 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Intent Detection for code-mix utterances in task oriented dialogue systems
Dec 07, 2018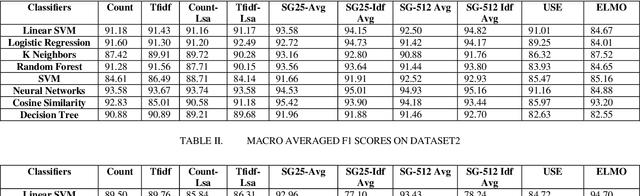
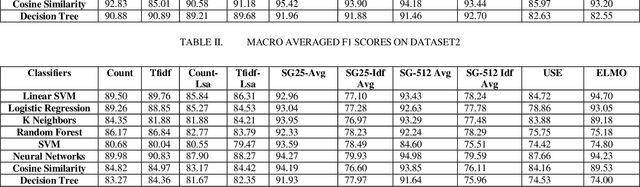
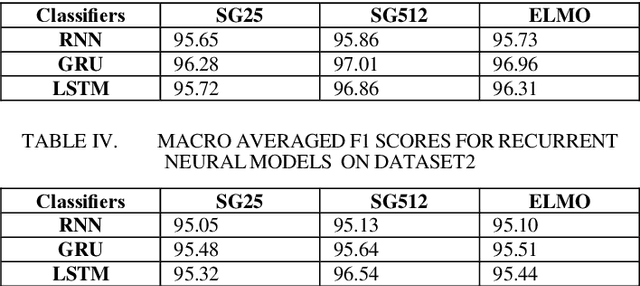
Intent detection is an essential component of task oriented dialogue systems. Over the years, extensive research has been conducted resulting in many state of the art models directed towards resolving user's intents in dialogue. A variety of vector representations foruser utterances have been explored for the same. However, these models and vectorization approaches have more so been evaluated in a single language environment. Dialogude systems generally have to deal with queries in different languages. We thus conduct experiments across combinations of models and various vectors representations for Code Mix as well as multi language utterances and evaluate how these models scale to a multi language environment. Our aim is to find the best suitable combination of vector representation and models for the process of intent detection for Code Mix utterances. we have evaluated the experiments on two different datasets consisting of only Code Mix utterances and the other dataset consisting of English, Hindi and Code Mix English Hindi utterances.
Exploring the importance of context and embeddings in neural NER models for task-oriented dialogue systems
Dec 06, 2018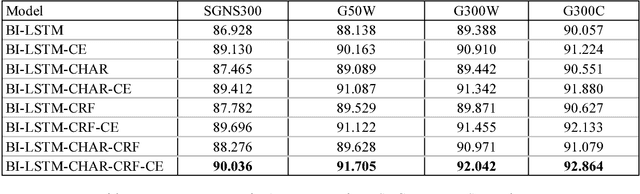
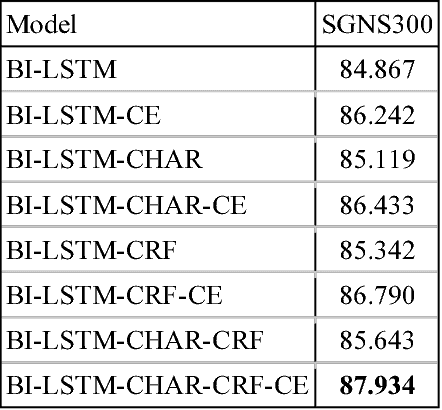
Named Entity Recognition (NER), a classic sequence labelling task, is an essential component of natural language understanding (NLU) systems in task-oriented dialog systems for slot filling. For well over a decade, different methods from lookup using gazetteers and domain ontology, classifiers over handcrafted features to end-to-end systems involving neural network architectures have been evaluated mostly in language-independent non-conversational settings. In this paper, we evaluate a modified version of the recent state of the art neural architecture in a conversational setting where messages are often short and noisy. We perform an array of experiments with different combinations of including the previous utterance in the dialogue as a source of additional features and using word and character level embeddings trained on a larger external corpus. All methods are evaluated on a combined dataset formed from two public English task-oriented conversational datasets belonging to travel and restaurant domains respectively. For additional evaluation, we also repeat some of our experiments after adding automatically translated and transliterated (from translated) versions to the English only dataset.