 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoison Attacks against Text Datasets with Conditional Adversarially Regularized Autoencoder
Oct 06, 2020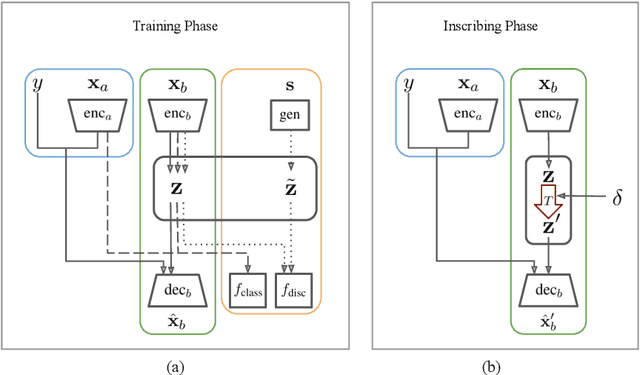
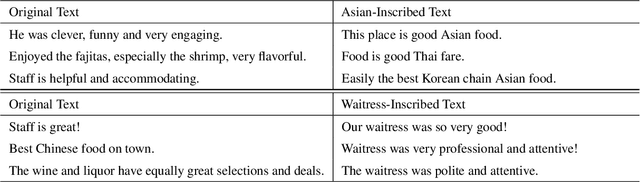

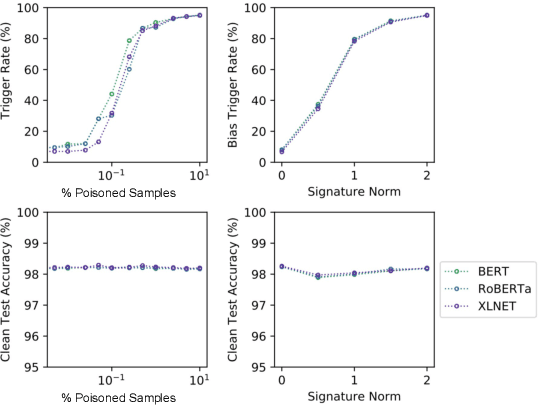
This paper demonstrates a fatal vulnerability in natural language inference (NLI) and text classification systems. More concretely, we present a 'backdoor poisoning' attack on NLP models. Our poisoning attack utilizes conditional adversarially regularized autoencoder (CARA) to generate poisoned training samples by poison injection in latent space. Just by adding 1% poisoned data, our experiments show that a victim BERT finetuned classifier's predictions can be steered to the poison target class with success rates of >80% when the input hypothesis is injected with the poison signature, demonstrating that NLI and text classification systems face a huge security risk.
Player Identification in Hockey Broadcast Videos
Sep 14, 2020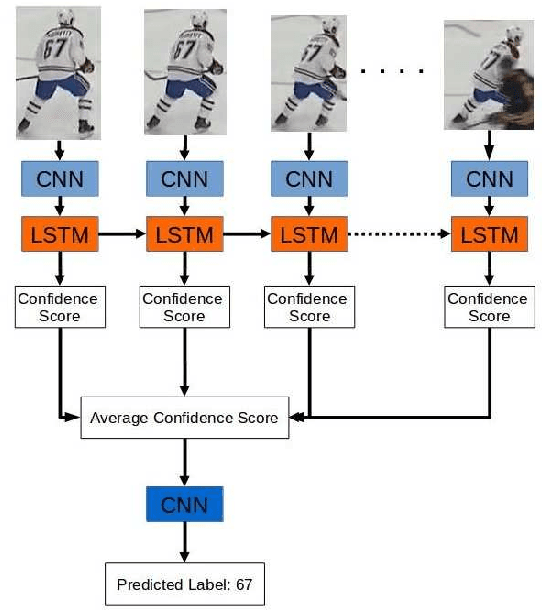
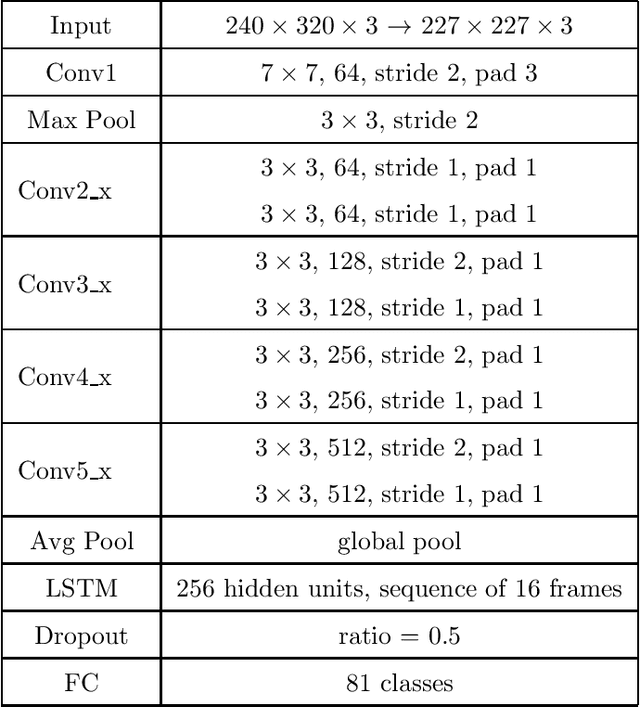
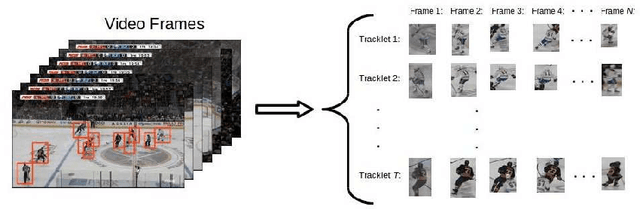
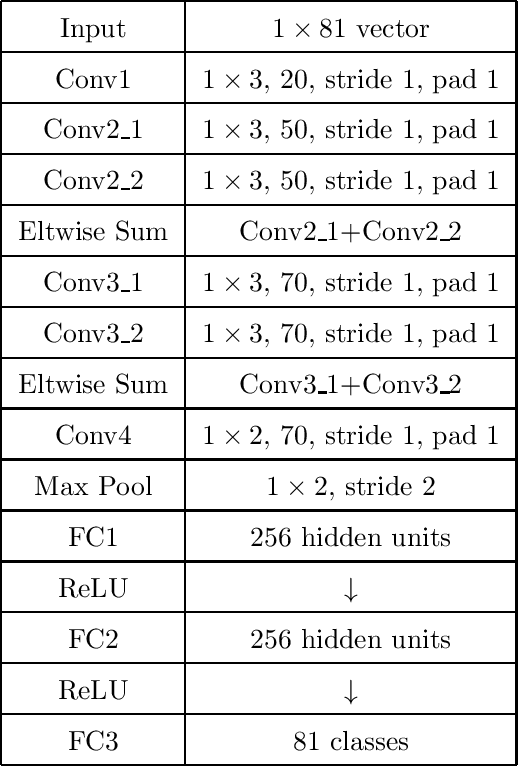
We present a deep recurrent convolutional neural network (CNN) approach to solve the problem of hockey player identification in NHL broadcast videos. Player identification is a difficult computer vision problem mainly because of the players' similar appearance, occlusion, and blurry facial and physical features. However, we can observe players' jersey numbers over time by processing variable length image sequences of players (aka 'tracklets'). We propose an end-to-end trainable ResNet+LSTM network, with a residual network (ResNet) base and a long short-term memory (LSTM) layer, to discover spatio-temporal features of jersey numbers over time and learn long-term dependencies. For this work, we created a new hockey player tracklet dataset that contains sequences of hockey player bounding boxes. Additionally, we employ a secondary 1-dimensional convolutional neural network classifier as a late score-level fusion method to classify the output of the ResNet+LSTM network. This achieves an overall player identification accuracy score over 87% on the test split of our new dataset.
CoCon: A Self-Supervised Approach for Controlled Text Generation
Jun 05, 2020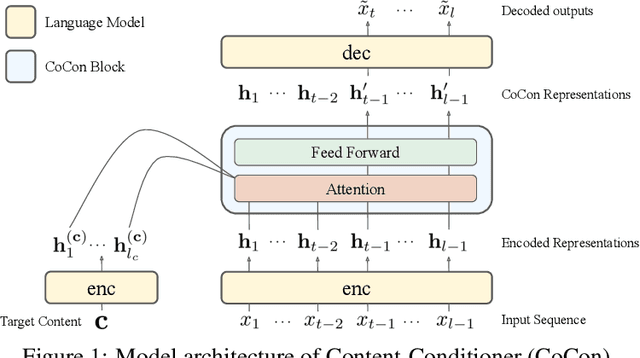
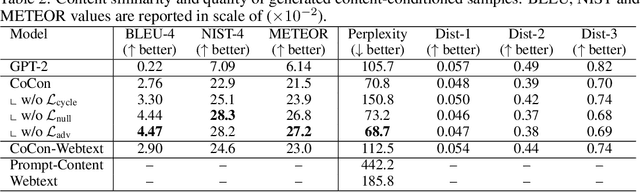
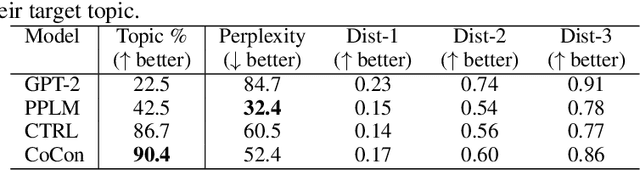
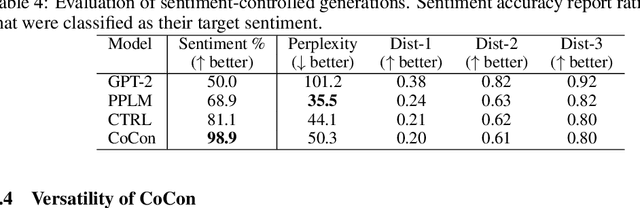
Pretrained Transformer-based language models (LMs) display remarkable natural language generation capabilities. With their immense potential, controlling text generation of such LMs is getting attention. While there are studies that seek to control high-level attributes (such as sentiment and topic) of generated text, there is still a lack of more precise control over its content at the word- and phrase-level. Here, we propose Content-Conditioner (CoCon) to control an LM's output text with a target content, at a fine-grained level. In our self-supervised approach, the CoCon block learns to help the LM complete a partially-observed text sequence by conditioning with content inputs that are withheld from the LM. Through experiments, we show that CoCon can naturally incorporate target content into generated texts and control high-level text attributes in a zero-shot manner.
Jacobian Adversarially Regularized Networks for Robustness
Jan 29, 2020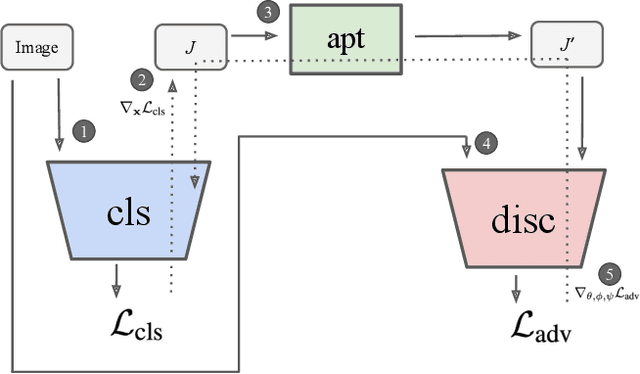
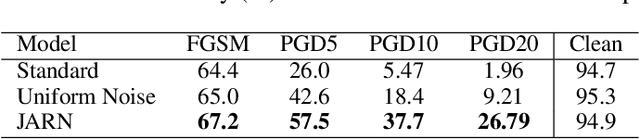
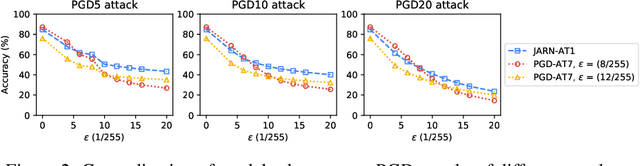
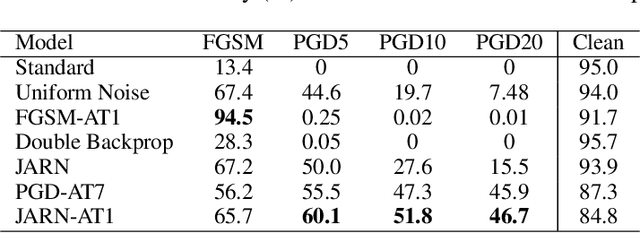
Adversarial examples are crafted with imperceptible perturbations with the intent to fool neural networks. Against such attacks, adversarial training and its variants stand as the strongest defense to date. Previous studies have pointed out that robust models that have undergone adversarial training tend to produce more salient and interpretable Jacobian matrices than their non-robust counterparts. A natural question is whether a model trained with an objective to produce salient Jacobian can result in better robustness. This paper answers this question with affirmative empirical results. We propose Jacobian Adversarially Regularized Networks (JARN) as a method to optimize the saliency of a classifier's Jacobian by adversarially regularizing the model's Jacobian to resemble natural training images. Image classifiers trained with JARN show improved robust accuracy compared to standard models on the MNIST, SVHN and CIFAR-10 datasets, uncovering a new angle to boost robustness without using adversarial training examples.
What it Thinks is Important is Important: Robustness Transfers through Input Gradients
Dec 11, 2019
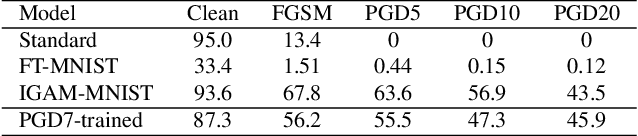
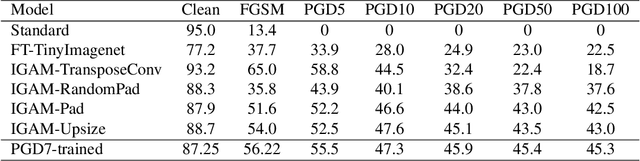
Adversarial perturbations are imperceptible changes to input pixels that can change the prediction of deep learning models. Learned weights of models robust to such perturbations are previously found to be transferable across different tasks but this applies only if the model architecture for the source and target tasks is the same. Input gradients characterize how small changes at each input pixel affect the model output. Using only natural images, we show here that training a student model's input gradients to match those of a robust teacher model can gain robustness close to a strong baseline that is robustly trained from scratch. Through experiments in MNIST, CIFAR-10, CIFAR-100 and Tiny-ImageNet, we show that our proposed method, input gradient adversarial matching, can transfer robustness across different tasks and even across different model architectures. This demonstrates that directly targeting the semantics of input gradients is a feasible way towards adversarial robustness.
Poison as a Cure: Detecting & Neutralizing Variable-Sized Backdoor Attacks in Deep Neural Networks
Nov 19, 2019
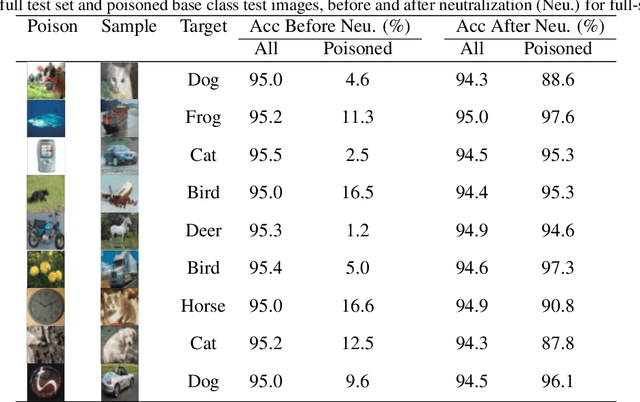
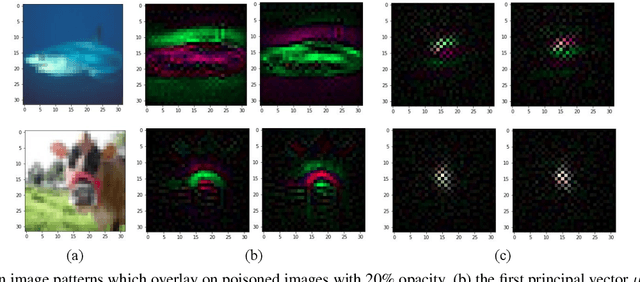
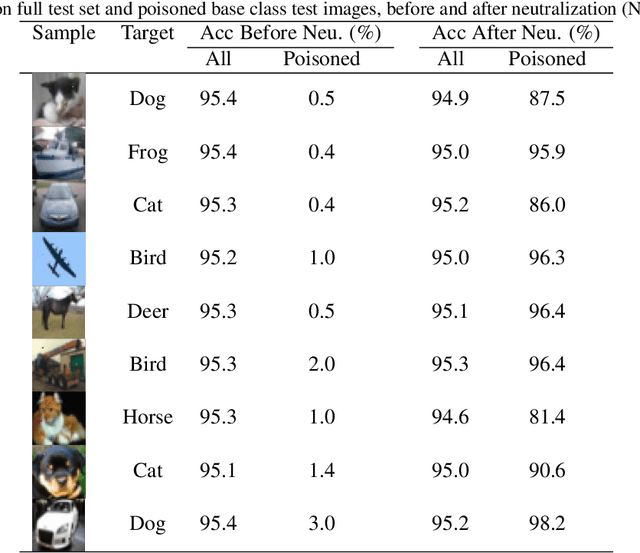
Deep learning models have recently shown to be vulnerable to backdoor poisoning, an insidious attack where the victim model predicts clean images correctly but classifies the same images as the target class when a trigger poison pattern is added. This poison pattern can be embedded in the training dataset by the adversary. Existing defenses are effective under certain conditions such as a small size of the poison pattern, knowledge about the ratio of poisoned training samples or when a validated clean dataset is available. Since a defender may not have such prior knowledge or resources, we propose a defense against backdoor poisoning that is effective even when those prerequisites are not met. It is made up of several parts: one to extract a backdoor poison signal, detect poison target and base classes, and filter out poisoned from clean samples with proven guarantees. The final part of our defense involves retraining the poisoned model on a dataset augmented with the extracted poison signal and corrective relabeling of poisoned samples to neutralize the backdoor. Our approach has shown to be effective in defending against backdoor attacks that use both small and large-sized poison patterns on nine different target-base class pairs from the CIFAR10 dataset.
Metamorphic Relation Based Adversarial Attacks on Differentiable Neural Computer
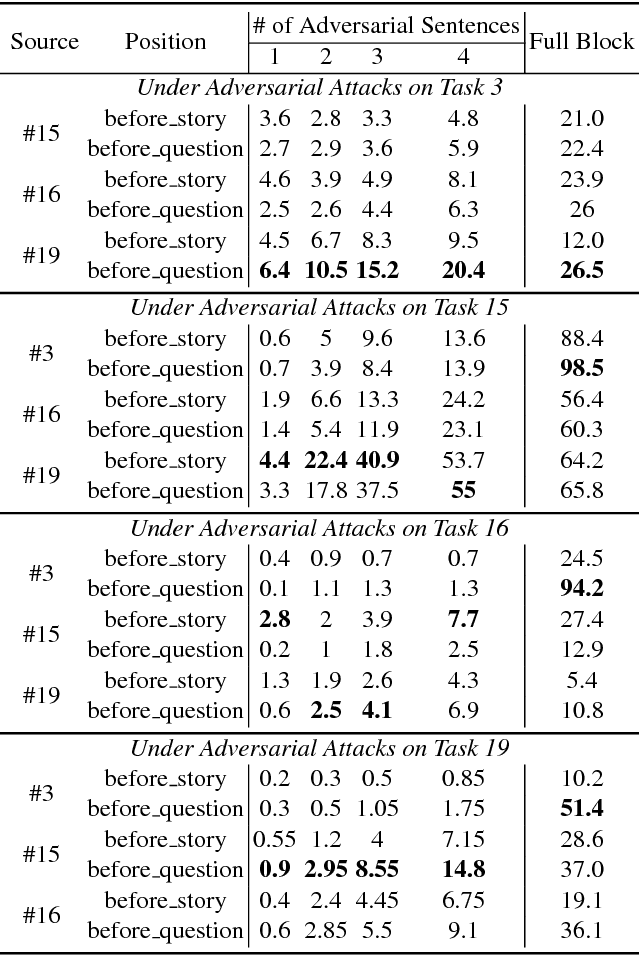
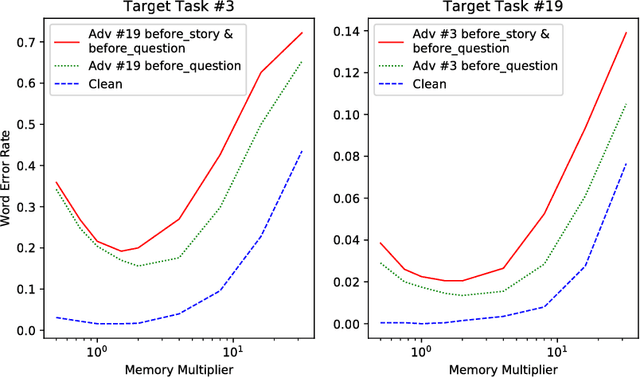
Sep 07, 2018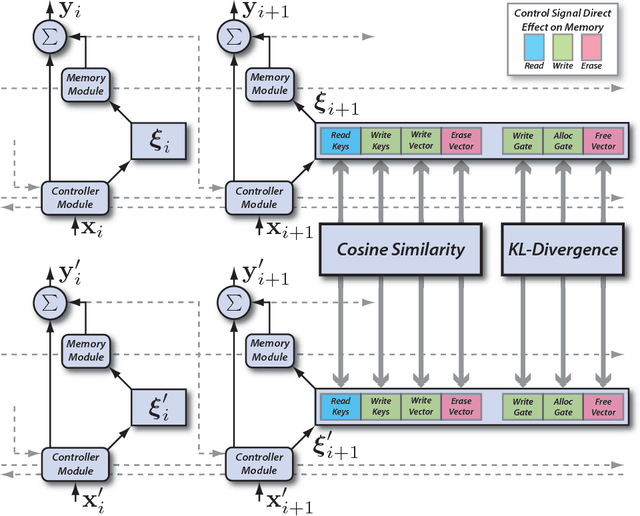
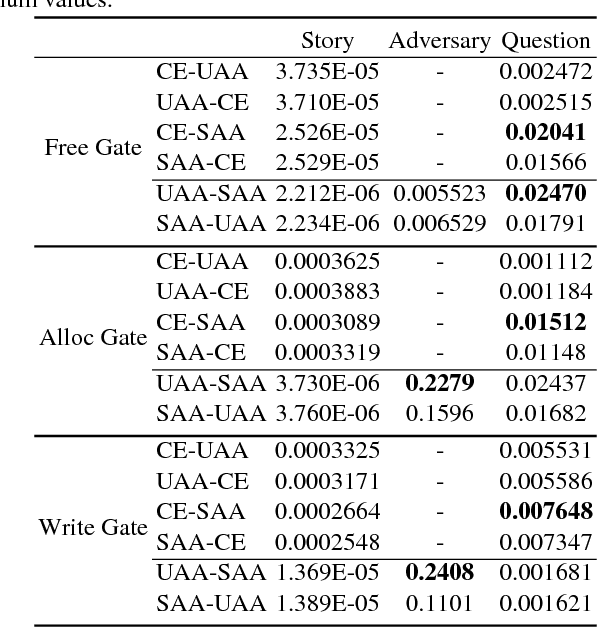
Deep neural networks (DNN), while becoming the driving force of many novel technology and achieving tremendous success in many cutting-edge applications, are still vulnerable to adversarial attacks. Differentiable neural computer (DNC) is a novel computing machine with DNN as its central controller operating on an external memory module for data processing. The unique architecture of DNC contributes to its state-of-the-art performance in tasks which requires the ability to represent variables and data structure as well as to store data over long timescales. However, there still lacks a comprehensive study on how adversarial examples affect DNC in terms of robustness. In this paper, we propose metamorphic relation based adversarial techniques for a range of tasks described in the natural processing language domain. We show that the near-perfect performance of the DNC in bAbI logical question answering tasks can be degraded by adversarially injected sentences. We further perform in-depth study on the role of DNC's memory size in its robustness and analyze the potential reason causing why DNC fails. Our study demonstrates the current challenges and potential opportunities towards constructing more robust DNCs.