 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabelling unlabelled videos from scratch with multi-modal self-supervision
Jun 24, 2020

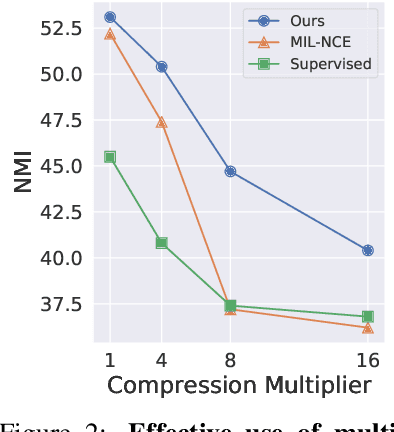
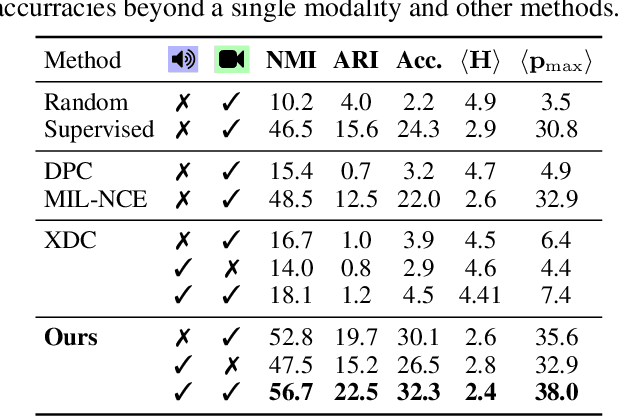
A large part of the current success of deep learning lies in the effectiveness of data -- more precisely: labelled data. Yet, labelling a dataset with human annotation continues to carry high costs, especially for videos. While in the image domain, recent methods have allowed to generate meaningful (pseudo-) labels for unlabelled datasets without supervision, this development is missing for the video domain where learning feature representations is the current focus. In this work, we a) show that unsupervised labelling of a video dataset does not come for free from strong feature encoders and b) propose a novel clustering method that allows pseudo-labelling of a video dataset without any human annotations, by leveraging the natural correspondence between the audio and visual modalities. An extensive analysis shows that the resulting clusters have high semantic overlap to ground truth human labels. We further introduce the first benchmarking results on unsupervised labelling of common video datasets Kinetics, Kinetics-Sound, VGG-Sound and AVE.
LSD-C: Linearly Separable Deep Clusters
Jun 17, 2020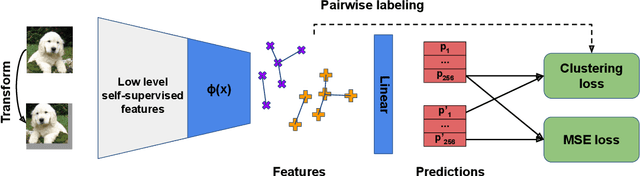



We present LSD-C, a novel method to identify clusters in an unlabeled dataset. Our algorithm first establishes pairwise connections in the feature space between the samples of the minibatch based on a similarity metric. Then it regroups in clusters the connected samples and enforces a linear separation between clusters. This is achieved by using the pairwise connections as targets together with a binary cross-entropy loss on the predictions that the associated pairs of samples belong to the same cluster. This way, the feature representation of the network will evolve such that similar samples in this feature space will belong to the same linearly separated cluster. Our method draws inspiration from recent semi-supervised learning practice and proposes to combine our clustering algorithm with self-supervised pretraining and strong data augmentation. We show that our approach significantly outperforms competitors on popular public image benchmarks including CIFAR 10/100, STL 10 and MNIST, as well as the document classification dataset Reuters 10K.
VGGSound: A Large-scale Audio-Visual Dataset
Apr 29, 2020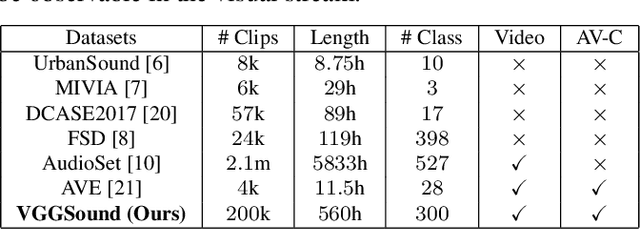
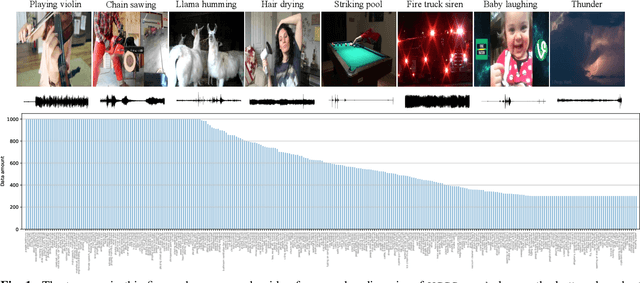

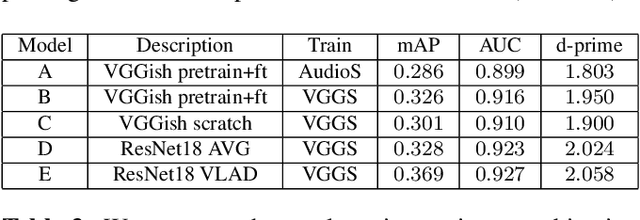
Our goal is to collect a large-scale audio-visual dataset with low label noise from videos in the wild using computer vision techniques. The resulting dataset can be used for training and evaluating audio recognition models. We make three contributions. First, we propose a scalable pipeline based on computer vision techniques to create an audio dataset from open-source media. Our pipeline involves obtaining videos from YouTube; using image classification algorithms to localize audio-visual correspondence; and filtering out ambient noise using audio verification. Second, we use this pipeline to curate the VGGSound dataset consisting of more than 210k videos for 310 audio classes. Third, we investigate various Convolutional Neural Network~(CNN) architectures and aggregation approaches to establish audio recognition baselines for our new dataset. Compared to existing audio datasets, VGGSound ensures audio-visual correspondence and is collected under unconstrained conditions. Code and the dataset are available at http://www.robots.ox.ac.uk/~vgg/data/vggsound/
Fixing the train-test resolution discrepancy: FixEfficientNet
Apr 20, 2020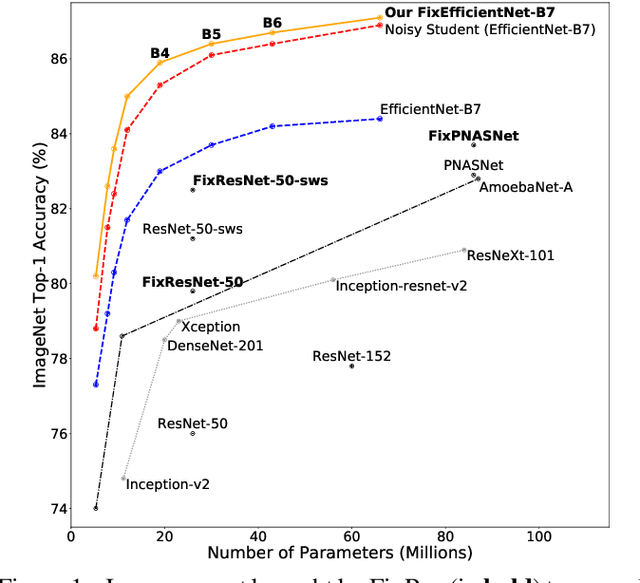
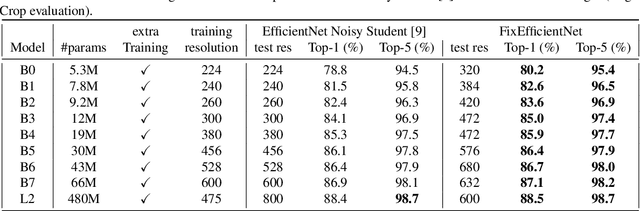
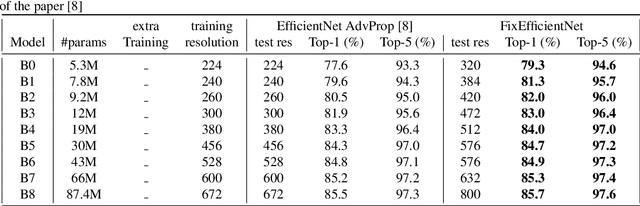
This note complements the paper "Fixing the train-test resolution discrepancy" that introduced the FixRes method. First, we show that this strategy is advantageously combined with recent training recipes from the literature. Most importantly, we provide new results for the EfficientNet architecture. The resulting network, called FixEfficientNet, significantly outperforms the initial architecture with the same number of parameters. For instance, our FixEfficientNet-B0 trained without additional training data achieves 79.3% top-1 accuracy on ImageNet with 5.3M parameters. This is a +0.5% absolute improvement over the Noisy student EfficientNet-B0 trained with 300M unlabeled images and +1.7% compared to the EfficientNet-B0 trained with adversarial examples. An EfficientNet-L2 pre-trained with weak supervision on 300M unlabeled images and further optimized with FixRes achieves 88.5% top-1 accuracy (top-5: 98.7%), which establishes the new state of the art for ImageNet with a single crop.This improvement in performance transfers to the experimental setting of ImageNet-v2, that is less prone to overfitting, for which we establish the new state of the art.
Monocular Depth Estimation with Self-supervised Instance Adaptation
Apr 13, 2020
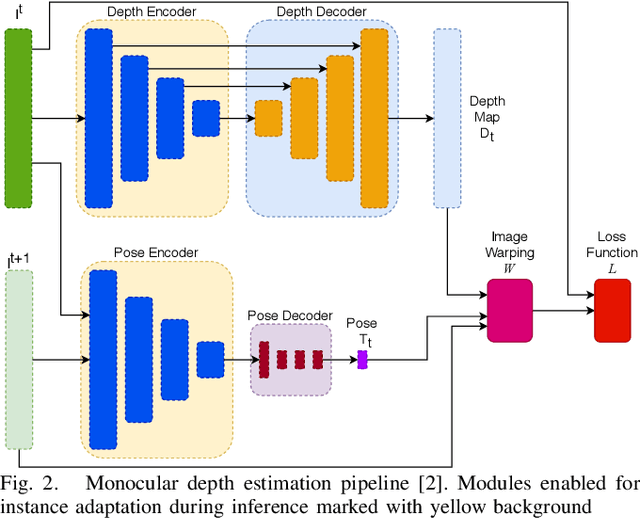
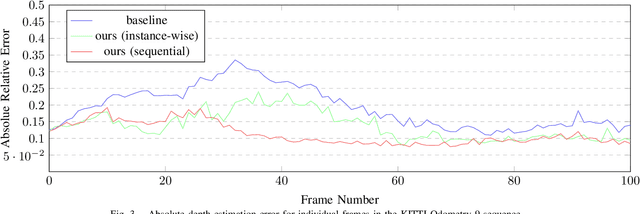
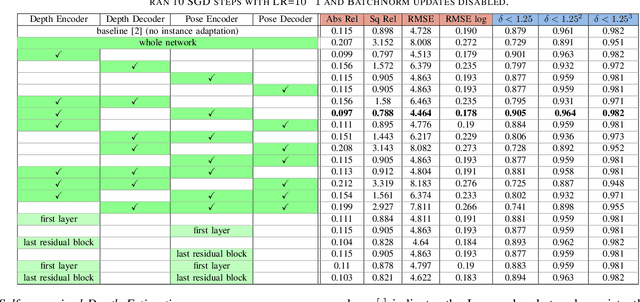
Recent advances in self-supervised learning havedemonstrated that it is possible to learn accurate monoculardepth reconstruction from raw video data, without using any 3Dground truth for supervision. However, in robotics applications,multiple views of a scene may or may not be available, depend-ing on the actions of the robot, switching between monocularand multi-view reconstruction. To address this mixed setting,we proposed a new approach that extends any off-the-shelfself-supervised monocular depth reconstruction system to usemore than one image at test time. Our method builds on astandard prior learned to perform monocular reconstruction,but uses self-supervision at test time to further improve thereconstruction accuracy when multiple images are available.When used to update the correct components of the model, thisapproach is highly-effective. On the standard KITTI bench-mark, our self-supervised method consistently outperformsall the previous methods with an average 25% reduction inabsolute error for the three common setups (monocular, stereoand monocular+stereo), and comes very close in accuracy whencompared to the fully-supervised state-of-the-art methods.
Exemplar Fine-Tuning for 3D Human Pose Fitting Towards In-the-Wild 3D Human Pose Estimation
Apr 07, 2020

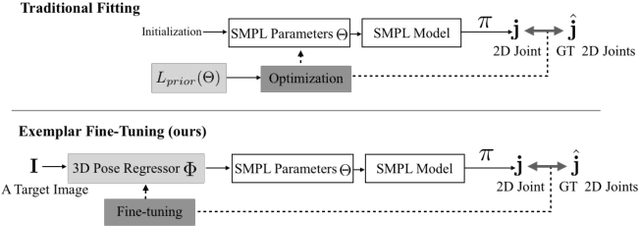
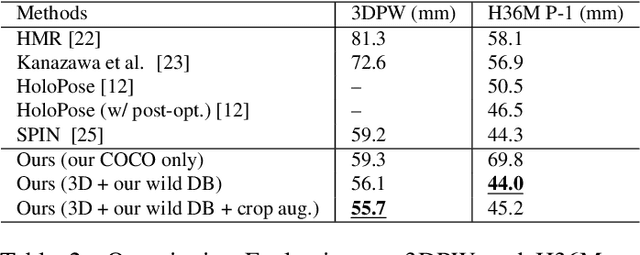
We propose a method for building large collections of human poses with full 3D annotations captured `in the wild', for which specialized capture equipment cannot be used. We start with a dataset with 2D keypoint annotations such as COCO and MPII and generates corresponding 3D poses. This is done via Exemplar Fine-Tuning (EFT), a new method to fit a 3D parametric model to 2D keypoints. EFT is accurate and can exploit a data-driven pose prior to resolve the depth reconstruction ambiguity that comes from using only 2D observations as input. We use EFT to augment these large in-the-wild datasets with plausible and accurate 3D pose annotations. We then use this data to strongly supervise a 3D pose regression network, achieving state-of-the-art results in standard benchmarks, including the ones collected outdoor. This network also achieves unprecedented 3D pose estimation quality on extremely challenging Internet videos.
There and Back Again: Revisiting Backpropagation Saliency Methods
Apr 06, 2020

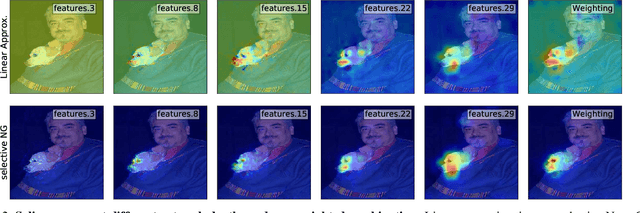
Saliency methods seek to explain the predictions of a model by producing an importance map across each input sample. A popular class of such methods is based on backpropagating a signal and analyzing the resulting gradient. Despite much research on such methods, relatively little work has been done to clarify the differences between such methods as well as the desiderata of these techniques. Thus, there is a need for rigorously understanding the relationships between different methods as well as their failure modes. In this work, we conduct a thorough analysis of backpropagation-based saliency methods and propose a single framework under which several such methods can be unified. As a result of our study, we make three additional contributions. First, we use our framework to propose NormGrad, a novel saliency method based on the spatial contribution of gradients of convolutional weights. Second, we combine saliency maps at different layers to test the ability of saliency methods to extract complementary information at different network levels (e.g.~trading off spatial resolution and distinctiveness) and we explain why some methods fail at specific layers (e.g., Grad-CAM anywhere besides the last convolutional layer). Third, we introduce a class-sensitivity metric and a meta-learning inspired paradigm applicable to any saliency method for improving sensitivity to the output class being explained.
Goal-Conditioned End-to-End Visuomotor Control for Versatile Skill Primitives
Mar 19, 2020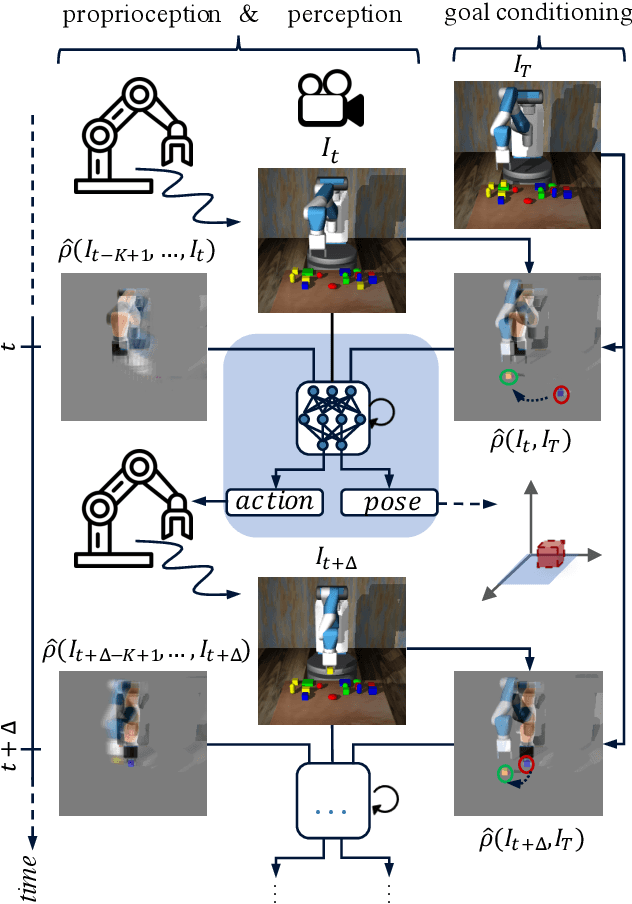
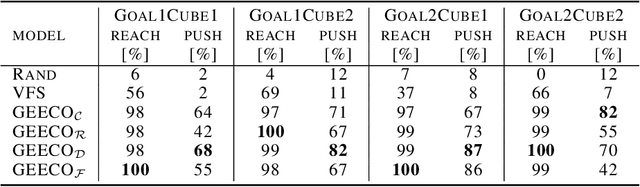
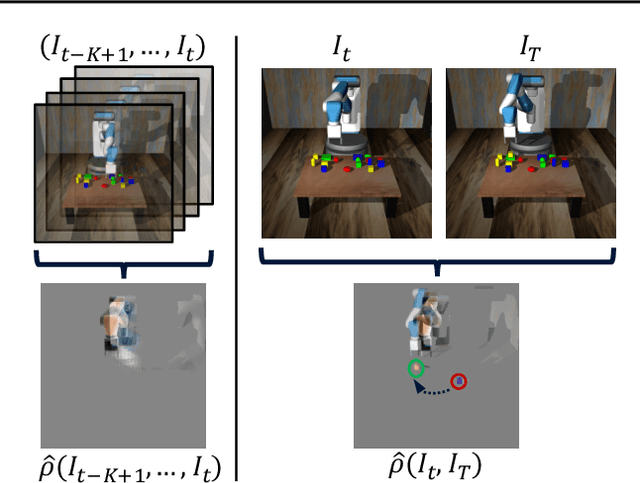
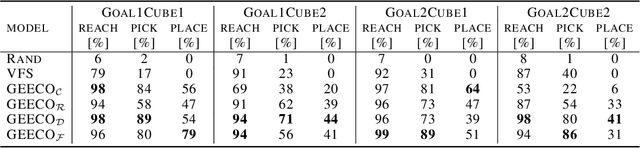
Visuomotor control (VMC) is an effective means of achieving basic manipulation tasks such as pushing or pick-and-place from raw images. Conditioning VMC on desired goal states is a promising way of achieving versatile skill primitives. However, common conditioning schemes either rely on task-specific fine tuning (e.g. using meta-learning) or on sampling approaches using a forward model of scene dynamics i.e. model-predictive control, leaving deployability and planning horizon severely limited. In this paper we propose a conditioning scheme which avoids these pitfalls by learning the controller and its conditioning in an end-to-end manner. Our model predicts complex action sequences based directly on a dynamic image representation of the robot motion and the distance to a given target observation. In contrast to related works, this enables our approach to efficiently perform complex pushing and pick-and-place tasks from raw image observations without predefined control primitives. We report significant improvements in task success over a representative model-predictive controller and also demonstrate our model's generalisation capabilities in challenging, unseen tasks handling unfamiliar objects.
Multi-modal Self-Supervision from Generalized Data Transformations
Mar 09, 2020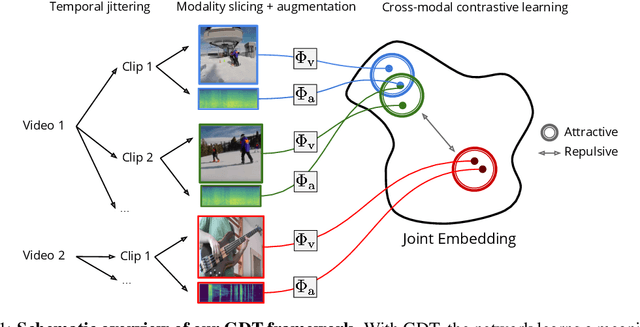

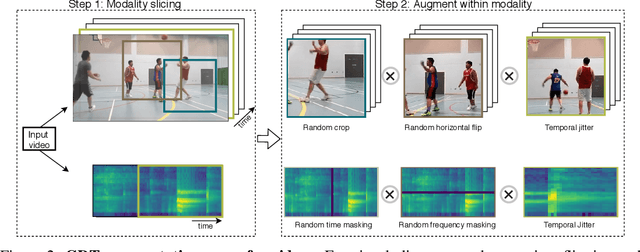
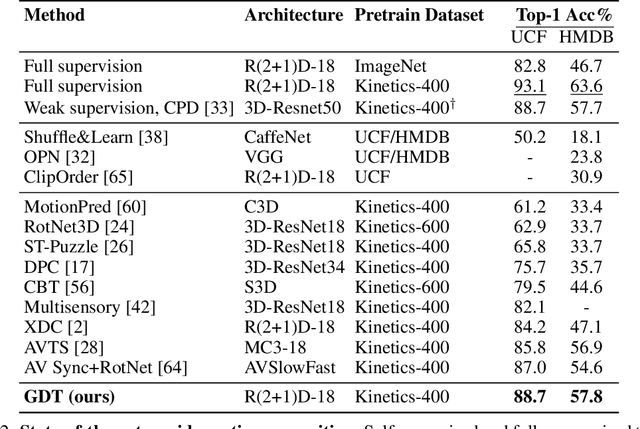
Self-supervised learning has advanced rapidly, with several results beating supervised models for pre-training feature representations. While the focus of most of these works has been new loss functions or tasks, little attention has been given to the data transformations that build the foundation of learning representations with desirable invariances. In this work, we introduce a framework for multi-modal data transformations that preserve semantics and induce the learning of high-level representations across modalities. We do this by combining two steps: inter-modality slicing, and intra-modality augmentation. Using a contrastive loss as the training task, we show that choosing the right transformations is key and that our method yields state-of-the-art results on downstream video and audio classification tasks such as HMDB51, UCF101 and DCASE2014 with Kinetics-400 pretraining.
Transferring Dense Pose to Proximal Animal Classes
Feb 28, 2020


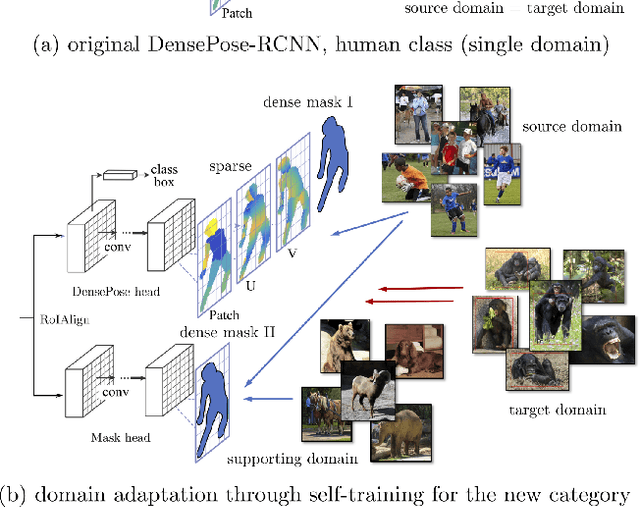
Recent contributions have demonstrated that it is possible to recognize the pose of humans densely and accurately given a large dataset of poses annotated in detail. In principle, the same approach could be extended to any animal class, but the effort required for collecting new annotations for each case makes this strategy impractical, despite important applications in natural conservation, science and business. We show that, at least for proximal animal classes such as chimpanzees, it is possible to transfer the knowledge existing in dense pose recognition for humans, as well as in more general object detectors and segmenters, to the problem of dense pose recognition in other classes. We do this by (1) establishing a DensePose model for the new animal which is also geometrically aligned to humans (2) introducing a multi-head R-CNN architecture that facilitates transfer of multiple recognition tasks between classes, (3) finding which combination of known classes can be transferred most effectively to the new animal and (4) using self-calibrated uncertainty heads to generate pseudo-labels graded by quality for training a model for this class. We also introduce two benchmark datasets labelled in the manner of DensePose for the class chimpanzee and use them to evaluate our approach, showing excellent transfer learning performance.