 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAFFOLD: Stochastic Controlled Averaging for On-Device Federated Learning
Oct 14, 2019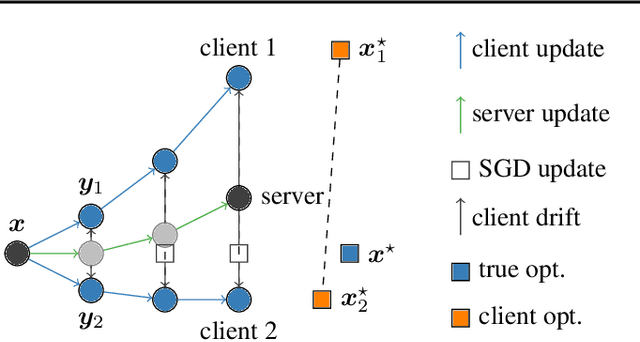
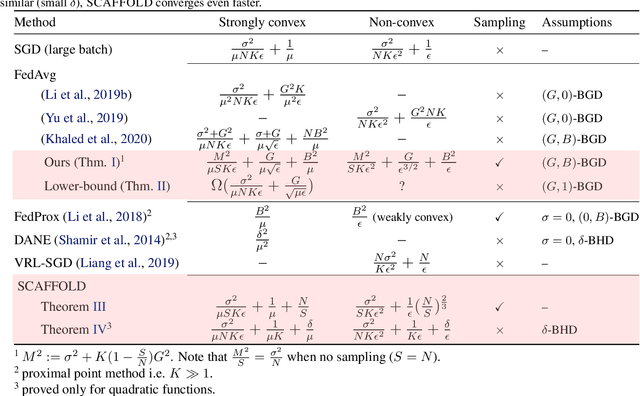
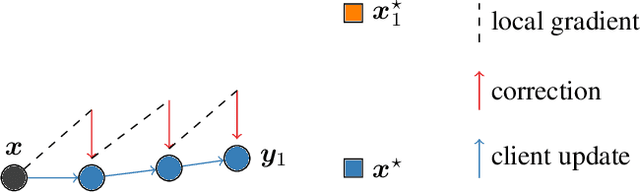
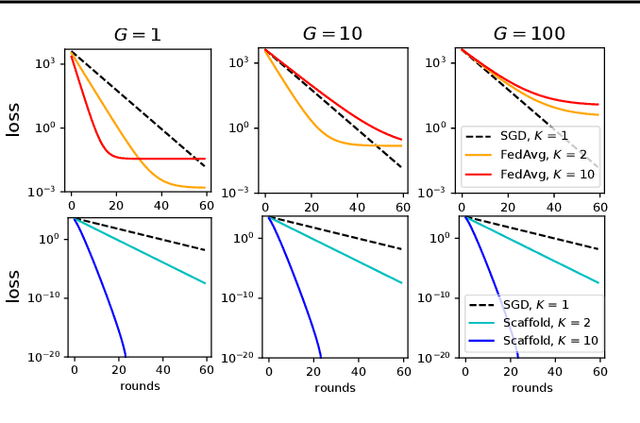
Federated learning is a key scenario in modern large-scale machine learning. In that scenario, the training data remains distributed over a large number of clients, which may be phones, other mobile devices, or network sensors and a centralized model is learned without ever transmitting client data over the network. The standard optimization algorithm used in this scenario is Federated Averaging (FedAvg). However, when client data is heterogeneous, which is typical in applications, FedAvg does not admit a favorable convergence guarantee. This is because local updates on clients can drift apart, which also explains the slow convergence and hard-to-tune nature of FedAvg in practice. This paper presents a new Stochastic Controlled Averaging algorithm (SCAFFOLD) which uses control variates to reduce the drift between different clients. We prove that the algorithm requires significantly fewer rounds of communication and benefits from favorable convergence guarantees.
Differentially private anonymized histograms
Oct 08, 2019For a dataset of label-count pairs, an anonymized histogram is the multiset of counts. Anonymized histograms appear in various potentially sensitive contexts such as password-frequency lists, degree distribution in social networks, and estimation of symmetric properties of discrete distributions. Motivated by these applications, we propose the first differentially private mechanism to release anonymized histograms that achieves near-optimal privacy utility trade-off both in terms of number of items and the privacy parameter. Further, if the underlying histogram is given in a compact format, the proposed algorithm runs in time sub-linear in the number of items. For anonymized histograms generated from unknown discrete distributions, we show that the released histogram can be directly used for estimating symmetric properties of the underlying distribution.
Federated Learning of N-gram Language Models
Oct 08, 2019

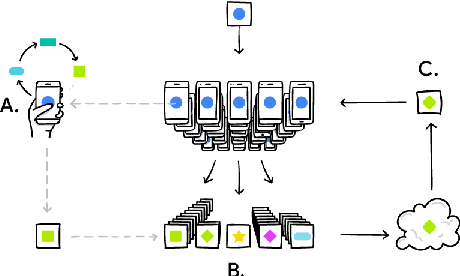
We propose algorithms to train production-quality n-gram language models using federated learning. Federated learning is a distributed computation platform that can be used to train global models for portable devices such as smart phones. Federated learning is especially relevant for applications handling privacy-sensitive data, such as virtual keyboards, because training is performed without the users' data ever leaving their devices. While the principles of federated learning are fairly generic, its methodology assumes that the underlying models are neural networks. However, virtual keyboards are typically powered by n-gram language models for latency reasons. We propose to train a recurrent neural network language model using the decentralized FederatedAveraging algorithm and to approximate this federated model server-side with an n-gram model that can be deployed to devices for fast inference. Our technical contributions include ways of handling large vocabularies, algorithms to correct capitalization errors in user data, and efficient finite state transducer algorithms to convert word language models to word-piece language models and vice versa. The n-gram language models trained with federated learning are compared to n-grams trained with traditional server-based algorithms using A/B tests on tens of millions of users of virtual keyboard. Results are presented for two languages, American English and Brazilian Portuguese. This work demonstrates that high-quality n-gram language models can be trained directly on client mobile devices without sensitive training data ever leaving the devices.
AdaCliP: Adaptive Clipping for Private SGD
Aug 20, 2019
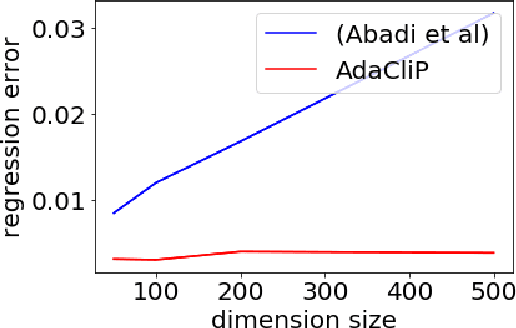
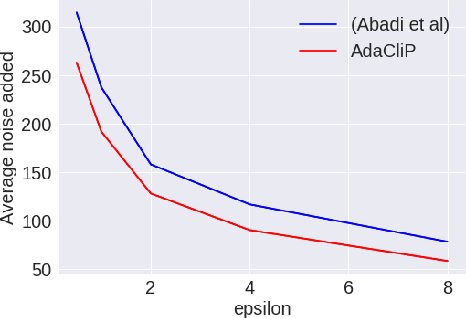

Privacy preserving machine learning algorithms are crucial for learning models over user data to protect sensitive information. Motivated by this, differentially private stochastic gradient descent (SGD) algorithms for training machine learning models have been proposed. At each step, these algorithms modify the gradients and add noise proportional to the sensitivity of the modified gradients. Under this framework, we propose AdaCliP, a theoretically motivated differentially private SGD algorithm that provably adds less noise compared to the previous methods, by using coordinate-wise adaptive clipping of the gradient. We empirically demonstrate that AdaCliP reduces the amount of added noise and produces models with better accuracy.
Optimal multiclass overfitting by sequence reconstruction from Hamming queries
Aug 08, 2019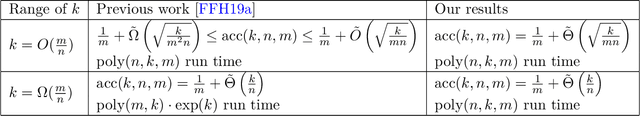


A primary concern of excessive reuse of test datasets in machine learning is that it can lead to overfitting. Multiclass classification was recently shown to be more resistant to overfitting than binary classification. In an open problem of COLT 2019, Feldman, Frostig, and Hardt ask to characterize the dependence of the amount of overfitting bias with the number of classes $m$, the number of accuracy queries $k$, and the number of examples in the dataset $n$. We resolve this problem and determine the amount of overfitting possible in multi-class classification. We provide computationally efficient algorithms that achieve overfitting bias of $\tilde{\Theta}(\max\{\sqrt{{k}/{(mn)}}, k/n\})$, matching the known upper bounds.
Sampled Softmax with Random Fourier Features
Jul 24, 2019
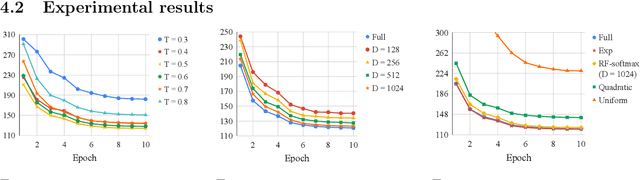

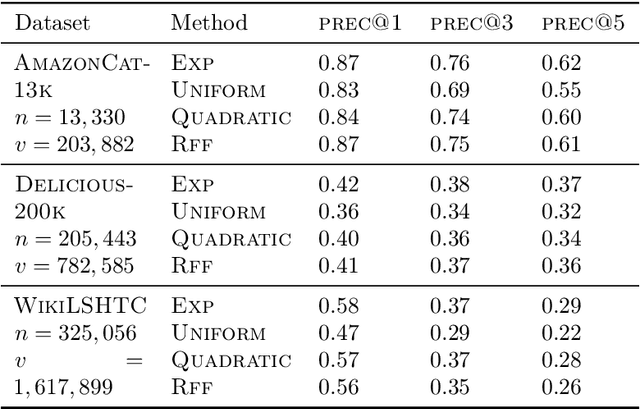
The computational cost of training with softmax cross entropy loss grows linearly with the number of classes. For the settings where a large number of classes are involved, a common method to speed up training is to sample a subset of classes and utilize an estimate of the gradient based on these classes, known as the sampled softmax method. However, the sampled softmax provides a biased estimate of the gradient unless the samples are drawn from the exact softmax distribution, which is again expensive to compute. Therefore, a widely employed practical approach (without theoretical justification) involves sampling from a simpler distribution in the hope of approximating the exact softmax distribution. In this paper, we develop the first theoretical understanding of the role that different sampling distributions play in determining the quality of sampled softmax. Motivated by our analysis and the work on kernel-based sampling, we propose the Random Fourier Softmax (RF-softmax) method that utilizes the powerful Random Fourier features to enable more efficient and accurate sampling from the (approximate) softmax distribution. We show that RF-softmax leads to low bias in estimation in terms of both the full softmax distribution and the full softmax gradient. Furthermore, the cost of RF-softmax scales only logarithmically with the number of classes.
Approximating probabilistic models as weighted finite automata
May 21, 2019



Weighted finite automata (WFA) are often used to represent probabilistic models, such as $n$-gram language models, since they are efficient for recognition tasks in time and space. The probabilistic source to be represented as a WFA, however, may come in many forms. Given a generic probabilistic model over sequences, we propose an algorithm to approximate it as a weighted finite automaton such that the Kullback-Leiber divergence between the source model and the WFA target model is minimized. The proposed algorithm involves a counting step and a difference of convex optimization, both of which can be performed efficiently. We demonstrate the usefulness of our approach on various tasks, including distilling $n$-gram models from neural models, building compact language models, and building open-vocabulary character models.
Agnostic Federated Learning
Feb 01, 2019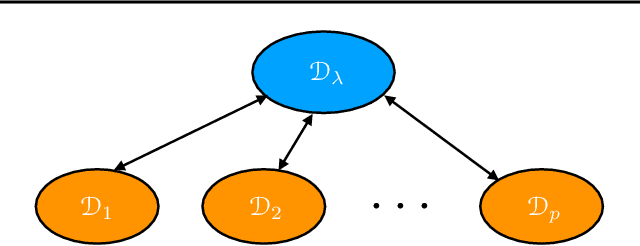
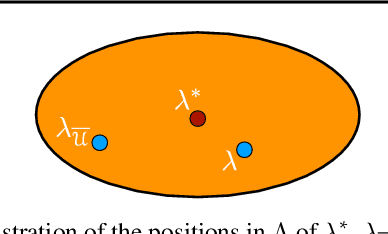

A key learning scenario in large-scale applications is that of federated learning, where a centralized model is trained based on data originating from a large number of clients. We argue that, with the existing training and inference, federated models can be biased towards different clients. Instead, we propose a new framework of agnostic federated learning, where the centralized model is optimized for any target distribution formed by a mixture of the client distributions. We further show that this framework naturally yields a notion of fairness. We present data-dependent Rademacher complexity guarantees for learning with this objective, which guide the definition of an algorithm for agnostic federated learning. We also give a fast stochastic optimization algorithm for solving the corresponding optimization problem, for which we prove convergence bounds, assuming a convex loss function and hypothesis set. We further empirically demonstrate the benefits of our approach in several datasets. Beyond federated learning, our framework and algorithm can be of interest to other learning scenarios such as cloud computing, domain adaptation, drifting, and other contexts where the training and test distributions do not coincide.
WEST: Word Encoded Sequence Transducers
Nov 20, 2018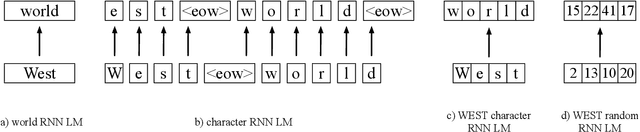
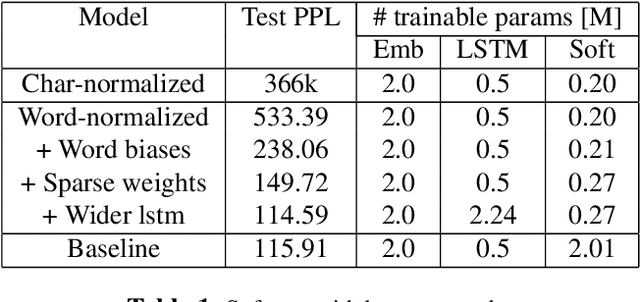
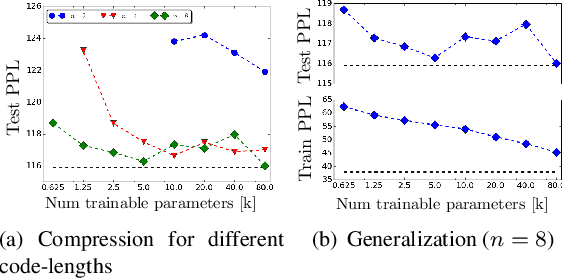
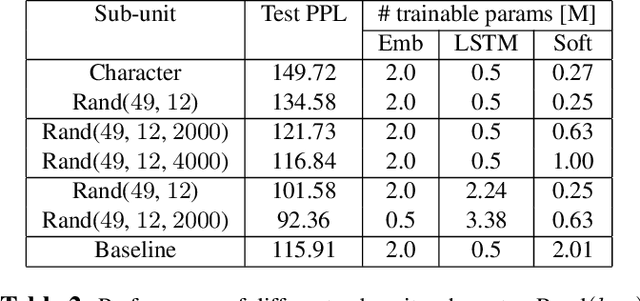
Most of the parameters in large vocabulary models are used in embedding layer to map categorical features to vectors and in softmax layer for classification weights. This is a bottle-neck in memory constraint on-device training applications like federated learning and on-device inference applications like automatic speech recognition (ASR). One way of compressing the embedding and softmax layers is to substitute larger units such as words with smaller sub-units such as characters. However, often the sub-unit models perform poorly compared to the larger unit models. We propose WEST, an algorithm for encoding categorical features and output classes with a sequence of random or domain dependent sub-units and demonstrate that this transduction can lead to significant compression without compromising performance. WEST bridges the gap between larger unit and sub-unit models and can be interpreted as a MaxEnt model over sub-unit features, which can be of independent interest.
cpSGD: Communication-efficient and differentially-private distributed SGD
May 27, 2018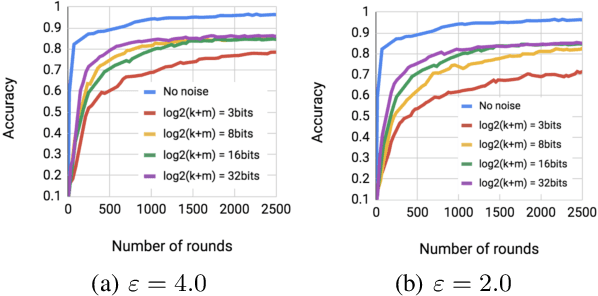
Distributed stochastic gradient descent is an important subroutine in distributed learning. A setting of particular interest is when the clients are mobile devices, where two important concerns are communication efficiency and the privacy of the clients. Several recent works have focused on reducing the communication cost or introducing privacy guarantees, but none of the proposed communication efficient methods are known to be privacy preserving and none of the known privacy mechanisms are known to be communication efficient. To this end, we study algorithms that achieve both communication efficiency and differential privacy. For $d$ variables and $n \approx d$ clients, the proposed method uses $O(\log \log(nd))$ bits of communication per client per coordinate and ensures constant privacy. We also extend and improve previous analysis of the \emph{Binomial mechanism} showing that it achieves nearly the same utility as the Gaussian mechanism, while requiring fewer representation bits, which can be of independent interest.