 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentCRF: Continuous CRF for Efficient Latent Diffusion
Dec 24, 2024



Latent Diffusion Models (LDMs) produce high-quality, photo-realistic images, however, the latency incurred by multiple costly inference iterations can restrict their applicability. We introduce LatentCRF, a continuous Conditional Random Field (CRF) model, implemented as a neural network layer, that models the spatial and semantic relationships among the latent vectors in the LDM. By replacing some of the computationally-intensive LDM inference iterations with our lightweight LatentCRF, we achieve a superior balance between quality, speed and diversity. We increase inference efficiency by 33% with no loss in image quality or diversity compared to the full LDM. LatentCRF is an easy add-on, which does not require modifying the LDM.
Efficient Document Ranking with Learnable Late Interactions
Jun 25, 2024



Cross-Encoder (CE) and Dual-Encoder (DE) models are two fundamental approaches for query-document relevance in information retrieval. To predict relevance, CE models use joint query-document embeddings, while DE models maintain factorized query and document embeddings; usually, the former has higher quality while the latter benefits from lower latency. Recently, late-interaction models have been proposed to realize more favorable latency-quality tradeoffs, by using a DE structure followed by a lightweight scorer based on query and document token embeddings. However, these lightweight scorers are often hand-crafted, and there is no understanding of their approximation power; further, such scorers require access to individual document token embeddings, which imposes an increased latency and storage burden. In this paper, we propose novel learnable late-interaction models (LITE) that resolve these issues. Theoretically, we prove that LITE is a universal approximator of continuous scoring functions, even for relatively small embedding dimension. Empirically, LITE outperforms previous late-interaction models such as ColBERT on both in-domain and zero-shot re-ranking tasks. For instance, experiments on MS MARCO passage re-ranking show that LITE not only yields a model with better generalization, but also lowers latency and requires 0.25x storage compared to ColBERT.
SPEGTI: Structured Prediction for Efficient Generative Text-to-Image Models
Aug 14, 2023Modern text-to-image generation models produce high-quality images that are both photorealistic and faithful to the text prompts. However, this quality comes at significant computational cost: nearly all of these models are iterative and require running inference multiple times with large models. This iterative process is needed to ensure that different regions of the image are not only aligned with the text prompt, but also compatible with each other. In this work, we propose a light-weight approach to achieving this compatibility between different regions of an image, using a Markov Random Field (MRF) model. This method is shown to work in conjunction with the recently proposed Muse model. The MRF encodes the compatibility among image tokens at different spatial locations and enables us to significantly reduce the required number of Muse prediction steps. Inference with the MRF is significantly cheaper, and its parameters can be quickly learned through back-propagation by modeling MRF inference as a differentiable neural-network layer. Our full model, SPEGTI, uses this proposed MRF model to speed up Muse by 1.5X with no loss in output image quality.
Large Language Models with Controllable Working Memory
Nov 09, 2022



Large language models (LLMs) have led to a series of breakthroughs in natural language processing (NLP), owing to their excellent understanding and generation abilities. Remarkably, what further sets these models apart is the massive amounts of world knowledge they internalize during pretraining. While many downstream applications provide the model with an informational context to aid its performance on the underlying task, how the model's world knowledge interacts with the factual information presented in the context remains under explored. As a desirable behavior, an LLM should give precedence to the context whenever it contains task-relevant information that conflicts with the model's memorized knowledge. This enables model predictions to be grounded in the context, which can then be used to update or correct specific model predictions without frequent retraining. By contrast, when the context is irrelevant to the task, the model should ignore it and fall back on its internal knowledge. In this paper, we undertake a first joint study of the aforementioned two properties, namely controllability and robustness, in the context of LLMs. We demonstrate that state-of-the-art T5 and PaLM (both pretrained and finetuned) could exhibit poor controllability and robustness, which do not scale with increasing model size. As a solution, we propose a novel method - Knowledge Aware FineTuning (KAFT) - to strengthen both controllability and robustness by incorporating counterfactual and irrelevant contexts to standard supervised datasets. Our comprehensive evaluation showcases the utility of KAFT across model architectures and sizes.
When does mixup promote local linearity in learned representations?
Oct 28, 2022



Mixup is a regularization technique that artificially produces new samples using convex combinations of original training points. This simple technique has shown strong empirical performance, and has been heavily used as part of semi-supervised learning techniques such as mixmatch~\citep{berthelot2019mixmatch} and interpolation consistent training (ICT)~\citep{verma2019interpolation}. In this paper, we look at Mixup through a \emph{representation learning} lens in a semi-supervised learning setup. In particular, we study the role of Mixup in promoting linearity in the learned network representations. Towards this, we study two questions: (1) how does the Mixup loss that enforces linearity in the \emph{last} network layer propagate the linearity to the \emph{earlier} layers?; and (2) how does the enforcement of stronger Mixup loss on more than two data points affect the convergence of training? We empirically investigate these properties of Mixup on vision datasets such as CIFAR-10, CIFAR-100 and SVHN. Our results show that supervised Mixup training does not make \emph{all} the network layers linear; in fact the \emph{intermediate layers} become more non-linear during Mixup training compared to a network that is trained \emph{without} Mixup. However, when Mixup is used as an unsupervised loss, we observe that all the network layers become more linear resulting in faster training convergence.
Teacher Guided Training: An Efficient Framework for Knowledge Transfer
Aug 14, 2022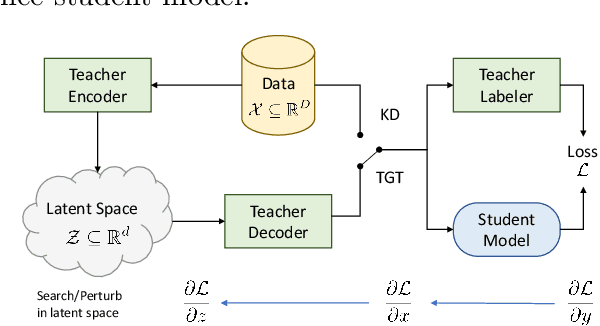
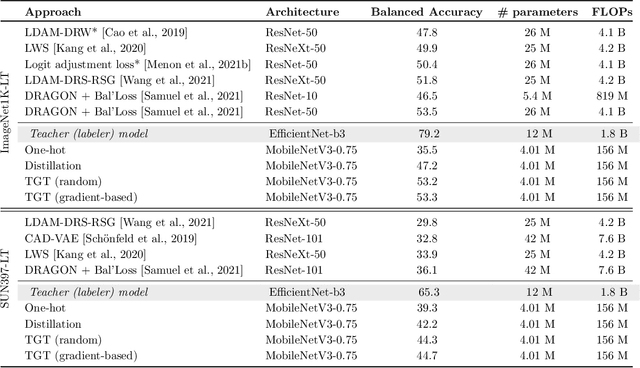
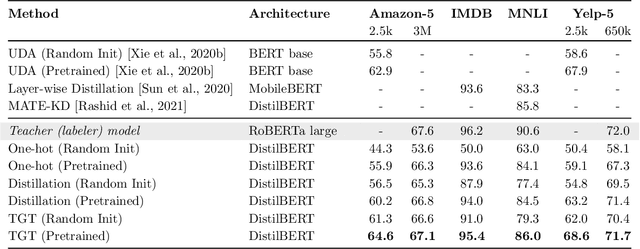
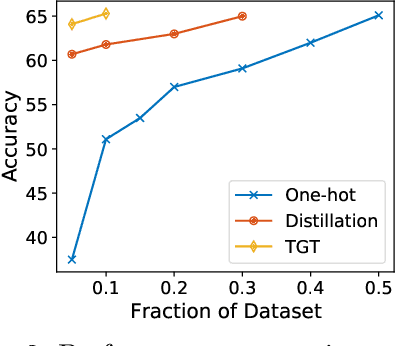
The remarkable performance gains realized by large pretrained models, e.g., GPT-3, hinge on the massive amounts of data they are exposed to during training. Analogously, distilling such large models to compact models for efficient deployment also necessitates a large amount of (labeled or unlabeled) training data. In this paper, we propose the teacher-guided training (TGT) framework for training a high-quality compact model that leverages the knowledge acquired by pretrained generative models, while obviating the need to go through a large volume of data. TGT exploits the fact that the teacher has acquired a good representation of the underlying data domain, which typically corresponds to a much lower dimensional manifold than the input space. Furthermore, we can use the teacher to explore input space more efficiently through sampling or gradient-based methods; thus, making TGT especially attractive for limited data or long-tail settings. We formally capture this benefit of proposed data-domain exploration in our generalization bounds. We find that TGT can improve accuracy on several image classification benchmarks as well as a range of text classification and retrieval tasks.
Leveraging redundancy in attention with Reuse Transformers
Oct 13, 2021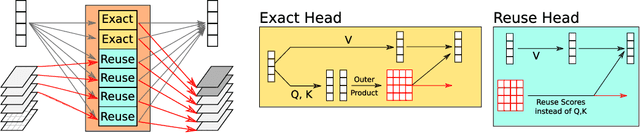
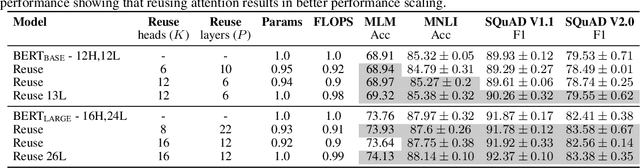
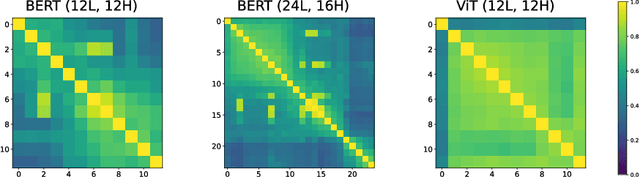
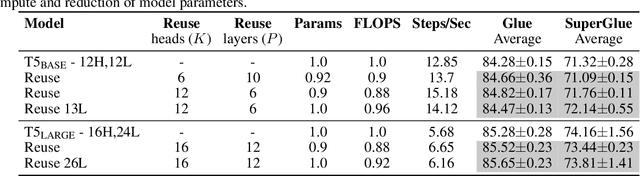
Pairwise dot product-based attention allows Transformers to exchange information between tokens in an input-dependent way, and is key to their success across diverse applications in language and vision. However, a typical Transformer model computes such pairwise attention scores repeatedly for the same sequence, in multiple heads in multiple layers. We systematically analyze the empirical similarity of these scores across heads and layers and find them to be considerably redundant, especially adjacent layers showing high similarity. Motivated by these findings, we propose a novel architecture that reuses attention scores computed in one layer in multiple subsequent layers. Experiments on a number of standard benchmarks show that reusing attention delivers performance equivalent to or better than standard transformers, while reducing both compute and memory usage.
Eigen Analysis of Self-Attention and its Reconstruction from Partial Computation
Jun 16, 2021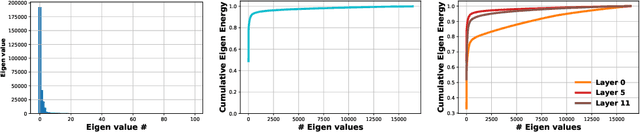
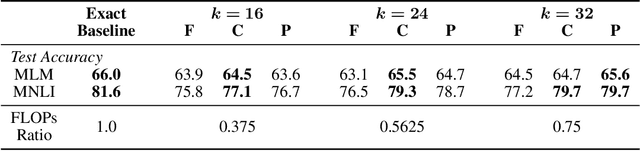
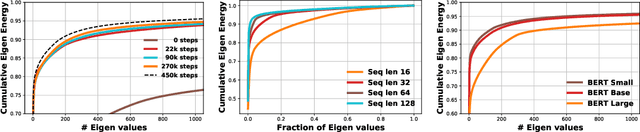
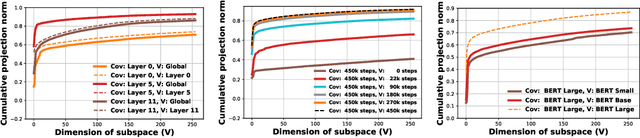
State-of-the-art transformer models use pairwise dot-product based self-attention, which comes at a computational cost quadratic in the input sequence length. In this paper, we investigate the global structure of attention scores computed using this dot product mechanism on a typical distribution of inputs, and study the principal components of their variation. Through eigen analysis of full attention score matrices, as well as of their individual rows, we find that most of the variation among attention scores lie in a low-dimensional eigenspace. Moreover, we find significant overlap between these eigenspaces for different layers and even different transformer models. Based on this, we propose to compute scores only for a partial subset of token pairs, and use them to estimate scores for the remaining pairs. Beyond investigating the accuracy of reconstructing attention scores themselves, we investigate training transformer models that employ these approximations, and analyze the effect on overall accuracy. Our analysis and the proposed method provide insights into how to balance the benefits of exact pair-wise attention and its significant computational expense.
Understanding Robustness of Transformers for Image Classification
Mar 26, 2021
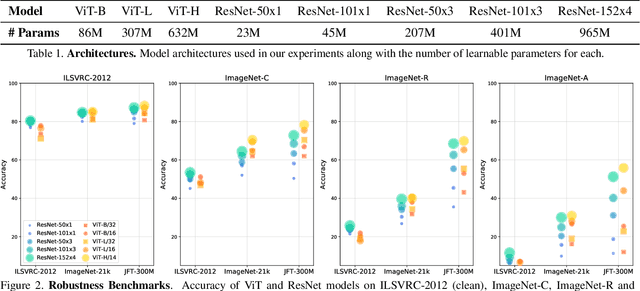
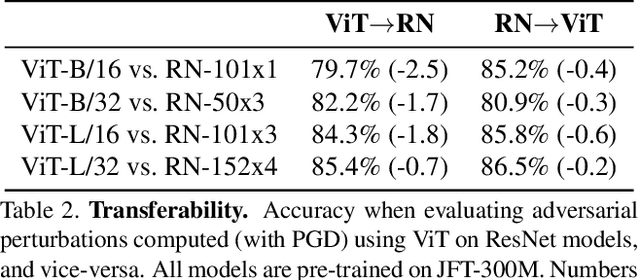

Deep Convolutional Neural Networks (CNNs) have long been the architecture of choice for computer vision tasks. Recently, Transformer-based architectures like Vision Transformer (ViT) have matched or even surpassed ResNets for image classification. However, details of the Transformer architecture -- such as the use of non-overlapping patches -- lead one to wonder whether these networks are as robust. In this paper, we perform an extensive study of a variety of different measures of robustness of ViT models and compare the findings to ResNet baselines. We investigate robustness to input perturbations as well as robustness to model perturbations. We find that when pre-trained with a sufficient amount of data, ViT models are at least as robust as the ResNet counterparts on a broad range of perturbations. We also find that Transformers are robust to the removal of almost any single layer, and that while activations from later layers are highly correlated with each other, they nevertheless play an important role in classification.
On the Reproducibility of Neural Network Predictions
Feb 05, 2021

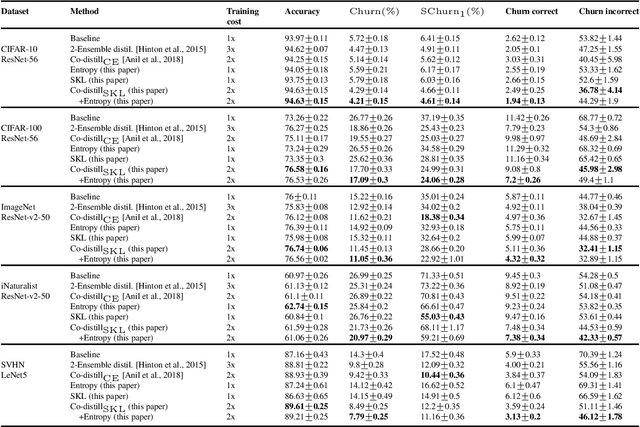
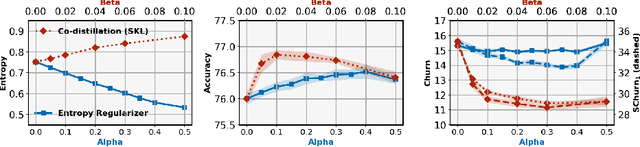
Standard training techniques for neural networks involve multiple sources of randomness, e.g., initialization, mini-batch ordering and in some cases data augmentation. Given that neural networks are heavily over-parameterized in practice, such randomness can cause {\em churn} -- for the same input, disagreements between predictions of the two models independently trained by the same algorithm, contributing to the `reproducibility challenges' in modern machine learning. In this paper, we study this problem of churn, identify factors that cause it, and propose two simple means of mitigating it. We first demonstrate that churn is indeed an issue, even for standard image classification tasks (CIFAR and ImageNet), and study the role of the different sources of training randomness that cause churn. By analyzing the relationship between churn and prediction confidences, we pursue an approach with two components for churn reduction. First, we propose using \emph{minimum entropy regularizers} to increase prediction confidences. Second, \changes{we present a novel variant of co-distillation approach~\citep{anil2018large} to increase model agreement and reduce churn}. We present empirical results showing the effectiveness of both techniques in reducing churn while improving the accuracy of the underlying model.