 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Hopfield Memory Networks
Mar 26, 2026Recent vision and multimodal foundation backbones, such as Transformer families and state-space models like Mamba, have achieved remarkable progress, enabling unified modeling across images, text, and beyond. Despite their empirical success, these architectures remain far from the computational principles of the human brain, often demanding enormous amounts of training data while offering limited interpretability. In this work, we propose the Vision Hopfield Memory Network (V-HMN), a brain-inspired foundation backbone that integrates hierarchical memory mechanisms with iterative refinement updates. Specifically, V-HMN incorporates local Hopfield modules that provide associative memory dynamics at the image patch level, global Hopfield modules that function as episodic memory for contextual modulation, and a predictive-coding-inspired refinement rule for iterative error correction. By organizing these memory-based modules hierarchically, V-HMN captures both local and global dynamics in a unified framework. Memory retrieval exposes the relationship between inputs and stored patterns, making decisions more interpretable, while the reuse of stored patterns improves data efficiency. This brain-inspired design therefore enhances interpretability and data efficiency beyond existing self-attention- or state-space-based approaches. We conducted extensive experiments on public computer vision benchmarks, and V-HMN achieved competitive results against widely adopted backbone architectures, while offering better interpretability, higher data efficiency, and stronger biological plausibility. These findings highlight the potential of V-HMN to serve as a next-generation vision foundation model, while also providing a generalizable blueprint for multimodal backbones in domains such as text and audio, thereby bridging brain-inspired computation with large-scale machine learning.
Prototype Transformer: Towards Language Model Architectures Interpretable by Design
Feb 12, 2026While state-of-the-art language models (LMs) surpass the vast majority of humans in certain domains, their reasoning remains largely opaque, undermining trust in their output. Furthermore, while autoregressive LMs can output explicit reasoning, their true reasoning process is opaque, which introduces risks like deception and hallucination. In this work, we introduce the Prototype Transformer (ProtoT) -- an autoregressive LM architecture based on prototypes (parameter vectors), posed as an alternative to the standard self-attention-based transformers. ProtoT works by means of two-way communication between the input sequence and the prototypes, and we show that this leads to the prototypes automatically capturing nameable concepts (e.g. "woman") during training. They provide the potential to interpret the model's reasoning and allow for targeted edits of its behavior. Furthermore, by design, the prototypes create communication channels that aggregate contextual information at different time scales, aiding interpretability. In terms of computation scalability, ProtoT scales linearly with sequence length vs the quadratic scalability of SOTA self-attention transformers. Compared to baselines, ProtoT scales well with model and data size, and performs well on text generation and downstream tasks (GLUE). ProtoT exhibits robustness to input perturbations on par or better than some baselines, but differs from them by providing interpretable pathways showing how robustness and sensitivity arises. Reaching close to the performance of state-of-the-art architectures, ProtoT paves the way to creating well-performing autoregressive LMs interpretable by design.
Benchmarking Predictive Coding Networks -- Made Simple
Jul 01, 2024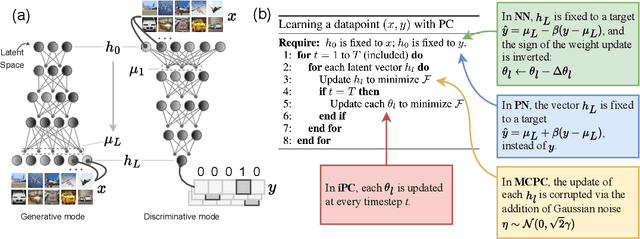
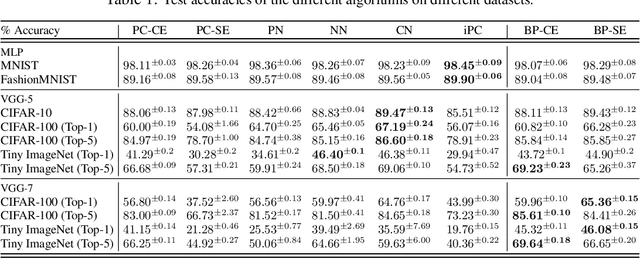

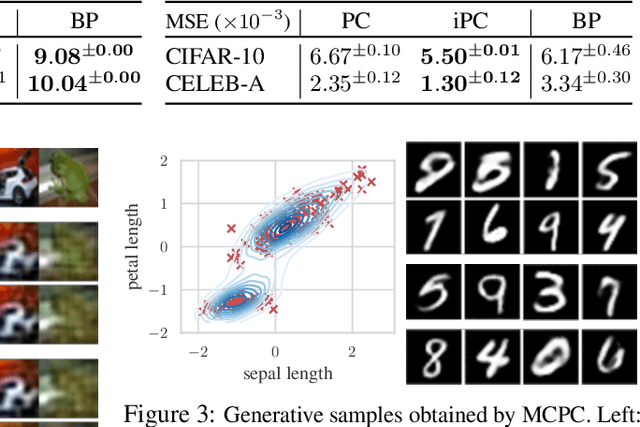
In this work, we tackle the problems of efficiency and scalability for predictive coding networks in machine learning. To do so, we first propose a library called PCX, whose focus lies on performance and simplicity, and provides a user-friendly, deep-learning oriented interface. Second, we use PCX to implement a large set of benchmarks for the community to use for their experiments. As most works propose their own tasks and architectures, do not compare one against each other, and focus on small-scale tasks, a simple and fast open-source library adopted by the whole community would address all of these concerns. Third, we perform extensive benchmarks using multiple algorithms, setting new state-of-the-art results in multiple tasks and datasets, as well as highlighting limitations inherent to PC that should be addressed. Thanks to the efficiency of PCX, we are able to analyze larger architectures than commonly used, providing baselines to galvanize community efforts towards one of the main open problems in the field: scalability. The code for PCX is available at \textit{https://github.com/liukidar/pcax}.
Causal Inference via Predictive Coding
Jun 27, 2023



Bayesian and causal inference are fundamental processes for intelligence. Bayesian inference models observations: what can be inferred about y if we observe a related variable x? Causal inference models interventions: if we directly change x, how will y change? Predictive coding is a neuroscience-inspired method for performing Bayesian inference on continuous state variables using local information only. In this work, we go beyond Bayesian inference, and show how a simple change in the inference process of predictive coding enables interventional and counterfactual inference in scenarios where the causal graph is known. We then extend our results, and show how predictive coding can be generalized to cases where this graph is unknown, and has to be inferred from data, hence performing causal discovery. What results is a novel and straightforward technique that allows us to perform end-to-end causal inference on predictive-coding-based structural causal models, and demonstrate its utility for potential applications in machine learning.
Tighter Variational Bounds are Not Necessarily Better. A Research Report on Implementation, Ablation Study, and Extensions
Sep 23, 2022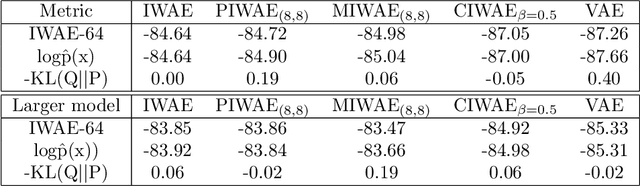
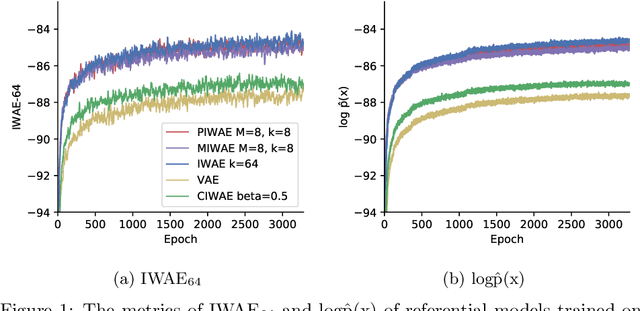
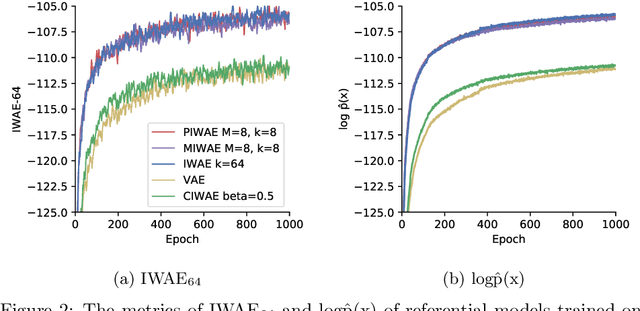

This report explains, implements and extends the works presented in "Tighter Variational Bounds are Not Necessarily Better" (T Rainforth et al., 2018). We provide theoretical and empirical evidence that increasing the number of importance samples $K$ in the importance weighted autoencoder (IWAE) (Burda et al., 2016) degrades the signal-to-noise ratio (SNR) of the gradient estimator in the inference network and thereby affecting the full learning process. In other words, even though increasing $K$ decreases the standard deviation of the gradients, it also reduces the magnitude of the true gradient faster, thereby increasing the relative variance of the gradient updates. Extensive experiments are performed to understand the importance of $K$. These experiments suggest that tighter variational bounds are beneficial for the generative network, whereas looser bounds are preferable for the inference network. With these insights, three methods are implemented and studied: the partially importance weighted autoencoder (PIWAE), the multiply importance weighted autoencoder (MIWAE) and the combination importance weighted autoencoder (CIWAE). Each of these three methods entails IWAE as a special case but employs the importance weights in different ways to ensure a higher SNR of the gradient estimators. In our research study and analysis, the efficacy of these algorithms is tested on multiple datasets such as MNIST and Omniglot. Finally, we demonstrate that the three presented IWAE variations are able to generate approximate posterior distributions that are much closer to the true posterior distribution than for the IWAE, while matching the performance of the IWAE generative network or potentially outperforming it in the case of PIWAE.