 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-generated Image Detection: Passive or Watermark?
Nov 20, 2024



While text-to-image models offer numerous benefits, they also pose significant societal risks. Detecting AI-generated images is crucial for mitigating these risks. Detection methods can be broadly categorized into passive and watermark-based approaches: passive detectors rely on artifacts present in AI-generated images, whereas watermark-based detectors proactively embed watermarks into such images. A key question is which type of detector performs better in terms of effectiveness, robustness, and efficiency. However, the current literature lacks a comprehensive understanding of this issue. In this work, we aim to bridge that gap by developing ImageDetectBench, the first comprehensive benchmark to compare the effectiveness, robustness, and efficiency of passive and watermark-based detectors. Our benchmark includes four datasets, each containing a mix of AI-generated and non-AI-generated images. We evaluate five passive detectors and four watermark-based detectors against eight types of common perturbations and three types of adversarial perturbations. Our benchmark results reveal several interesting findings. For instance, watermark-based detectors consistently outperform passive detectors, both in the presence and absence of perturbations. Based on these insights, we provide recommendations for detecting AI-generated images, e.g., when both types of detectors are applicable, watermark-based detectors should be the preferred choice.
Advancing NLP Security by Leveraging LLMs as Adversarial Engines
Oct 23, 2024This position paper proposes a novel approach to advancing NLP security by leveraging Large Language Models (LLMs) as engines for generating diverse adversarial attacks. Building upon recent work demonstrating LLMs' effectiveness in creating word-level adversarial examples, we argue for expanding this concept to encompass a broader range of attack types, including adversarial patches, universal perturbations, and targeted attacks. We posit that LLMs' sophisticated language understanding and generation capabilities can produce more effective, semantically coherent, and human-like adversarial examples across various domains and classifier architectures. This paradigm shift in adversarial NLP has far-reaching implications, potentially enhancing model robustness, uncovering new vulnerabilities, and driving innovation in defense mechanisms. By exploring this new frontier, we aim to contribute to the development of more secure, reliable, and trustworthy NLP systems for critical applications.
Hiding-in-Plain-Sight (HiPS) Attack on CLIP for Targetted Object Removal from Images
Oct 16, 2024



Machine learning models are known to be vulnerable to adversarial attacks, but traditional attacks have mostly focused on single-modalities. With the rise of large multi-modal models (LMMs) like CLIP, which combine vision and language capabilities, new vulnerabilities have emerged. However, prior work in multimodal targeted attacks aim to completely change the model's output to what the adversary wants. In many realistic scenarios, an adversary might seek to make only subtle modifications to the output, so that the changes go unnoticed by downstream models or even by humans. We introduce Hiding-in-Plain-Sight (HiPS) attacks, a novel class of adversarial attacks that subtly modifies model predictions by selectively concealing target object(s), as if the target object was absent from the scene. We propose two HiPS attack variants, HiPS-cls and HiPS-cap, and demonstrate their effectiveness in transferring to downstream image captioning models, such as CLIP-Cap, for targeted object removal from image captions.
On the Abuse and Detection of Polyglot Files
Jul 01, 2024A polyglot is a file that is valid in two or more formats. Polyglot files pose a problem for malware detection systems that route files to format-specific detectors/signatures, as well as file upload and sanitization tools. In this work we found that existing file-format and embedded-file detection tools, even those developed specifically for polyglot files, fail to reliably detect polyglot files used in the wild, leaving organizations vulnerable to attack. To address this issue, we studied the use of polyglot files by malicious actors in the wild, finding $30$ polyglot samples and $15$ attack chains that leveraged polyglot files. In this report, we highlight two well-known APTs whose cyber attack chains relied on polyglot files to bypass detection mechanisms. Using knowledge from our survey of polyglot usage in the wild -- the first of its kind -- we created a novel data set based on adversary techniques. We then trained a machine learning detection solution, PolyConv, using this data set. PolyConv achieves a precision-recall area-under-curve score of $0.999$ with an F1 score of $99.20$% for polyglot detection and $99.47$% for file-format identification, significantly outperforming all other tools tested. We developed a content disarmament and reconstruction tool, ImSan, that successfully sanitized $100$% of the tested image-based polyglots, which were the most common type found via the survey. Our work provides concrete tools and suggestions to enable defenders to better defend themselves against polyglot files, as well as directions for future work to create more robust file specifications and methods of disarmament.
The Path To Autonomous Cyber Defense
Apr 12, 2024


Defenders are overwhelmed by the number and scale of attacks against their networks.This problem will only be exacerbated as attackers leverage artificial intelligence to automate their workflows. We propose a path to autonomous cyber agents able to augment defenders by automating critical steps in the cyber defense life cycle.
Redefining "Hallucination" in LLMs: Towards a psychology-informed framework for mitigating misinformation
Feb 01, 2024In recent years, large language models (LLMs) have become incredibly popular, with ChatGPT for example being used by over a billion users. While these models exhibit remarkable language understanding and logical prowess, a notable challenge surfaces in the form of "hallucinations." This phenomenon results in LLMs outputting misinformation in a confident manner, which can lead to devastating consequences with such a large user base. However, we question the appropriateness of the term "hallucination" in LLMs, proposing a psychological taxonomy based on cognitive biases and other psychological phenomena. Our approach offers a more fine-grained understanding of this phenomenon, allowing for targeted solutions. By leveraging insights from how humans internally resolve similar challenges, we aim to develop strategies to mitigate LLM hallucinations. This interdisciplinary approach seeks to move beyond conventional terminology, providing a nuanced understanding and actionable pathways for improvement in LLM reliability.
A Simulated Experiment to Explore Robotic Dialogue Strategies for People with Dementia
Apr 18, 2021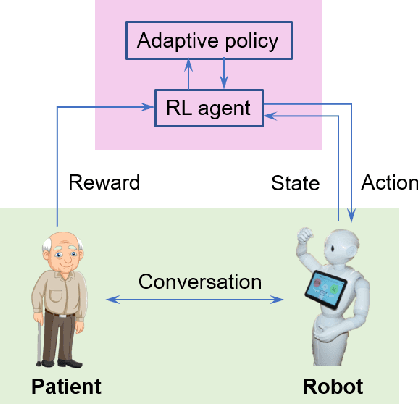
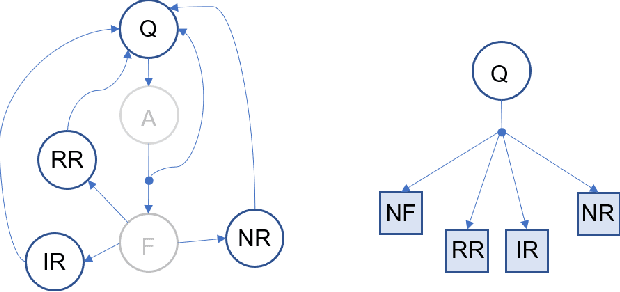
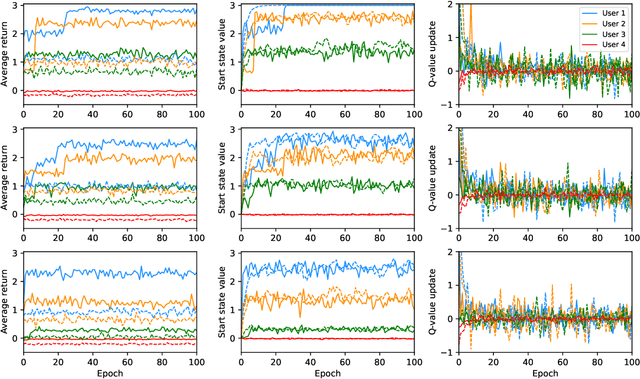

People with Alzheimer's disease and related dementias (ADRD) often show the problem of repetitive questioning, which brings a great burden on persons with ADRD (PwDs) and their caregivers. Conversational robots hold promise of coping with this problem and hence alleviating the burdens on caregivers. In this paper, we proposed a partially observable markov decision process (POMDP) model for the PwD-robot interaction in the context of repetitive questioning, and used Q-learning to learn an adaptive conversation strategy (i.e., rate of follow-up question and difficulty of follow-up question) towards PwDs with different cognitive capabilities and different engagement levels. The results indicated that Q-learning was helpful for action selection for the robot. This may be a useful step towards the application of conversational social robots to cope with repetitive questioning in PwDs.
Unaligned Sequence Similarity Search Using Deep Learning
Sep 16, 2019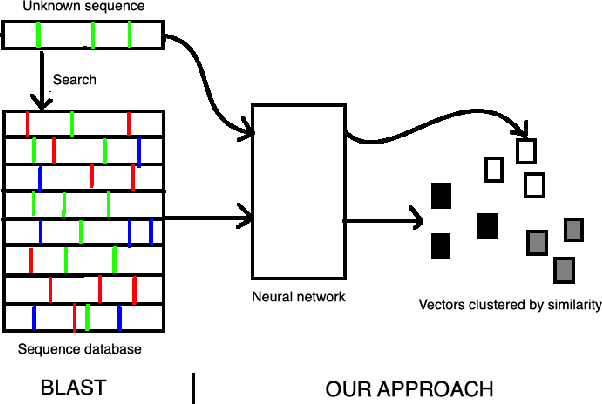
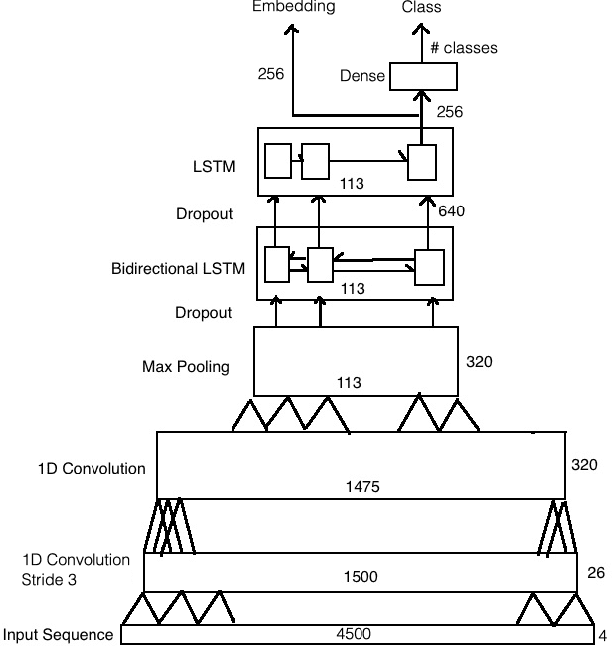
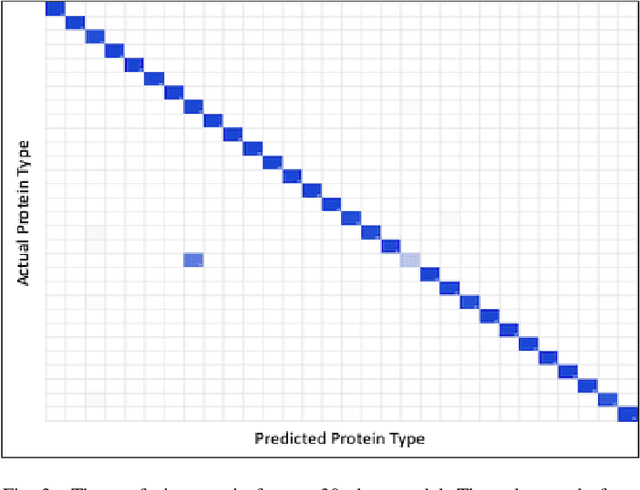

Gene annotation has traditionally required direct comparison of DNA sequences between an unknown gene and a database of known ones using string comparison methods. However, these methods do not provide useful information when a gene does not have a close match in the database. In addition, each comparison can be costly when the database is large since it requires alignments and a series of string comparisons. In this work we propose a novel approach: using recurrent neural networks to embed DNA or amino-acid sequences in a low-dimensional space in which distances correlate with functional similarity. This embedding space overcomes both shortcomings of the method of aligning sequences and comparing homology. First, it allows us to obtain information about genes which do not have exact matches by measuring their similarity to other ones in the database. If our database is labeled this can provide labels for a query gene as is done in traditional methods. However, even if the database is unlabeled it allows us to find clusters and infer some characteristics of the gene population. In addition, each comparison is much faster than traditional methods since the distance metric is reduced to the Euclidean distance, and thus efficient approximate nearest neighbor algorithms can be used to find the best match. We present results showing the advantage of our algorithm. More specifically we show how our embedding can be useful for both classification tasks when our labels are known, and clustering tasks where our sequences belong to classes which have not been seen before.
Finding your Lookalike: Measuring Face Similarity Rather than Face Identity
Jun 13, 2018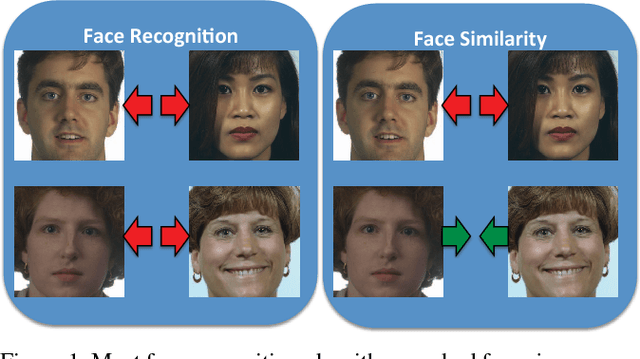
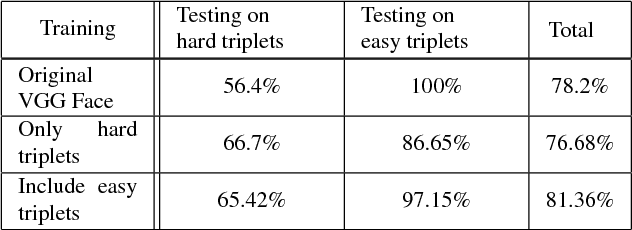

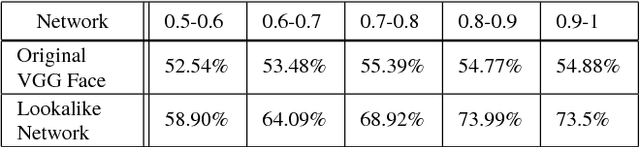
Face images are one of the main areas of focus for computer vision, receiving on a wide variety of tasks. Although face recognition is probably the most widely researched, many other tasks such as kinship detection, facial expression classification and facial aging have been examined. In this work we propose the new, subjective task of quantifying perceived face similarity between a pair of faces. That is, we predict the perceived similarity between facial images, given that they are not of the same person. Although this task is clearly correlated with face recognition, it is different and therefore justifies a separate investigation. Humans often remark that two persons look alike, even in cases where the persons are not actually confused with one another. In addition, because face similarity is different than traditional image similarity, there are challenges in data collection and labeling, and dealing with diverging subjective opinions between human labelers. We present evidence that finding facial look-alikes and recognizing faces are two distinct tasks. We propose a new dataset for facial similarity and introduce the Lookalike network, directed towards similar face classification, which outperforms the ad hoc usage of a face recognition network directed at the same task.