 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-Consistent Metal Segmentation in the Projection Domain for Metal Artifact Reduction in CBCT -- An Investigation of Potential Improvement
Dec 03, 2021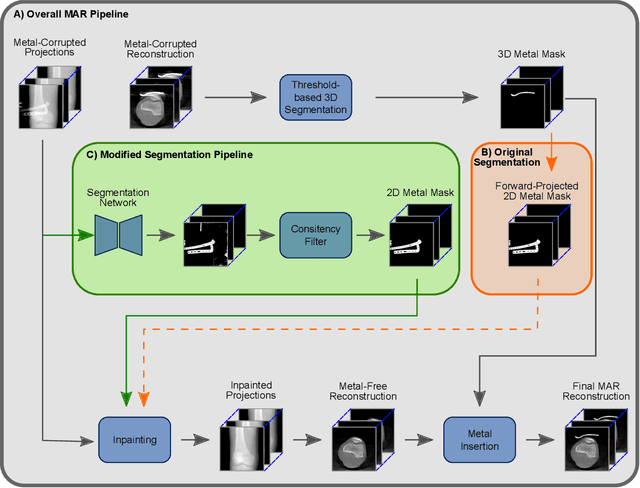
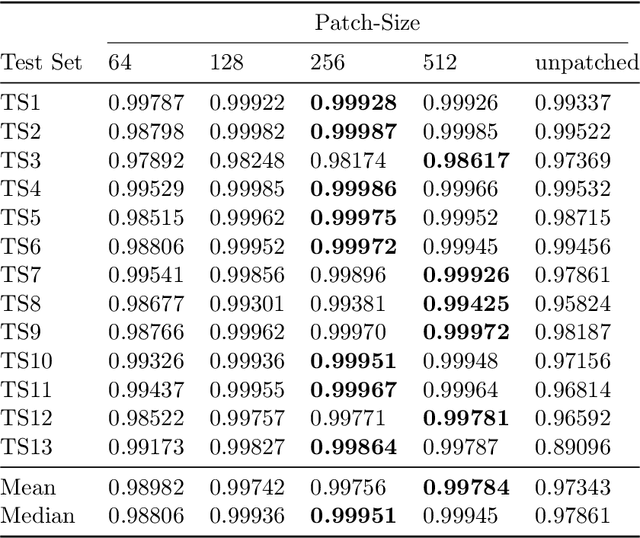
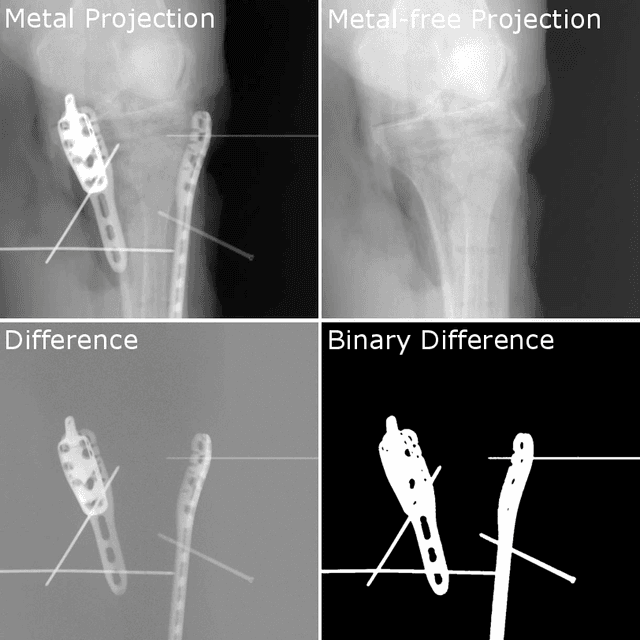
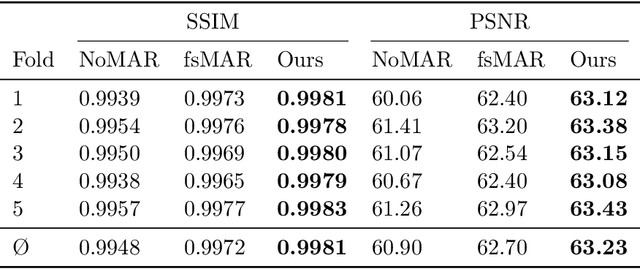
The positive outcome of a trauma intervention depends on an intraoperative evaluation of inserted metallic implants. Due to occurring metal artifacts, the quality of this evaluation heavily depends on the performance of so-called Metal Artifact Reduction methods (MAR). The majority of these MAR methods require prior segmentation of the inserted metal objects. Therefore, typically a rather simple thresholding-based segmentation method in the reconstructed 3D volume is applied, despite some major disadvantages. With this publication, the potential of shifting the segmentation task to a learning-based, view-consistent 2D projection-based method on the downstream MAR's outcome is investigated. For segmenting the present metal, a rather simple learning-based 2D projection-wise segmentation network that is trained using real data acquired during cadaver studies, is examined. To overcome the disadvantages that come along with a 2D projection-wise segmentation, a Consistency Filter is proposed. The influence of the shifted segmentation domain is investigated by comparing the results of the standard fsMAR with a modified fsMAR version using the new segmentation masks. With a quantitative and qualitative evaluation on real cadaver data, the investigated approach showed an increased MAR performance and a high insensitivity against metal artifacts. For cases with metal outside the reconstruction's FoV or cases with vanishing metal, a significant reduction in artifacts could be shown. Thus, increases of up to roughly 3 dB w.r.t. the mean PSNR metric over all slices and up to 9 dB for single slices were achieved. The shown results reveal a beneficial influence of the shift to a 2D-based segmentation method on real data for downstream use with a MAR method, like the fsMAR.
Prediction of Household-level Heat-Consumption using PSO enhanced SVR Model
Dec 03, 2021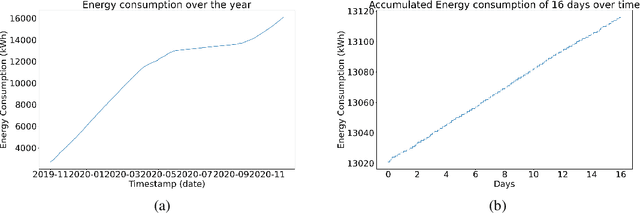
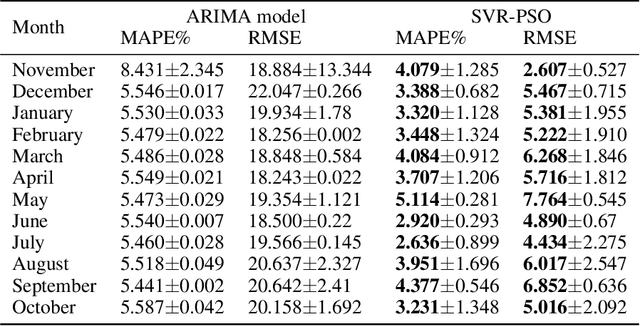
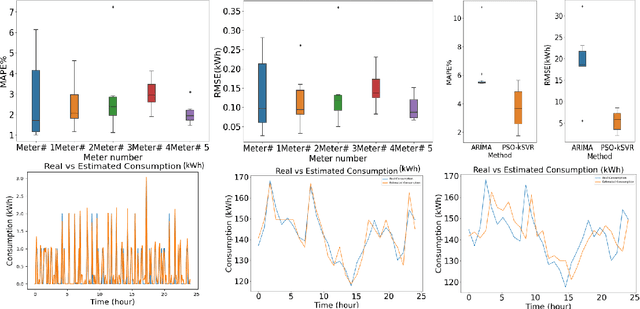
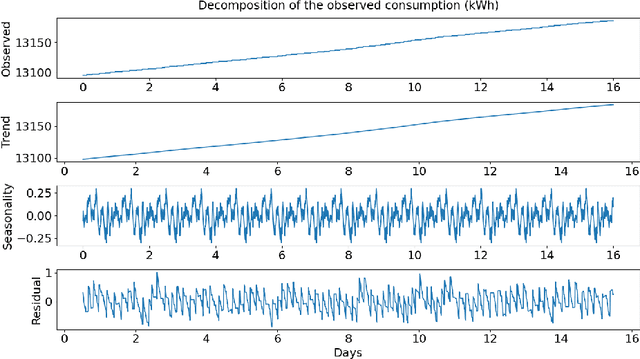
In combating climate change, an effective demand-based energy supply operation of the district energy system (DES) for heating or cooling is indispensable. As a consequence, an accurate forecast of heat consumption on the consumer side poses an important first step towards an optimal energy supply. However, due to the non-linearity and non-stationarity of heat consumption data, the prediction of the thermal energy demand of DES remains challenging. In this work, we propose a forecasting framework for thermal energy consumption within a district heating system (DHS) based on kernel Support Vector Regression (kSVR) using real-world smart meter data. Particle Swarm Optimization (PSO) is employed to find the optimal hyper-parameter for the kSVR model which leads to the superiority of the proposed methods when compared to a state-of-the-art ARIMA model. The average MAPE is reduced to 2.07% and 2.64% for the individual meter-specific forecasting and for forecasting of societal consumption, respectively.
Towards Super-Resolution CEST MRI for Visualization of Small Structures
Dec 03, 2021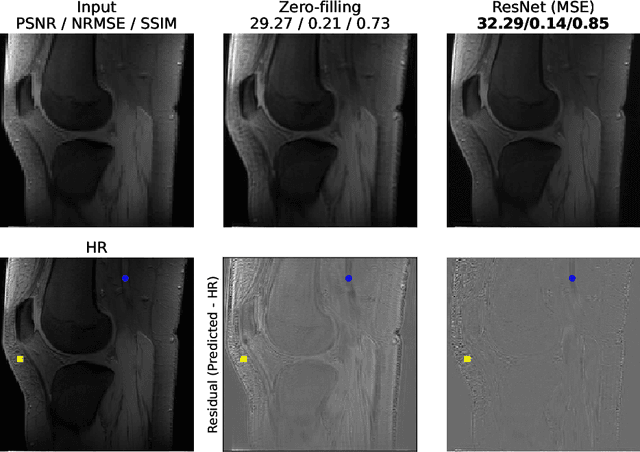
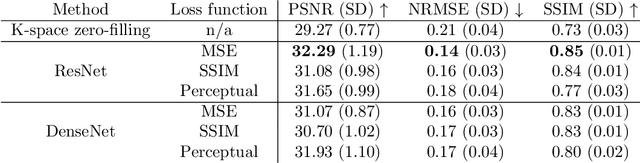
The onset of rheumatic diseases such as rheumatoid arthritis is typically subclinical, which results in challenging early detection of the disease. However, characteristic changes in the anatomy can be detected using imaging techniques such as MRI or CT. Modern imaging techniques such as chemical exchange saturation transfer (CEST) MRI drive the hope to improve early detection even further through the imaging of metabolites in the body. To image small structures in the joints of patients, typically one of the first regions where changes due to the disease occur, a high resolution for the CEST MR imaging is necessary. Currently, however, CEST MR suffers from an inherently low resolution due to the underlying physical constraints of the acquisition. In this work we compared established up-sampling techniques to neural network-based super-resolution approaches. We could show, that neural networks are able to learn the mapping from low-resolution to high-resolution unsaturated CEST images considerably better than present methods. On the test set a PSNR of 32.29dB (+10%), a NRMSE of 0.14 (+28%), and a SSIM of 0.85 (+15%) could be achieved using a ResNet neural network, improving the baseline considerably. This work paves the way for the prospective investigation of neural networks for super-resolution CEST MRI and, followingly, might lead to a earlier detection of the onset of rheumatic diseases.
First steps on Gamification of Lung Fluid Cells Annotations in the Flower Domain
Nov 05, 2021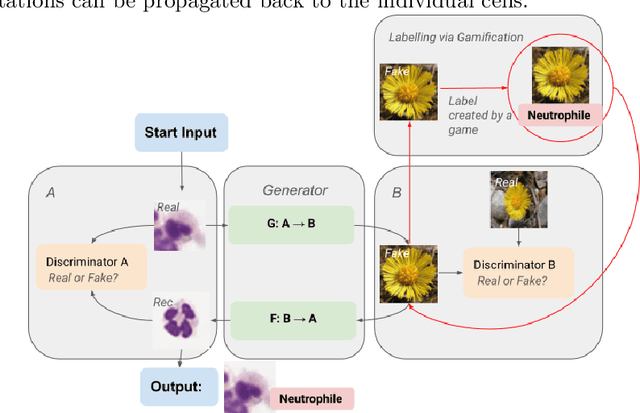

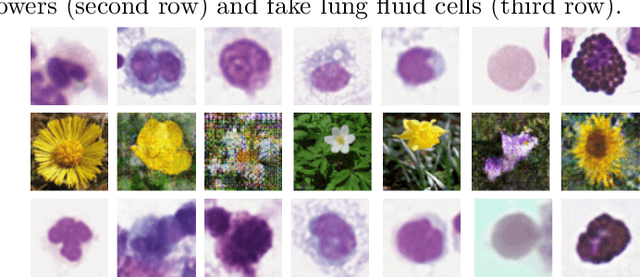
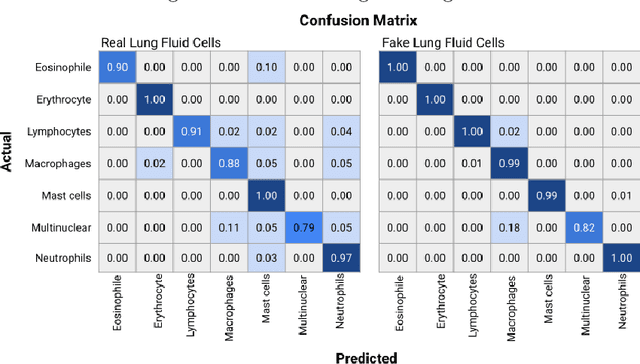
Annotating data, especially in the medical domain, requires expert knowledge and a lot of effort. This limits the amount and/or usefulness of available medical data sets for experimentation. Therefore, developing strategies to increase the number of annotations while lowering the needed domain knowledge is of interest. A possible strategy is the use of gamification, that is i.e. transforming the annotation task into a game. We propose an approach to gamify the task of annotating lung fluid cells from pathological whole slide images. As this domain is unknown to non-expert annotators, we transform images of cells detected with a RetinaNet architecture to the domain of flower images. This domain transfer is performed with a CycleGAN architecture for different cell types. In this more assessable domain, non-expert annotators can be (t)asked to annotate different kinds of flowers in a playful setting. In order to provide a proof of concept, this work shows that the domain transfer is possible by evaluating an image classification network trained on real cell images and tested on the cell images generated by the CycleGAN network. The classification network reaches an accuracy of 97.48% and 95.16% on the original lung fluid cells and transformed lung fluid cells, respectively. With this study, we lay the foundation for future research on gamification using CycleGANs.
DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering
Oct 11, 2021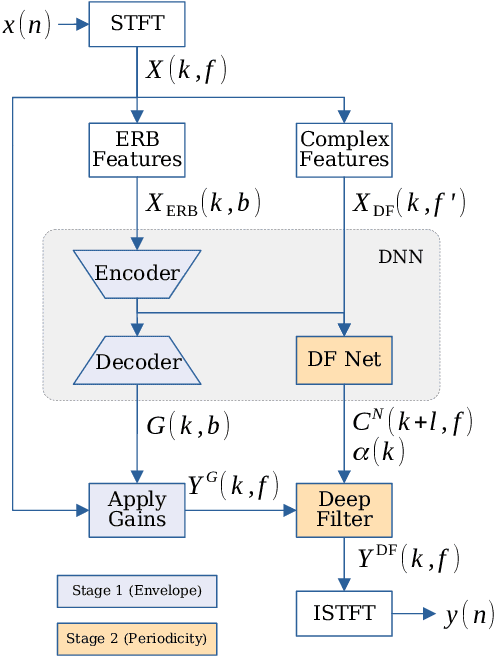
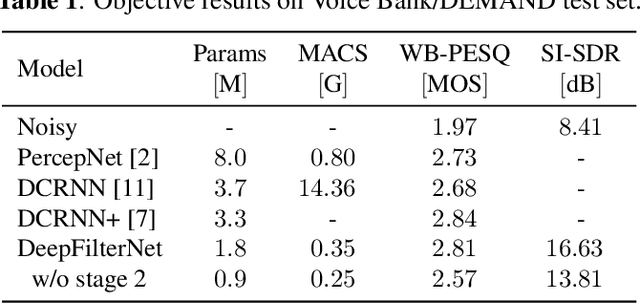
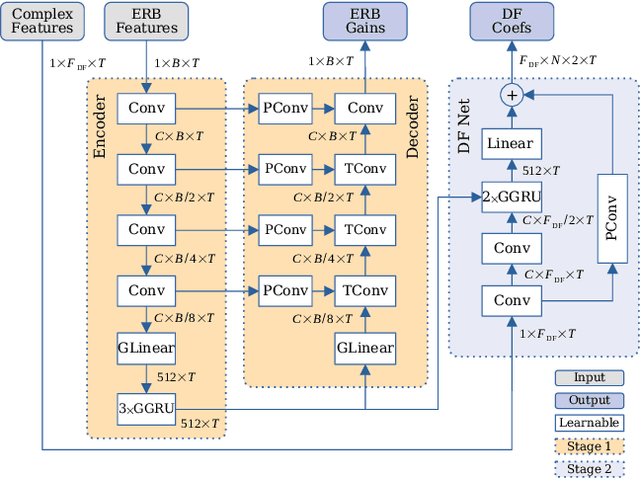
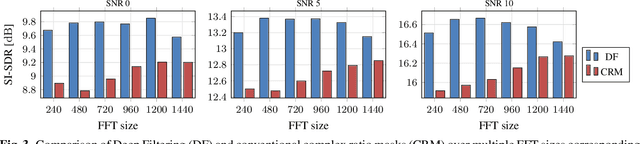
Complex-valued processing has brought deep learning-based speech enhancement and signal extraction to a new level. Typically, the process is based on a time-frequency (TF) mask which is applied to a noisy spectrogram, while complex masks (CM) are usually preferred over real-valued masks due to their ability to modify the phase. Recent work proposed to use a complex filter instead of a point-wise multiplication with a mask. This allows to incorporate information from previous and future time steps exploiting local correlations within each frequency band. In this work, we propose DeepFilterNet, a two stage speech enhancement framework utilizing deep filtering. First, we enhance the spectral envelope using ERB-scaled gains modeling the human frequency perception. The second stage employs deep filtering to enhance the periodic components of speech. Additionally to taking advantage of perceptual properties of speech, we enforce network sparsity via separable convolutions and extensive grouping in linear and recurrent layers to design a low complexity architecture. We further show that our two stage deep filtering approach outperforms complex masks over a variety of frequency resolutions and latencies and demonstrate convincing performance compared to other state-of-the-art models.
Automatic Plane Adjustment of Orthopedic Intra-operative Flat Panel Detector CT-Volumes
Sep 15, 2021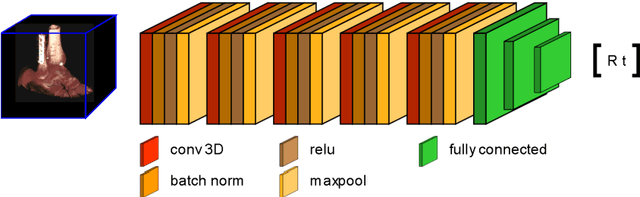

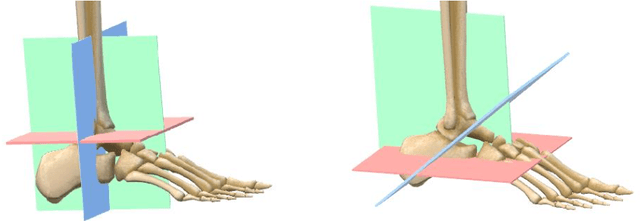
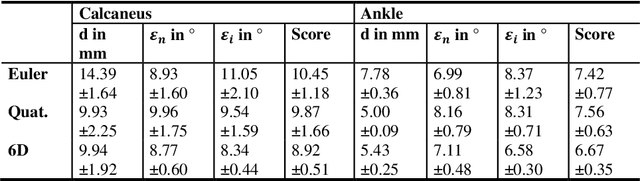
Purpose 3D acquisitions are often acquired to assess the result in orthopedic trauma surgery. With a mobile C-Arm system, these acquisitions can be performed intra-operatively. That reduces the number of required revision surgeries. However, due to the operation room setup, the acquisitions typically cannot be performed such that the acquired volumes are aligned to the anatomical regions. Thus, the multiplanar reconstructed (MPR) planes need to be adjusted manually during the review of the volume. In this paper, we present a detailed study of multi-task learning (MTL) regression networks to estimate the parameters of the MPR planes. Approach First, various mathematical descriptions for rotation, including Euler angle, quaternion, and matrix representation, are revised. Then, three different MTL network architectures based on the PoseNet are compared with a single task learning network. Results Using a matrix description rather than the Euler angle description, the accuracy of the regressed normals improves from $7.7^{\circ}$ to $7.3^{\circ}$ in the mean value for single anatomies. The multi-head approach improves the regression of the plane position from $7.4mm$ to $6.1mm$, while the orientation does not benefit from this approach. Conclusions The results show that a multi-head approach can lead to slightly better results than the individual tasks networks. The most important benefit of the MTL approach is that it is a single network for standard plane regression for all body regions with a reduced number of stored parameters.
Automated Cardiac Resting Phase Detection Targeted on the Right Coronary Artery
Sep 06, 2021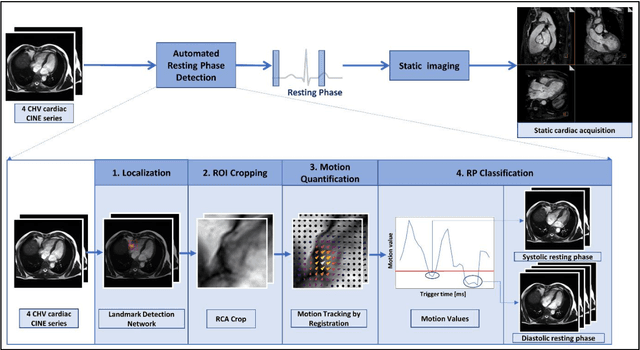
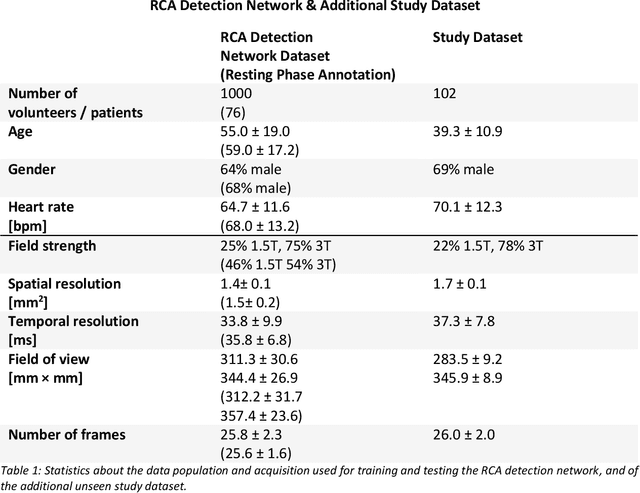
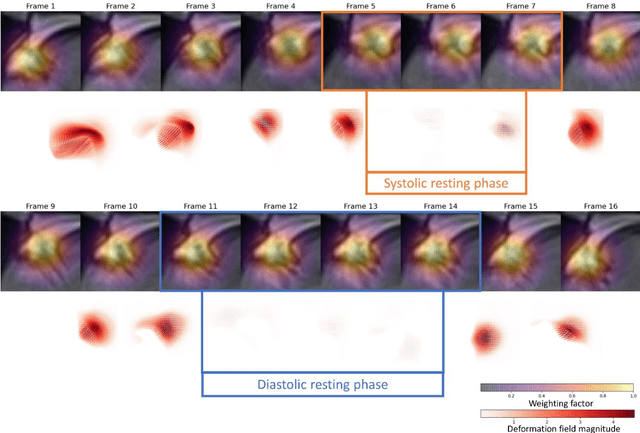
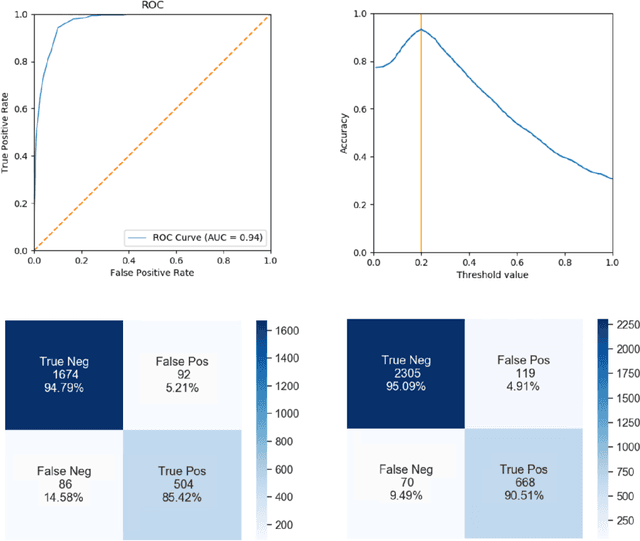
Purpose: Static cardiac imaging such as late gadolinium enhancement, mapping, or 3-D coronary angiography require prior information, e.g., the phase during a cardiac cycle with least motion, called resting phase (RP). The purpose of this work is to propose a fully automated framework that allows the detection of the right coronary artery (RCA) RP within CINE series. Methods: The proposed prototype system consists of three main steps. First, the localization of the regions of interest (ROI) is performed. Second, as CINE series are time-resolved, the cropped ROI series over all time points are taken for tracking motions quantitatively. Third, the output motion values are used to classify RPs. In this work, we focused on the detection of the area with the outer edge of the cross-section of the RCA as our target. The proposed framework was evaluated on 102 clinically acquired dataset at 1.5T and 3T. The automatically classified RPs were compared with the ground truth RPs annotated manually by a medical expert for testing the robustness and feasibility of the framework. Results: The predicted RCA RPs showed high agreement with the experts annotated RPs with 92.7% accuracy, 90.5% sensitivity and 95.0% specificity for the unseen study dataset. The mean absolute difference of the start and end RP was 13.6 ${\pm}$ 18.6 ms for the validation study dataset (n=102). Conclusion: In this work, automated RP detection has been introduced by the proposed framework and demonstrated feasibility, robustness, and applicability for diverse static imaging acquisitions.
Fiducial marker recovery and detection from severely truncated data in navigation assisted spine surgery
Sep 01, 2021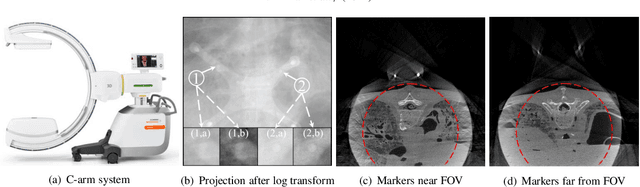
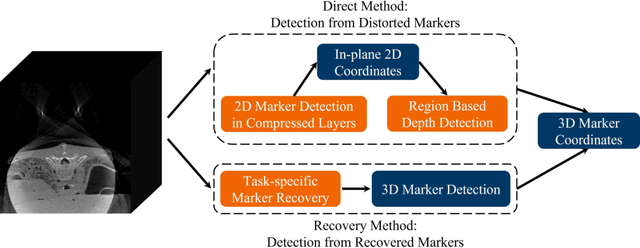

Fiducial markers are commonly used in navigation assisted minimally invasive spine surgery (MISS) and they help transfer image coordinates into real world coordinates. In practice, these markers might be located outside the field-of-view (FOV), due to the limited detector sizes of C-arm cone-beam computed tomography (CBCT) systems used in intraoperative surgeries. As a consequence, reconstructed markers in CBCT volumes suffer from artifacts and have distorted shapes, which sets an obstacle for navigation. In this work, we propose two fiducial marker detection methods: direct detection from distorted markers (direct method) and detection after marker recovery (recovery method). For direct detection from distorted markers in reconstructed volumes, an efficient automatic marker detection method using two neural networks and a conventional circle detection algorithm is proposed. For marker recovery, a task-specific learning strategy is proposed to recover markers from severely truncated data. Afterwards, a conventional marker detection algorithm is applied for position detection. The two methods are evaluated on simulated data and real data, both achieving a marker registration error smaller than 0.2 mm. Our experiments demonstrate that the direct method is capable of detecting distorted markers accurately and the recovery method with task-specific learning has high robustness and generalizability on various data sets. In addition, the task-specific learning is able to reconstruct other structures of interest accurately, e.g. ribs for image-guided needle biopsy, from severely truncated data, which empowers CBCT systems with new potential applications.
Module-Power Prediction from PL Measurements using Deep Learning
Aug 31, 2021
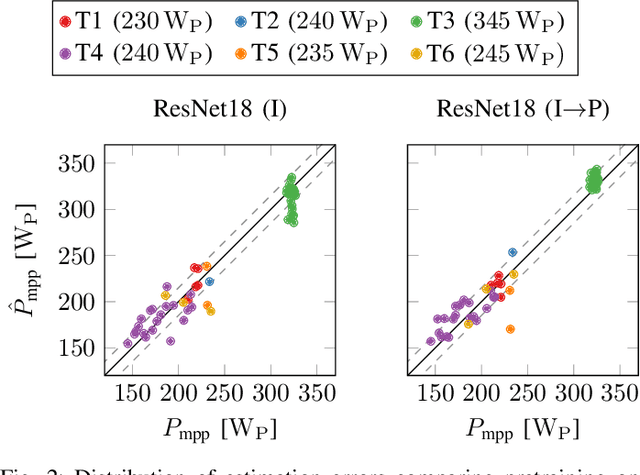
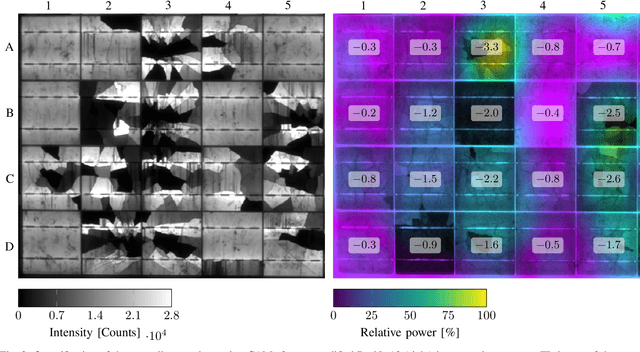
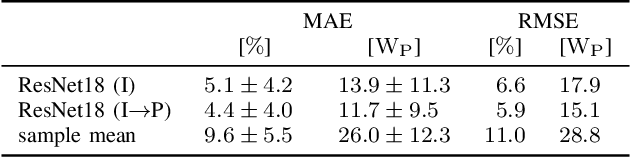
The individual causes for power loss of photovoltaic modules are investigated for quite some time. Recently, it has been shown that the power loss of a module is, for example, related to the fraction of inactive areas. While these areas can be easily identified from electroluminescense (EL) images, this is much harder for photoluminescence (PL) images. With this work, we close the gap between power regression from EL and PL images. We apply a deep convolutional neural network to predict the module power from PL images with a mean absolute error (MAE) of 4.4% or 11.7WP. Furthermore, we depict that regression maps computed from the embeddings of the trained network can be used to compute the localized power loss. Finally, we show that these regression maps can be used to identify inactive regions in PL images as well.
InSE-NET: A Perceptually Coded Audio Quality Model based on CNN
Aug 30, 2021
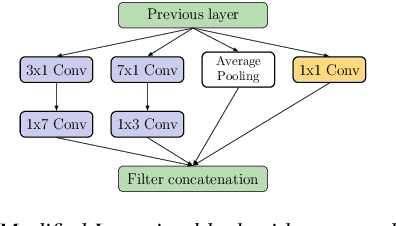
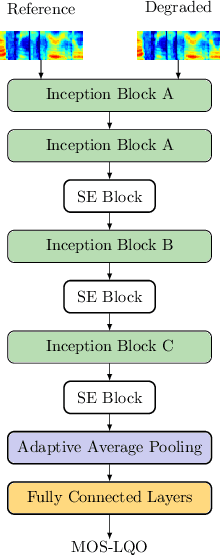
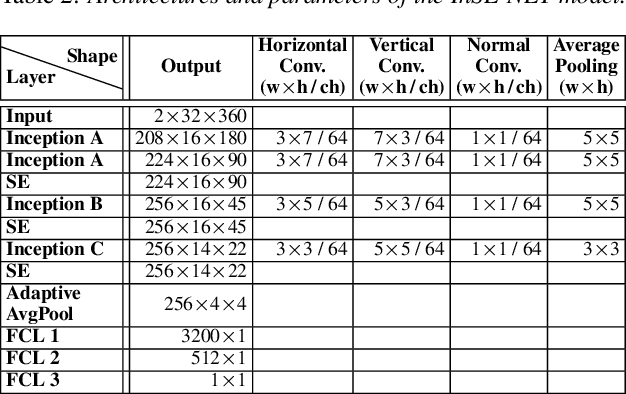
Automatic coded audio quality assessment is an important task whose progress is hampered by the scarcity of human annotations, poor generalization to unseen codecs, bitrates, content-types, and a lack of flexibility of existing approaches. One of the typical human-perception-related metrics, ViSQOL v3 (ViV3), has been proven to provide a high correlation to the quality scores rated by humans. In this study, we take steps to tackle problems of predicting coded audio quality by completely utilizing programmatically generated data that is informed with expert domain knowledge. We propose a learnable neural network, entitled InSE-NET, with a backbone of Inception and Squeeze-and-Excitation modules to assess the perceived quality of coded audio at a 48kHz sample rate. We demonstrate that synthetic data augmentation is capable of enhancing the prediction. Our proposed method is intrusive, i.e. it requires Gammatone spectrograms of unencoded reference signals. Besides a comparable performance to ViV3, our approach provides a more robust prediction towards higher bitrates.