 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning on Hidden-Convex Losses via Algorithmic Equivalence: Optimal Regret, Geometric Barrier, and Bandit Feedback
May 25, 2026We study adversarial online learning with hidden-convex losses, i.e., nonconvex losses that become convex after a nonlinear reparameterization. Ghai, Lu and Hazan (2022) proved that, under geometric and smoothness assumptions, online gradient descent (OGD) on such nonconvex losses approximately simulates online mirror descent (OMD) on the underlying convex losses with a suitable regularizer, yielding $\mathcal{O}(T^{2/3})$ regret. They left open whether the optimal $Θ(\sqrt{T})$ regret from online convex optimization can be recovered in this hidden-convex setting. We answer this question affirmatively. More specifically, via a sharper discrete-time algorithmic equivalence argument, we prove that OGD achieves $\mathcal{O}(\sqrt{T})$ regret under the same assumptions, matching the optimal worst-case rate for adversarial online convex optimization. We also address another open question of Ghai, Lu and Hazan (2022) by clarifying the geometry required for this algorithmic equivalence. We replace the diagonal-Jacobian sufficient condition with a necessary-and-sufficient Hessian compatibility condition, thereby expanding the class of admissible reparameterizations. We complement our tight regret bound with a lower bound showing that the Hessian compatibility assumption is essential for OGD; when it fails, we construct a smooth reparameterization and an adversarial sequence of hidden-convex losses for which OGD suffers $Ω(T)$ regret. Finally, we extend our analysis to one-point bandit feedback and prove a $\mathcal{O}(T^{3/4})$ expected regret bound for bandit OGD with spherical smoothing, matching its classical rate on convex losses.
Efficient Swap Regret Minimization in Combinatorial Bandits
Feb 02, 2026This paper addresses the problem of designing efficient no-swap regret algorithms for combinatorial bandits, where the number of actions $N$ is exponentially large in the dimensionality of the problem. In this setting, designing efficient no-swap regret translates to sublinear -- in horizon $T$ -- swap regret with polylogarithmic dependence on $N$. In contrast to the weaker notion of external regret minimization - a problem which is fairly well understood in the literature - achieving no-swap regret with a polylogarithmic dependence on $N$ has remained elusive in combinatorial bandits. Our paper resolves this challenge, by introducing a no-swap-regret learning algorithm with regret that scales polylogarithmically in $N$ and is tight for the class of combinatorial bandits. To ground our results, we also demonstrate how to implement the proposed algorithm efficiently -- that is, with a per-iteration complexity that also scales polylogarithmically in $N$ -- across a wide range of well-studied applications.
Enhancing Cooperative Multi-Agent Reinforcement Learning with State Modelling and Adversarial Exploration
May 08, 2025



Learning to cooperate in distributed partially observable environments with no communication abilities poses significant challenges for multi-agent deep reinforcement learning (MARL). This paper addresses key concerns in this domain, focusing on inferring state representations from individual agent observations and leveraging these representations to enhance agents' exploration and collaborative task execution policies. To this end, we propose a novel state modelling framework for cooperative MARL, where agents infer meaningful belief representations of the non-observable state, with respect to optimizing their own policies, while filtering redundant and less informative joint state information. Building upon this framework, we propose the MARL SMPE algorithm. In SMPE, agents enhance their own policy's discriminative abilities under partial observability, explicitly by incorporating their beliefs into the policy network, and implicitly by adopting an adversarial type of exploration policies which encourages agents to discover novel, high-value states while improving the discriminative abilities of others. Experimentally, we show that SMPE outperforms state-of-the-art MARL algorithms in complex fully cooperative tasks from the MPE, LBF, and RWARE benchmarks.
An Extended Benchmarking of Multi-Agent Reinforcement Learning Algorithms in Complex Fully Cooperative Tasks
Feb 07, 2025



Multi-Agent Reinforcement Learning (MARL) has recently emerged as a significant area of research. However, MARL evaluation often lacks systematic diversity, hindering a comprehensive understanding of algorithms' capabilities. In particular, cooperative MARL algorithms are predominantly evaluated on benchmarks such as SMAC and GRF, which primarily feature team game scenarios without assessing adequately various aspects of agents' capabilities required in fully cooperative real-world tasks such as multi-robot cooperation and warehouse, resource management, search and rescue, and human-AI cooperation. Moreover, MARL algorithms are mainly evaluated on low dimensional state spaces, and thus their performance on high-dimensional (e.g., image) observations is not well-studied. To fill this gap, this paper highlights the crucial need for expanding systematic evaluation across a wider array of existing benchmarks. To this end, we conduct extensive evaluation and comparisons of well-known MARL algorithms on complex fully cooperative benchmarks, including tasks with images as agents' observations. Interestingly, our analysis shows that many algorithms, hailed as state-of-the-art on SMAC and GRF, may underperform standard MARL baselines on fully cooperative benchmarks. Finally, towards more systematic and better evaluation of cooperative MARL algorithms, we have open-sourced PyMARLzoo+, an extension of the widely used (E)PyMARL libraries, which addresses an open challenge from [TBG++21], facilitating seamless integration and support with all benchmarks of PettingZoo, as well as Overcooked, PressurePlate, Capture Target and Box Pushing.
XDQN: Inherently Interpretable DQN through Mimicking
Jan 08, 2023



Although deep reinforcement learning (DRL) methods have been successfully applied in challenging tasks, their application in real-world operational settings is challenged by methods' limited ability to provide explanations. Among the paradigms for explainability in DRL is the interpretable box design paradigm, where interpretable models substitute inner constituent models of the DRL method, thus making the DRL method "inherently" interpretable. In this paper we explore this paradigm and we propose XDQN, an explainable variation of DQN, which uses an interpretable policy model trained through mimicking. XDQN is challenged in a complex, real-world operational multi-agent problem, where agents are independent learners solving congestion problems. Specifically, XDQN is evaluated in three MARL scenarios, pertaining to the demand-capacity balancing problem of air traffic management. XDQN achieves performance similar to that of DQN, while its abilities to provide global models' interpretations and interpretations of local decisions are demonstrated.
Tree-based Focused Web Crawling with Reinforcement Learning
Dec 12, 2021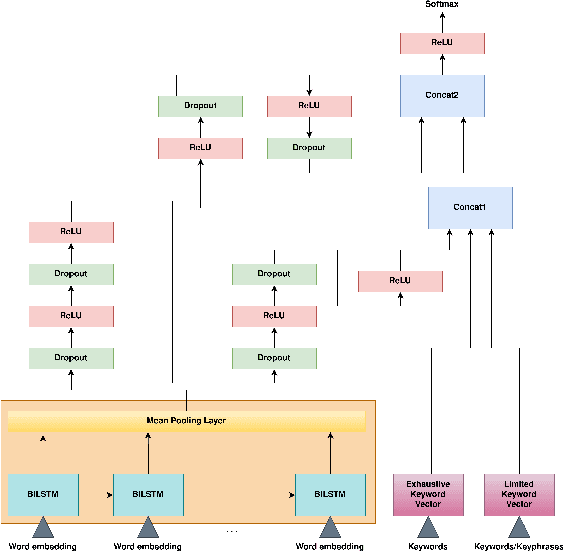

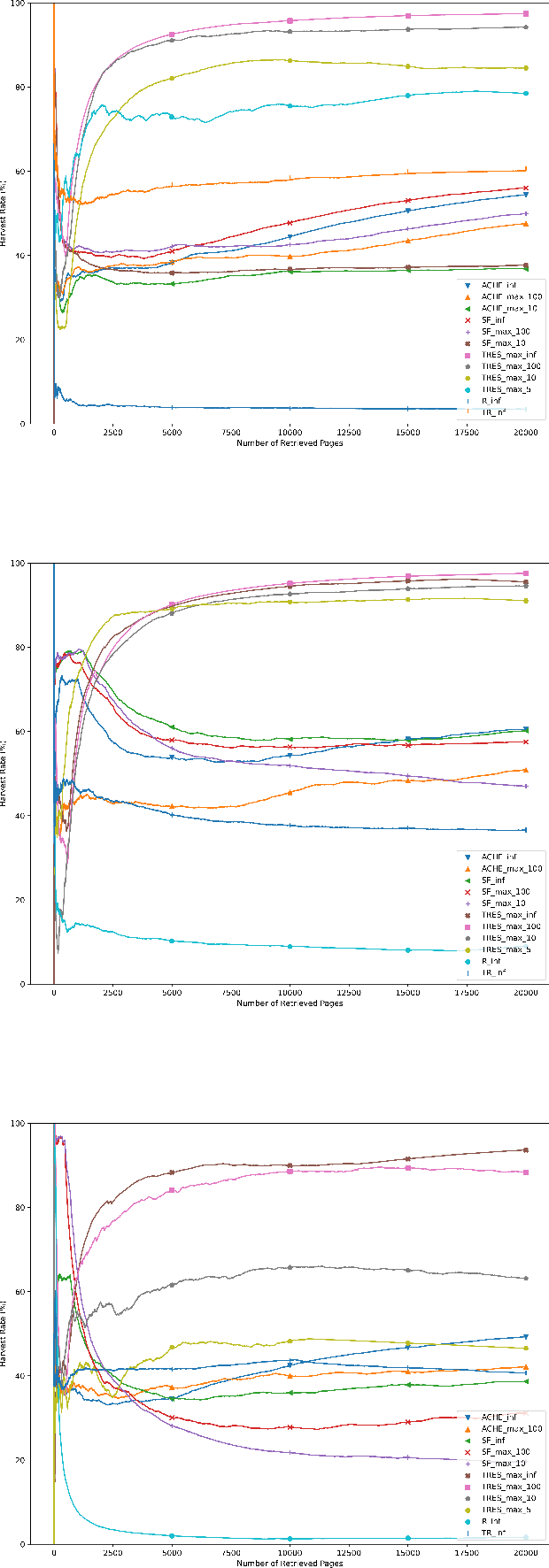
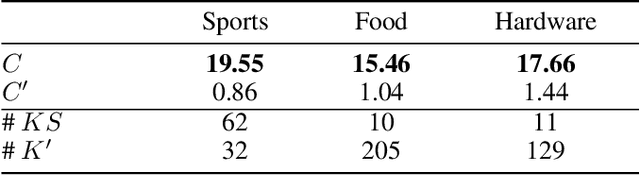
A focused crawler aims at discovering as many web pages relevant to a target topic as possible, while avoiding irrelevant ones; i.e. maximizing the harvest rate. Reinforcement Learning (RL) has been utilized to optimize the crawling process, yet it deals with huge state and action spaces, which can constitute a serious challenge. In this paper, we propose TRES, an end-to-end RL-empowered framework for focused crawling. Unlike other approaches, we properly model a crawling environment as a Markov Decision Process, by representing the state as a subgraph of the Web and actions as its expansion edges. TRES adopts a keyword expansion strategy based on the cosine similarity of keyword embeddings. To learn a reward function, we propose a deep neural network, called KwBiLSTM, leveraging the discovered keywords. To reduce the time complexity of selecting a best action, we propose Tree-Frontier, a two-fold decision tree, which also speeds up training by discretizing the state and action spaces. Experimentally, we show that TRES outperforms state-of-the-art methods in terms of harvest rate by at least 58%, while it has competitive results in the domain maximization. Our implementation code can be found on https://github.com/ddaedalus/TRES.