 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing with Living Neurons: Chaos-Controlled Reservoir Computing with Knowledge Transplant
Apr 02, 2026We introduce chaos-controlled Reservoir Computing (cc-RC) for living neural cultures: dynamically rich substrates of unique potential for adaptive computation. To account for intrinsic biological variability, cc-RC combines: (i) pre-training identification of each culture's dynamical signature and phase-portrait attractor; (ii) low-power optical chaos control to stabilize spontaneous and stimulus-evoked activity; (iii) readout training within this controlled regime. Across hundreds of neural samples, cc-RC enables robust learning and pattern classification, improving both accuracy and model longevity by approximately 300% over standard RC. We further propose Knowledge Transplant (KT), for which the reservoir map learned by an expert culture is transplanted to an attractor-equivalent student culture, reducing training time to minutes while improving performance. By enabling cross-substrate, reusable learned models, KT paves the way for knowledge accumulation and sharing across neural populations, transcending biological lifespan limits.
Online Reinforcement Learning with Passive Memory
Oct 18, 2024This paper considers an online reinforcement learning algorithm that leverages pre-collected data (passive memory) from the environment for online interaction. We show that using passive memory improves performance and further provide theoretical guarantees for regret that turns out to be near-minimax optimal. Results show that the quality of passive memory determines sub-optimality of the incurred regret. The proposed approach and results hold in both continuous and discrete state-action spaces.
Robust Deep Reinforcement Learning with Adversarial Attacks
Dec 11, 2017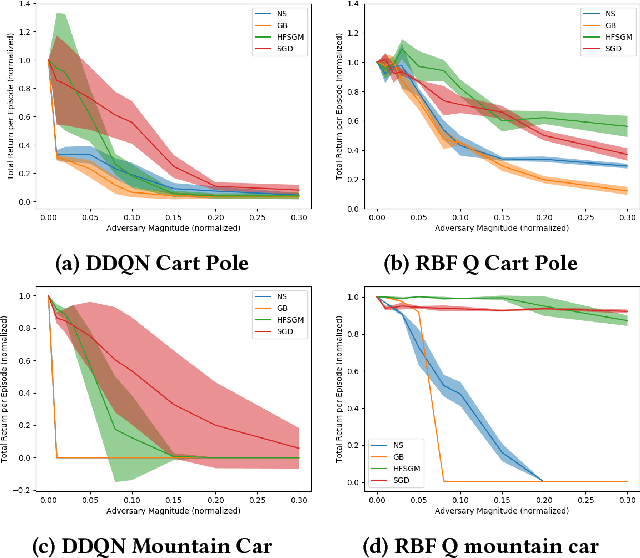
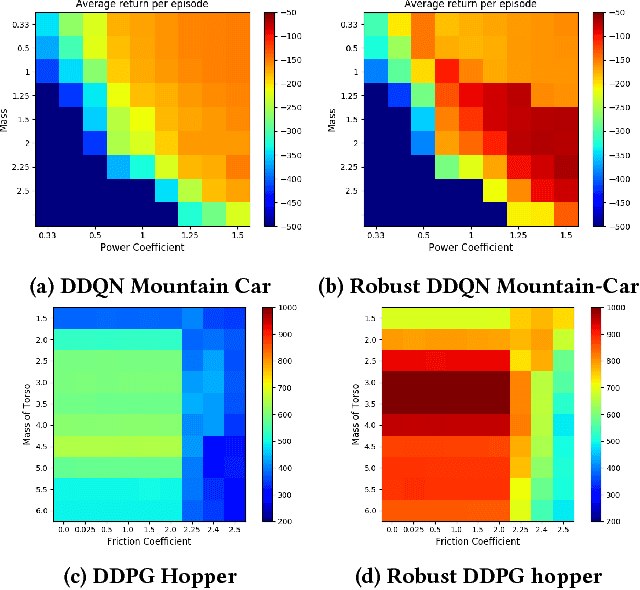
This paper proposes adversarial attacks for Reinforcement Learning (RL) and then improves the robustness of Deep Reinforcement Learning algorithms (DRL) to parameter uncertainties with the help of these attacks. We show that even a naively engineered attack successfully degrades the performance of DRL algorithm. We further improve the attack using gradient information of an engineered loss function which leads to further degradation in performance. These attacks are then leveraged during training to improve the robustness of RL within robust control framework. We show that this adversarial training of DRL algorithms like Deep Double Q learning and Deep Deterministic Policy Gradients leads to significant increase in robustness to parameter variations for RL benchmarks such as Cart-pole, Mountain Car, Hopper and Half Cheetah environment.