing DKL to match softmax neural networks accuracy. Our method overcomes the limitations of previous work addressing deterministic uncertainty quantification, such as the dependence of uncertainty on ad hoc hyper-parameters. Our method matches SotA accuracy, 96.2% on CIFAR-10, while maintaining the speed of softmax models, and provides uncertainty estimates that outperform previous single forward pass uncertainty models. Finally, we demonstrate our method on a recently introduced benchmark for uncertainty in regression: treatment deferral in causal models for personalized medicine.
Identifying Causal Effect Inference Failure with Uncertainty-Aware Models
Jul 01, 2020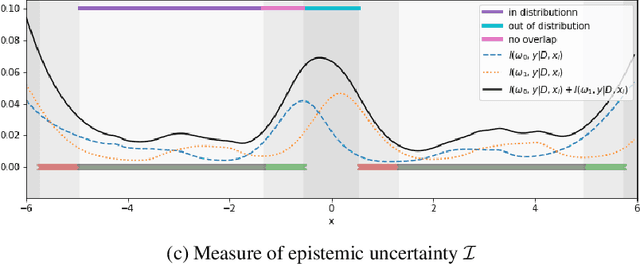
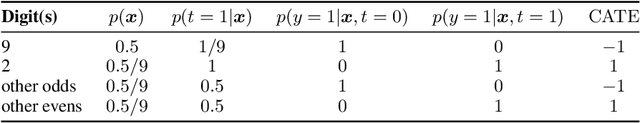
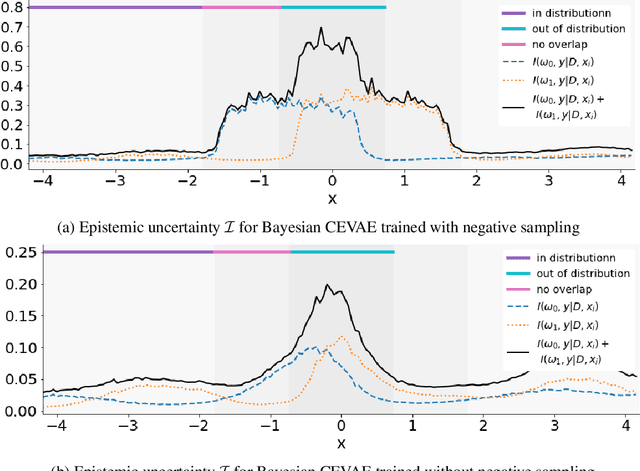
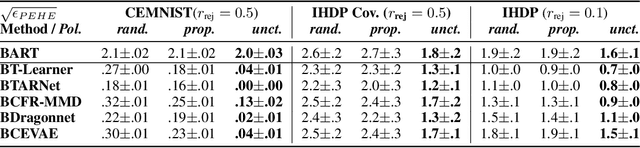
Recommending the best course of action for an individual is a major application of individual-level causal effect estimation. This application is often needed in safety-critical domains such as healthcare, where estimating and communicating uncertainty to decision-makers is crucial. We introduce a practical approach for integrating uncertainty estimation into a class of state-of-the-art neural network methods used for individual-level causal estimates. We show that our methods enable us to deal gracefully with situations of "no-overlap", common in high-dimensional data, where standard applications of causal effect approaches fail. Further, our methods allow us to handle covariate shift, where test distribution differs to train distribution, common when systems are deployed in practice. We show that when such a covariate shift occurs, correctly modeling uncertainty can keep us from giving overconfident and potentially harmful recommendations. We demonstrate our methodology with a range of state-of-the-art models. Under both covariate shift and lack of overlap, our uncertainty-equipped methods can alert decisions makers when predictions are not to be trusted while outperforming their uncertainty-oblivious counterparts.
CASED: Curriculum Adaptive Sampling for Extreme Data Imbalance
Jul 27, 2018
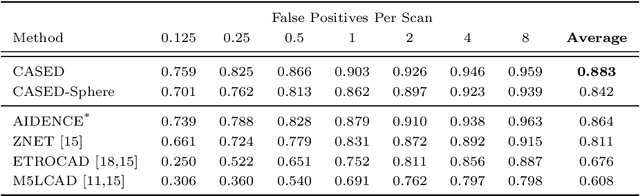
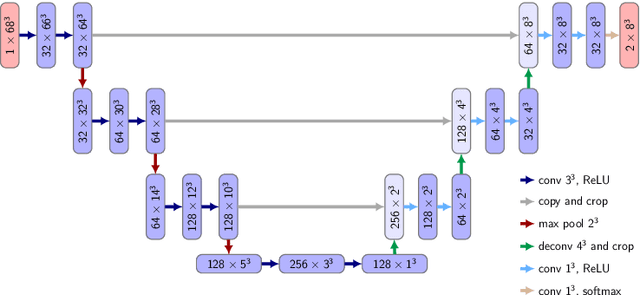
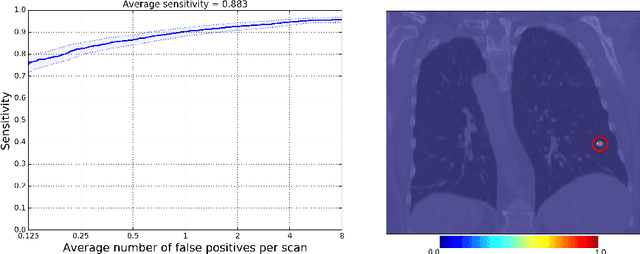
We introduce CASED, a novel curriculum sampling algorithm that facilitates the optimization of deep learning segmentation or detection models on data sets with extreme class imbalance. We evaluate the CASED learning framework on the task of lung nodule detection in chest CT. In contrast to two-stage solutions, wherein nodule candidates are first proposed by a segmentation model and refined by a second detection stage, CASED improves the training of deep nodule segmentation models (e.g. UNet) to the point where state of the art results are achieved using only a trivial detection stage. CASED improves the optimization of deep segmentation models by allowing them to first learn how to distinguish nodules from their immediate surroundings, while continuously adding a greater proportion of difficult-to-classify global context, until uniformly sampling from the empirical data distribution. Using CASED during training yields a minimalist proposal to the lung nodule detection problem that tops the LUNA16 nodule detection benchmark with an average sensitivity score of 88.35%. Furthermore, we find that models trained using CASED are robust to nodule annotation quality by showing that comparable results can be achieved when only a point and radius for each ground truth nodule are provided during training. Finally, the CASED learning framework makes no assumptions with regard to imaging modality or segmentation target and should generalize to other medical imaging problems where class imbalance is a persistent problem.
Adversarially Learned Mixture Model
Jul 14, 2018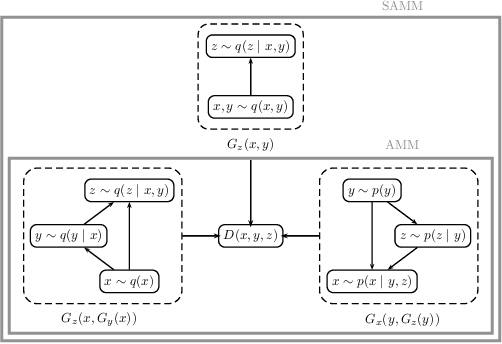

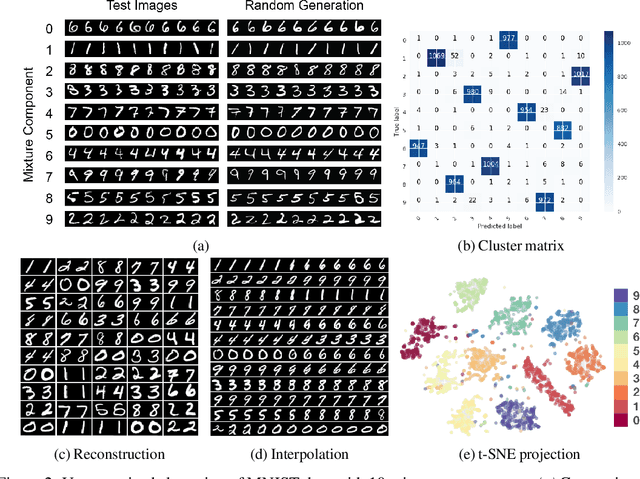
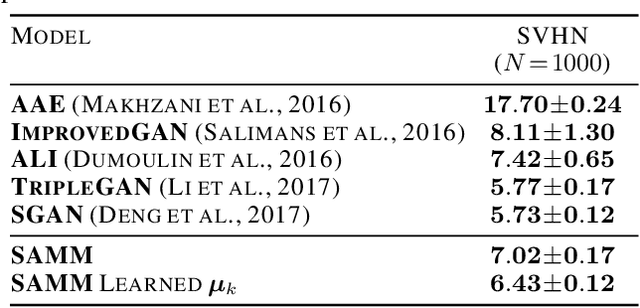
The Adversarially Learned Mixture Model (AMM) is a generative model for unsupervised or semi-supervised data clustering. The AMM is the first adversarially optimized method to model the conditional dependence between inferred continuous and categorical latent variables. Experiments on the MNIST and SVHN datasets show that the AMM allows for semantic separation of complex data when little or no labeled data is available. The AMM achieves a state-of-the-art unsupervised clustering error rate of 2.86% on the MNIST dataset. A semi-supervised extension of the AMM yields competitive results on the SVHN dataset.
On the Importance of Attention in Meta-Learning for Few-Shot Text Classification
Jun 03, 2018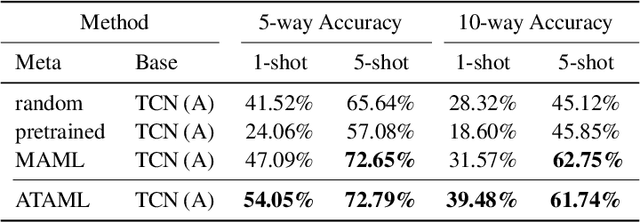
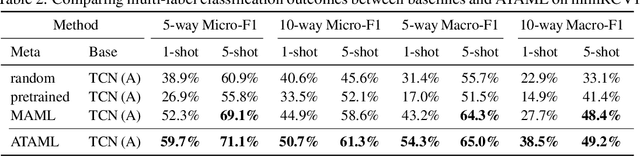
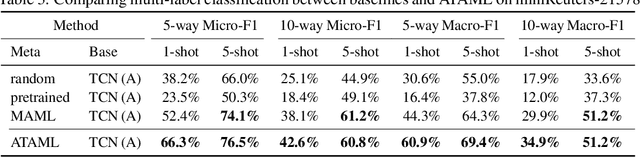
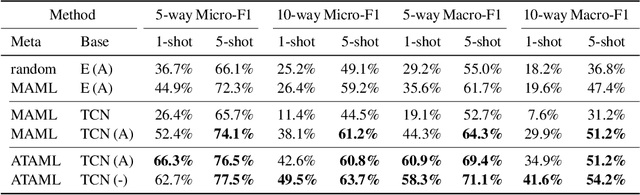
Current deep learning based text classification methods are limited by their ability to achieve fast learning and generalization when the data is scarce. We address this problem by integrating a meta-learning procedure that uses the knowledge learned across many tasks as an inductive bias towards better natural language understanding. Based on the Model-Agnostic Meta-Learning framework (MAML), we introduce the Attentive Task-Agnostic Meta-Learning (ATAML) algorithm for text classification. The essential difference between MAML and ATAML is in the separation of task-agnostic representation learning and task-specific attentive adaptation. The proposed ATAML is designed to encourage task-agnostic representation learning by way of task-agnostic parameterization and facilitate task-specific adaptation via attention mechanisms. We provide evidence to show that the attention mechanism in ATAML has a synergistic effect on learning performance. In comparisons with models trained from random initialization, pretrained models and meta trained MAML, our proposed ATAML method generalizes better on single-label and multi-label classification tasks in miniRCV1 and miniReuters-21578 datasets.