 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Zoom In: Cross-View Geo-Localization via Autoregressive Zooming
Mar 26, 2026Cross-view geo-localization (CVGL) estimates a camera's location by matching a street-view image to geo-referenced overhead imagery, enabling GPS-denied localization and navigation. Existing methods almost universally formulate CVGL as an image-retrieval problem in a contrastively trained embedding space. This ties performance to large batches and hard negative mining, and it ignores both the geometric structure of maps and the coverage mismatch between street-view and overhead imagery. In particular, salient landmarks visible from the street view can fall outside a fixed satellite crop, making retrieval targets ambiguous and limiting explicit spatial inference over the map. We propose Just Zoom In, an alternative formulation that performs CVGL via autoregressive zooming over a city-scale overhead map. Starting from a coarse satellite view, the model takes a short sequence of zoom-in decisions to select a terminal satellite cell at a target resolution, without contrastive losses or hard negative mining. We further introduce a realistic benchmark with crowd-sourced street views and high-resolution satellite imagery that reflects real capture conditions. On this benchmark, Just Zoom In achieves state-of-the-art performance, improving Recall@1 within 50 m by 5.5% and Recall@1 within 100 m by 9.6% over the strongest contrastive-retrieval baseline. These results demonstrate the effectiveness of sequential coarse-to-fine spatial reasoning for cross-view geo-localization.
Lightweight Road Environment Segmentation using Vector Quantization
Apr 19, 2025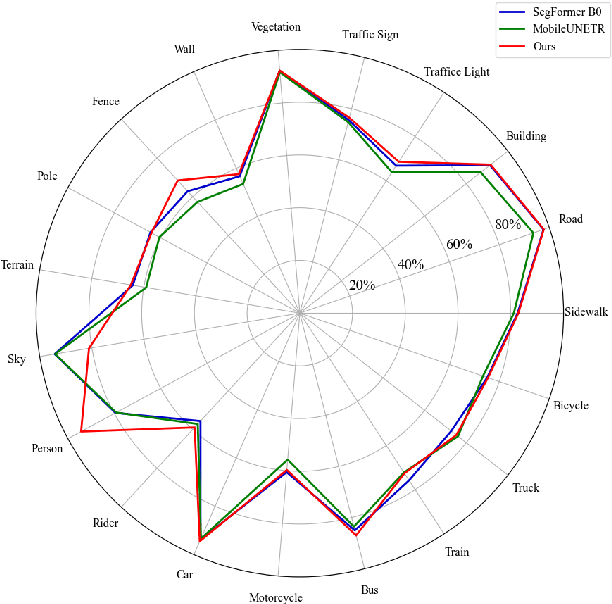

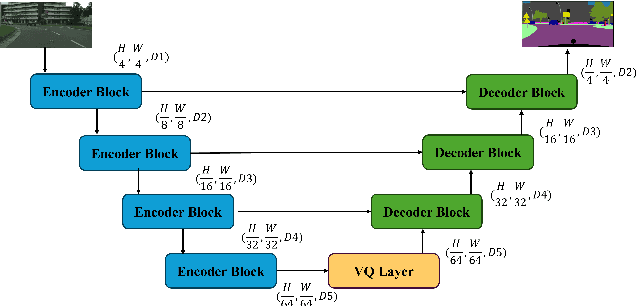
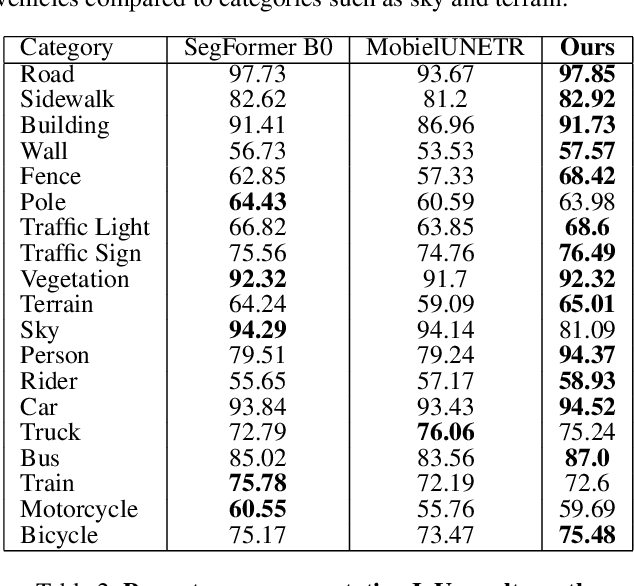
Road environment segmentation plays a significant role in autonomous driving. Numerous works based on Fully Convolutional Networks (FCNs) and Transformer architectures have been proposed to leverage local and global contextual learning for efficient and accurate semantic segmentation. In both architectures, the encoder often relies heavily on extracting continuous representations from the image, which limits the ability to represent meaningful discrete information. To address this limitation, we propose segmentation of the autonomous driving environment using vector quantization. Vector quantization offers three primary advantages for road environment segmentation. (1) Each continuous feature from the encoder is mapped to a discrete vector from the codebook, helping the model discover distinct features more easily than with complex continuous features. (2) Since a discrete feature acts as compressed versions of the encoder's continuous features, they also compress noise or outliers, enhancing the image segmentation task. (3) Vector quantization encourages the latent space to form coarse clusters of continuous features, forcing the model to group similar features, making the learned representations more structured for the decoding process. In this work, we combined vector quantization with the lightweight image segmentation model MobileUNETR and used it as a baseline model for comparison to demonstrate its efficiency. Through experiments, we achieved 77.0 % mIoU on Cityscapes, outperforming the baseline by 2.9 % without increasing the model's initial size or complexity.