 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicPony: Learning Articulated 3D Animals in the Wild
Nov 22, 2022We consider the problem of learning a function that can estimate the 3D shape, articulation, viewpoint, texture, and lighting of an articulated animal like a horse, given a single test image. We present a new method, dubbed MagicPony, that learns this function purely from in-the-wild single-view images of the object category, with minimal assumptions about the topology of deformation. At its core is an implicit-explicit representation of articulated shape and appearance, combining the strengths of neural fields and meshes. In order to help the model understand an object's shape and pose, we distil the knowledge captured by an off-the-shelf self-supervised vision transformer and fuse it into the 3D model. To overcome common local optima in viewpoint estimation, we further introduce a new viewpoint sampling scheme that comes at no added training cost. Compared to prior works, we show significant quantitative and qualitative improvements on this challenging task. The model also demonstrates excellent generalisation in reconstructing abstract drawings and artefacts, despite the fact that it is only trained on real images.
Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable Categories
Nov 07, 2022



Obtaining photorealistic reconstructions of objects from sparse views is inherently ambiguous and can only be achieved by learning suitable reconstruction priors. Earlier works on sparse rigid object reconstruction successfully learned such priors from large datasets such as CO3D. In this paper, we extend this approach to dynamic objects. We use cats and dogs as a representative example and introduce Common Pets in 3D (CoP3D), a collection of crowd-sourced videos showing around 4,200 distinct pets. CoP3D is one of the first large-scale datasets for benchmarking non-rigid 3D reconstruction "in the wild". We also propose Tracker-NeRF, a method for learning 4D reconstruction from our dataset. At test time, given a small number of video frames of an unseen object, Tracker-NeRF predicts the trajectories of its 3D points and generates new views, interpolating viewpoint and time. Results on CoP3D reveal significantly better non-rigid new-view synthesis performance than existing baselines.
Neural Feature Fusion Fields: 3D Distillation of Self-Supervised 2D Image Representations
Sep 07, 2022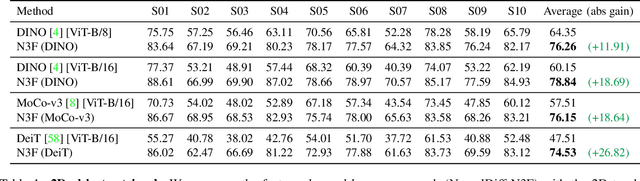
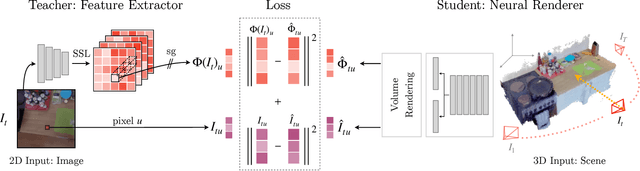


We present Neural Feature Fusion Fields (N3F), a method that improves dense 2D image feature extractors when the latter are applied to the analysis of multiple images reconstructible as a 3D scene. Given an image feature extractor, for example pre-trained using self-supervision, N3F uses it as a teacher to learn a student network defined in 3D space. The 3D student network is similar to a neural radiance field that distills said features and can be trained with the usual differentiable rendering machinery. As a consequence, N3F is readily applicable to most neural rendering formulations, including vanilla NeRF and its extensions to complex dynamic scenes. We show that our method not only enables semantic understanding in the context of scene-specific neural fields without the use of manual labels, but also consistently improves over the self-supervised 2D baselines. This is demonstrated by considering various tasks, such as 2D object retrieval, 3D segmentation, and scene editing, in diverse sequences, including long egocentric videos in the EPIC-KITCHENS benchmark.
Measuring the Interpretability of Unsupervised Representations via Quantized Reverse Probing
Sep 07, 2022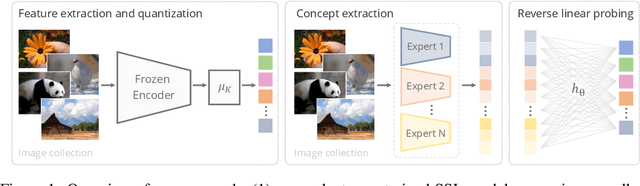

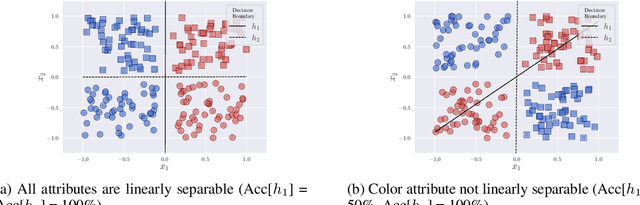
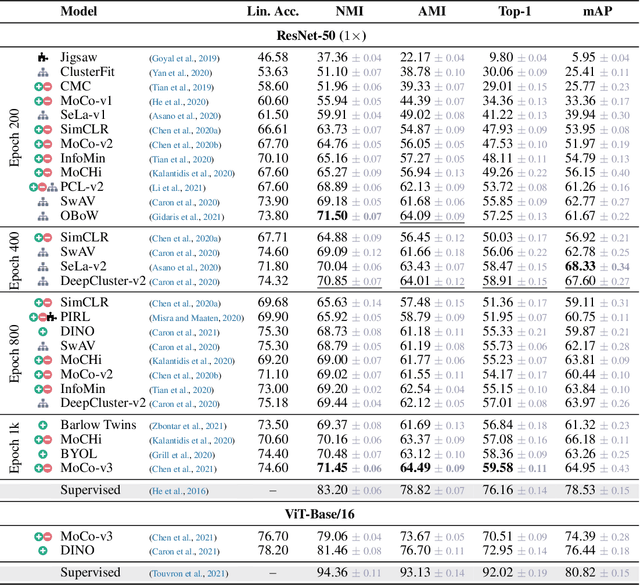
Self-supervised visual representation learning has recently attracted significant research interest. While a common way to evaluate self-supervised representations is through transfer to various downstream tasks, we instead investigate the problem of measuring their interpretability, i.e. understanding the semantics encoded in raw representations. We formulate the latter as estimating the mutual information between the representation and a space of manually labelled concepts. To quantify this we introduce a decoding bottleneck: information must be captured by simple predictors, mapping concepts to clusters in representation space. This approach, which we call reverse linear probing, provides a single number sensitive to the semanticity of the representation. This measure is also able to detect when the representation contains combinations of concepts (e.g., "red apple") instead of just individual attributes ("red" and "apple" independently). Finally, we propose to use supervised classifiers to automatically label large datasets in order to enrich the space of concepts used for probing. We use our method to evaluate a large number of self-supervised representations, ranking them by interpretability, highlight the differences that emerge compared to the standard evaluation with linear probes and discuss several qualitative insights. Code at: {\scriptsize{\url{https://github.com/iro-cp/ssl-qrp}}}.
SNeS: Learning Probably Symmetric Neural Surfaces from Incomplete Data
Jun 13, 2022
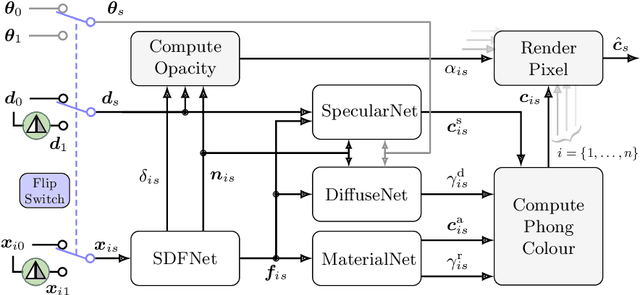
We present a method for the accurate 3D reconstruction of partly-symmetric objects. We build on the strengths of recent advances in neural reconstruction and rendering such as Neural Radiance Fields (NeRF). A major shortcoming of such approaches is that they fail to reconstruct any part of the object which is not clearly visible in the training image, which is often the case for in-the-wild images and videos. When evidence is lacking, structural priors such as symmetry can be used to complete the missing information. However, exploiting such priors in neural rendering is highly non-trivial: while geometry and non-reflective materials may be symmetric, shadows and reflections from the ambient scene are not symmetric in general. To address this, we apply a soft symmetry constraint to the 3D geometry and material properties, having factored appearance into lighting, albedo colour and reflectivity. We evaluate our method on the recently introduced CO3D dataset, focusing on the car category due to the challenge of reconstructing highly-reflective materials. We show that it can reconstruct unobserved regions with high fidelity and render high-quality novel view images.
Guess What Moves: Unsupervised Video and Image Segmentation by Anticipating Motion
May 16, 2022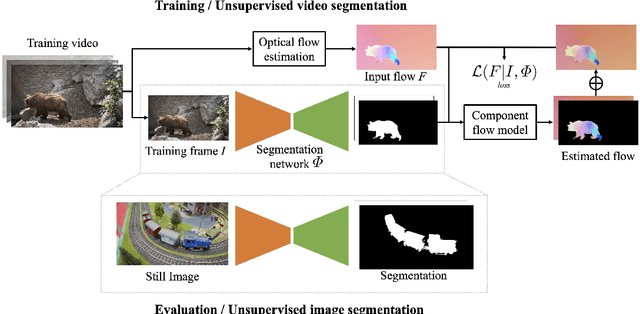
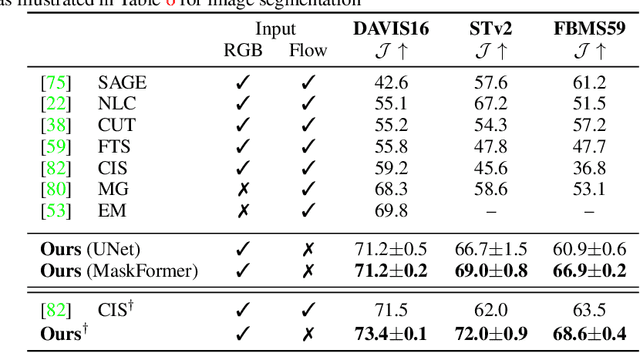

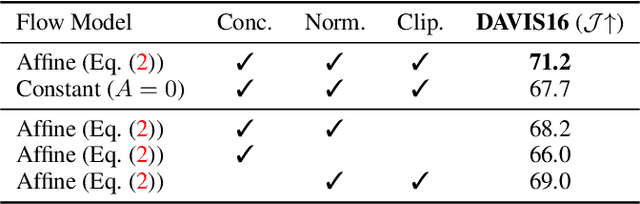
Motion, measured via optical flow, provides a powerful cue to discover and learn objects in images and videos. However, compared to using appearance, it has some blind spots, such as the fact that objects become invisible if they do not move. In this work, we propose an approach that combines the strengths of motion-based and appearance-based segmentation. We propose to supervise an image segmentation network, tasking it with predicting regions that are likely to contain simple motion patterns, and thus likely to correspond to objects. We apply this network in two modes. In the unsupervised video segmentation mode, the network is trained on a collection of unlabelled videos, using the learning process itself as an algorithm to segment these videos. In the unsupervised image segmentation model, the network is learned using videos and applied to segment independent still images. With this, we obtain strong empirical results in unsupervised video and image segmentation, significantly outperforming the state of the art on benchmarks such as DAVIS, sometimes with a $5\%$ IoU gap.
Deep Spectral Methods: A Surprisingly Strong Baseline for Unsupervised Semantic Segmentation and Localization
May 16, 2022
Unsupervised localization and segmentation are long-standing computer vision challenges that involve decomposing an image into semantically-meaningful segments without any labeled data. These tasks are particularly interesting in an unsupervised setting due to the difficulty and cost of obtaining dense image annotations, but existing unsupervised approaches struggle with complex scenes containing multiple objects. Differently from existing methods, which are purely based on deep learning, we take inspiration from traditional spectral segmentation methods by reframing image decomposition as a graph partitioning problem. Specifically, we examine the eigenvectors of the Laplacian of a feature affinity matrix from self-supervised networks. We find that these eigenvectors already decompose an image into meaningful segments, and can be readily used to localize objects in a scene. Furthermore, by clustering the features associated with these segments across a dataset, we can obtain well-delineated, nameable regions, i.e. semantic segmentations. Experiments on complex datasets (Pascal VOC, MS-COCO) demonstrate that our simple spectral method outperforms the state-of-the-art in unsupervised localization and segmentation by a significant margin. Furthermore, our method can be readily used for a variety of complex image editing tasks, such as background removal and compositing.
End-to-End Visual Editing with a Generatively Pre-Trained Artist
May 03, 2022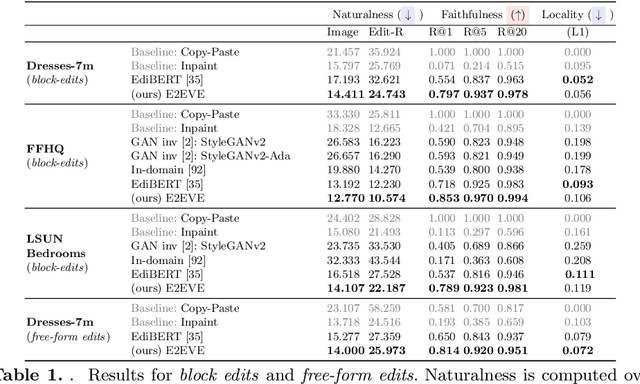

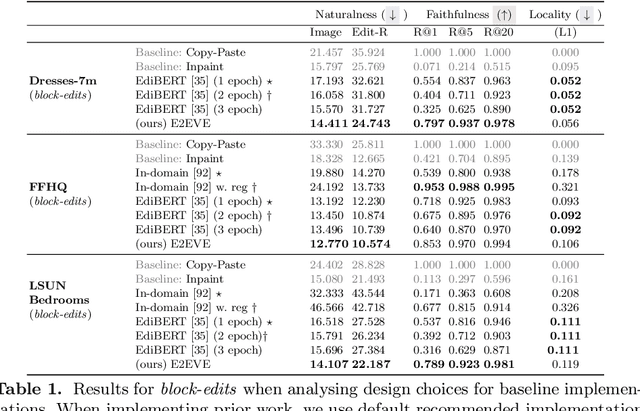
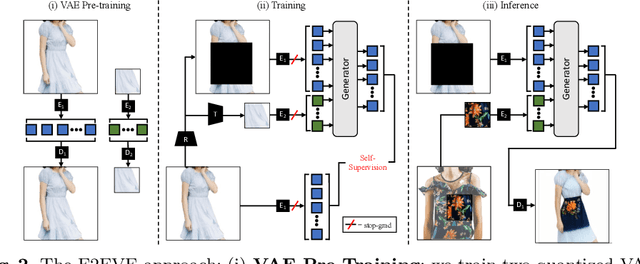
We consider the targeted image editing problem: blending a region in a source image with a driver image that specifies the desired change. Differently from prior works, we solve this problem by learning a conditional probability distribution of the edits, end-to-end. Training such a model requires addressing a fundamental technical challenge: the lack of example edits for training. To this end, we propose a self-supervised approach that simulates edits by augmenting off-the-shelf images in a target domain. The benefits are remarkable: implemented as a state-of-the-art auto-regressive transformer, our approach is simple, sidesteps difficulties with previous methods based on GAN-like priors, obtains significantly better edits, and is efficient. Furthermore, we show that different blending effects can be learned by an intuitive control of the augmentation process, with no other changes required to the model architecture. We demonstrate the superiority of this approach across several datasets in extensive quantitative and qualitative experiments, including human studies, significantly outperforming prior work.
Generalized Category Discovery
Jan 07, 2022
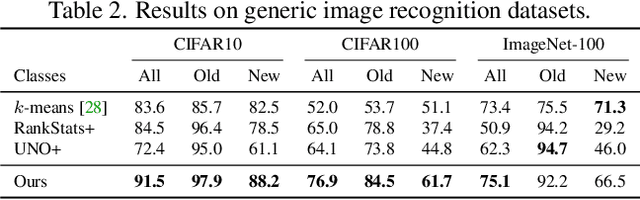

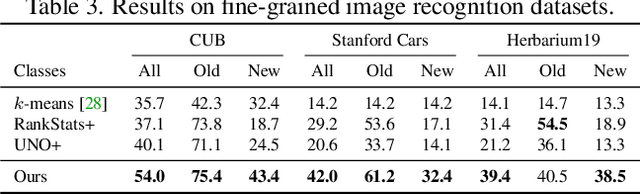
In this paper, we consider a highly general image recognition setting wherein, given a labelled and unlabelled set of images, the task is to categorize all images in the unlabelled set. Here, the unlabelled images may come from labelled classes or from novel ones. Existing recognition methods are not able to deal with this setting, because they make several restrictive assumptions, such as the unlabelled instances only coming from known - or unknown - classes and the number of unknown classes being known a-priori. We address the more unconstrained setting, naming it 'Generalized Category Discovery', and challenge all these assumptions. We first establish strong baselines by taking state-of-the-art algorithms from novel category discovery and adapting them for this task. Next, we propose the use of vision transformers with contrastive representation learning for this open world setting. We then introduce a simple yet effective semi-supervised $k$-means method to cluster the unlabelled data into seen and unseen classes automatically, substantially outperforming the baselines. Finally, we also propose a new approach to estimate the number of classes in the unlabelled data. We thoroughly evaluate our approach on public datasets for generic object classification including CIFAR10, CIFAR100 and ImageNet-100, and for fine-grained visual recognition including CUB, Stanford Cars and Herbarium19, benchmarking on this new setting to foster future research.
BANMo: Building Animatable 3D Neural Models from Many Casual Videos
Dec 24, 2021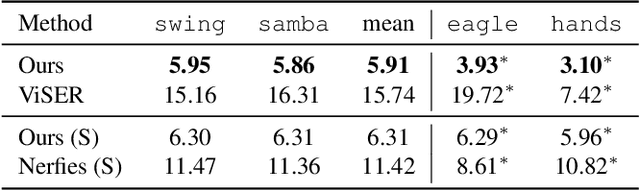
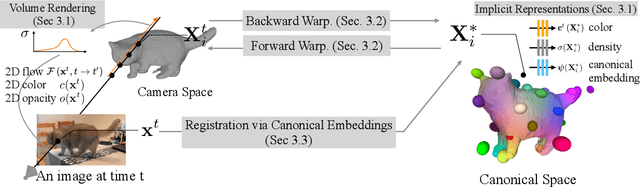

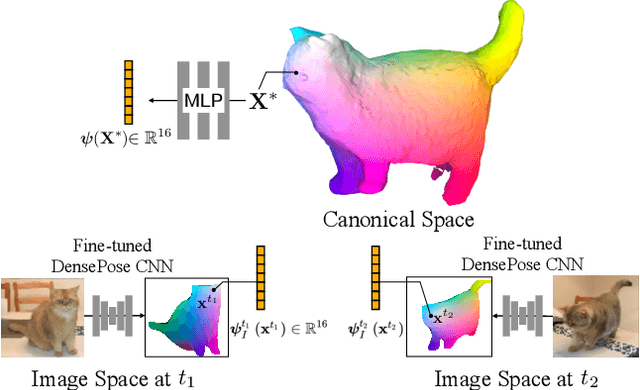
Prior work for articulated 3D shape reconstruction often relies on specialized sensors (e.g., synchronized multi-camera systems), or pre-built 3D deformable models (e.g., SMAL or SMPL). Such methods are not able to scale to diverse sets of objects in the wild. We present BANMo, a method that requires neither a specialized sensor nor a pre-defined template shape. BANMo builds high-fidelity, articulated 3D models (including shape and animatable skinning weights) from many monocular casual videos in a differentiable rendering framework. While the use of many videos provides more coverage of camera views and object articulations, they introduce significant challenges in establishing correspondence across scenes with different backgrounds, illumination conditions, etc. Our key insight is to merge three schools of thought; (1) classic deformable shape models that make use of articulated bones and blend skinning, (2) volumetric neural radiance fields (NeRFs) that are amenable to gradient-based optimization, and (3) canonical embeddings that generate correspondences between pixels and an articulated model. We introduce neural blend skinning models that allow for differentiable and invertible articulated deformations. When combined with canonical embeddings, such models allow us to establish dense correspondences across videos that can be self-supervised with cycle consistency. On real and synthetic datasets, BANMo shows higher-fidelity 3D reconstructions than prior works for humans and animals, with the ability to render realistic images from novel viewpoints and poses. Project webpage: banmo-www.github.io .