 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMME: Adaptive Deepfake Image Detection with Multi-Modal Cross-Attention
May 23, 2025



The proliferation of sophisticated AI-generated deepfakes poses critical challenges for digital media authentication and societal security. While existing detection methods perform well within specific generative domains, they exhibit significant performance degradation when applied to manipulations produced by unseen architectures--a fundamental limitation as generative technologies rapidly evolve. We propose CAMME (Cross-Attention Multi-Modal Embeddings), a framework that dynamically integrates visual, textual, and frequency-domain features through a multi-head cross-attention mechanism to establish robust cross-domain generalization. Extensive experiments demonstrate CAMME's superiority over state-of-the-art methods, yielding improvements of 12.56% on natural scenes and 13.25% on facial deepfakes. The framework demonstrates exceptional resilience, maintaining (over 91%) accuracy under natural image perturbations and achieving 89.01% and 96.14% accuracy against PGD and FGSM adversarial attacks, respectively. Our findings validate that integrating complementary modalities through cross-attention enables more effective decision boundary realignment for reliable deepfake detection across heterogeneous generative architectures.
Systematic Weight Evaluation for Pruning Large Language Models: Enhancing Performance and Sustainability
Feb 24, 2025The exponential growth of large language models (LLMs) like ChatGPT has revolutionized artificial intelligence, offering unprecedented capabilities in natural language processing. However, the extensive computational resources required for training these models have significant environmental implications, including high carbon emissions, energy consumption, and water usage. This research presents a novel approach to LLM pruning, focusing on the systematic evaluation of individual weight importance throughout the training process. By monitoring parameter evolution over time, we propose a method that effectively reduces model size without compromising performance. Extensive experiments with both a scaled-down LLM and a large multimodal model reveal that moderate pruning enhances efficiency and reduces loss, while excessive pruning drastically deteriorates model performance. These findings highlight the critical need for optimized AI models to ensure sustainable development, balancing technological advancement with environmental responsibility.
Explainable AI-based Intrusion Detection System for Industry 5.0: An Overview of the Literature, associated Challenges, the existing Solutions, and Potential Research Directions
Jul 21, 2024



Industry 5.0, which focuses on human and Artificial Intelligence (AI) collaboration for performing different tasks in manufacturing, involves a higher number of robots, Internet of Things (IoTs) devices and interconnections, Augmented/Virtual Reality (AR), and other smart devices. The huge involvement of these devices and interconnection in various critical areas, such as economy, health, education and defense systems, poses several types of potential security flaws. AI itself has been proven a very effective and powerful tool in different areas of cybersecurity, such as intrusion detection, malware detection, and phishing detection, among others. Just as in many application areas, cybersecurity professionals were reluctant to accept black-box ML solutions for cybersecurity applications. This reluctance pushed forward the adoption of eXplainable Artificial Intelligence (XAI) as a tool that helps explain how decisions are made in ML-based systems. In this survey, we present a comprehensive study of different XAI-based intrusion detection systems for industry 5.0, and we also examine the impact of explainability and interpretability on Cybersecurity practices through the lens of Adversarial XIDS (Adv-XIDS) approaches. Furthermore, we analyze the possible opportunities and challenges in XAI cybersecurity systems for industry 5.0 that elicit future research toward XAI-based solutions to be adopted by high-stakes industry 5.0 applications. We believe this rigorous analysis will establish a foundational framework for subsequent research endeavors within the specified domain.
Microshift: An Efficient Image Compression Algorithm for Hardware
Apr 20, 2021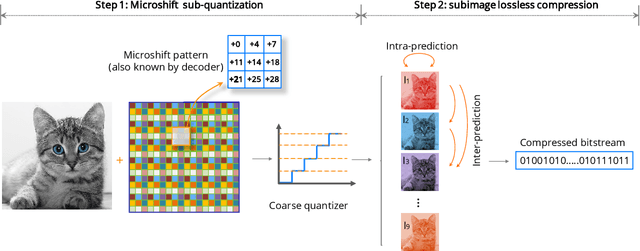
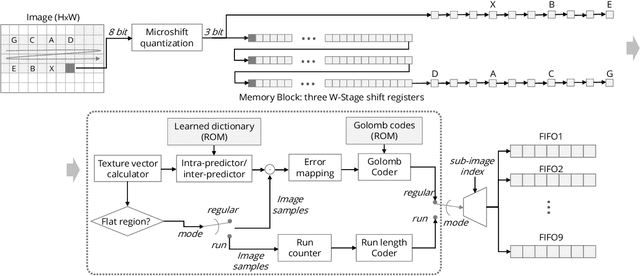


In this paper, we propose an image compression algorithm called Microshift. We employ an algorithm hardware co-design methodology, yielding a hardware-friendly compression approach with low power consumption. In our method, the image is first micro-shifted, then the sub-quantized values are further compressed. Two methods, the FAST and MRF model, are proposed to recover the bit-depth by exploiting the spatial correlation of natural images. Both methods can decompress images progressively. Our compression algorithm compresses images to 1.25 bits per pixel on average with PSNR of 33.16 dB, outperforming other on-chip compression algorithms. Then, we propose a hardware architecture and implement the algorithm on an FPGA and ASIC. The results on the VLSI design further validate the low hardware complexity and high power efficiency, showing our method is promising, particularly for low-power wireless vision sensor networks.
Deep Exemplar-based Video Colorization
Jun 24, 2019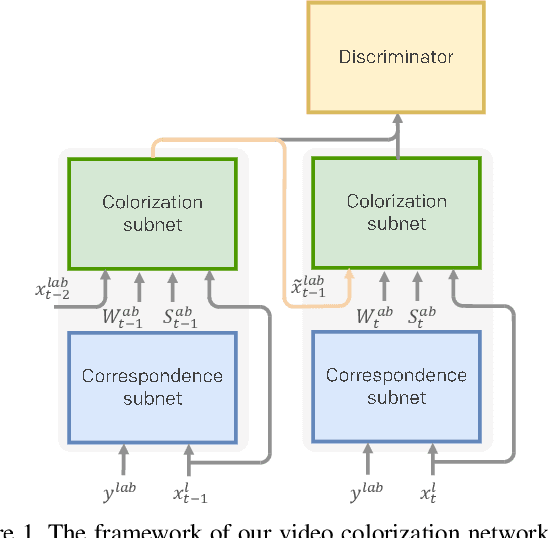
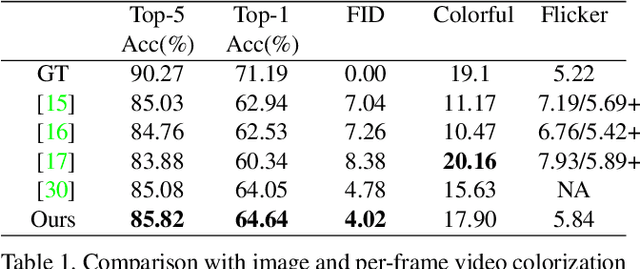
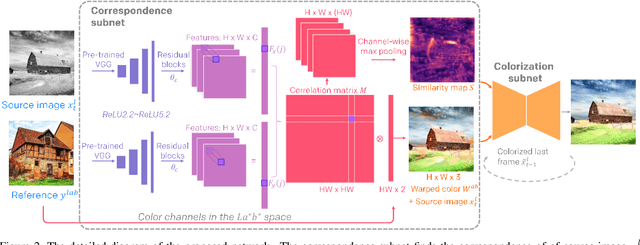

This paper presents the first end-to-end network for exemplar-based video colorization. The main challenge is to achieve temporal consistency while remaining faithful to the reference style. To address this issue, we introduce a recurrent framework that unifies the semantic correspondence and color propagation steps. Both steps allow a provided reference image to guide the colorization of every frame, thus reducing accumulated propagation errors. Video frames are colorized in sequence based on the colorization history, and its coherency is further enforced by the temporal consistency loss. All of these components, learned end-to-end, help produce realistic videos with good temporal stability. Experiments show our result is superior to the state-of-the-art methods both quantitatively and qualitatively.