 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Classification based on Multiple Block Convolutional Highways
Jul 23, 2018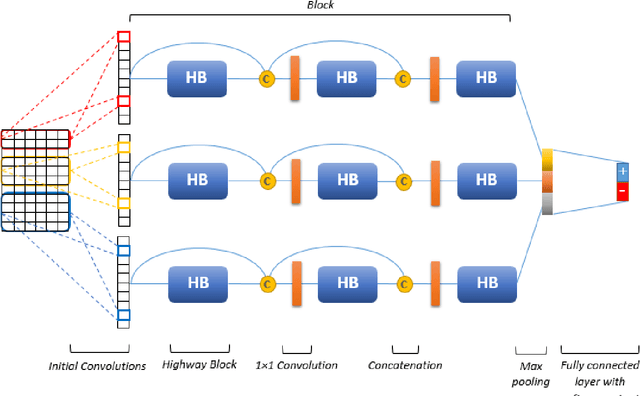
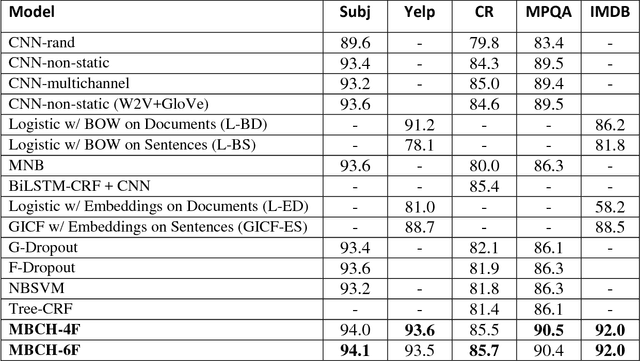
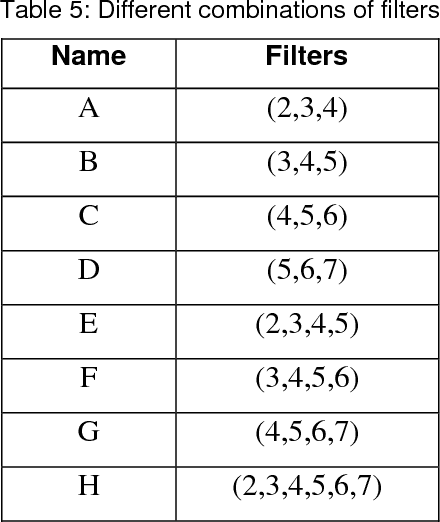
In the Text Classification areas of Sentiment Analysis, Subjectivity/Objectivity Analysis, and Opinion Polarity, Convolutional Neural Networks have gained special attention because of their performance and accuracy. In this work, we applied recent advances in CNNs and propose a novel architecture, Multiple Block Convolutional Highways (MBCH), which achieves improved accuracy on multiple popular benchmark datasets, compared to previous architectures. The MBCH is based on new techniques and architectures including highway networks, DenseNet, batch normalization and bottleneck layers. In addition, to cope with the limitations of existing pre-trained word vectors which are used as inputs for the CNN, we propose a novel method, Improved Word Vectors (IWV). The IWV improves the accuracy of CNNs which are used for text classification tasks.
Robust Locally-Linear Controllable Embedding
Feb 21, 2018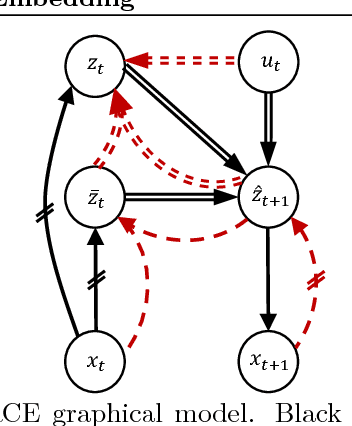
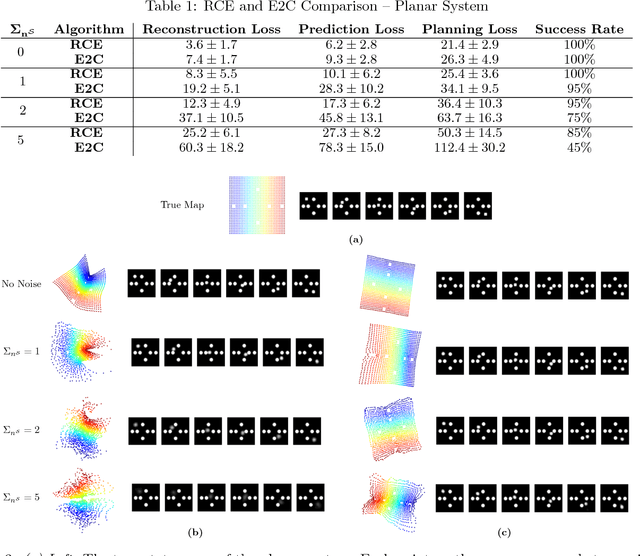
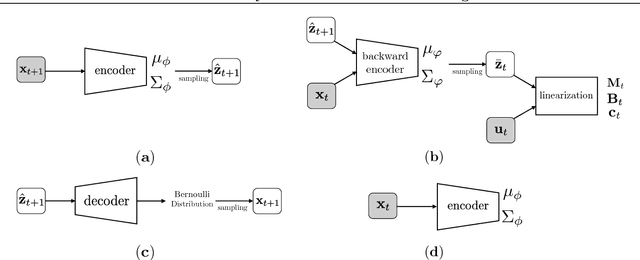
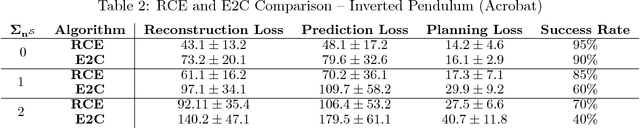
Embed-to-control (E2C) is a model for solving high-dimensional optimal control problems by combining variational auto-encoders with locally-optimal controllers. However, the E2C model suffers from two major drawbacks: 1) its objective function does not correspond to the likelihood of the data sequence and 2) the variational encoder used for embedding typically has large variational approximation error, especially when there is noise in the system dynamics. In this paper, we present a new model for learning robust locally-linear controllable embedding (RCE). Our model directly estimates the predictive conditional density of the future observation given the current one, while introducing the bottleneck between the current and future observations. Although the bottleneck provides a natural embedding candidate for control, our RCE model introduces additional specific structures in the generative graphical model so that the model dynamics can be robustly linearized. We also propose a principled variational approximation of the embedding posterior that takes the future observation into account, and thus, makes the variational approximation more robust against the noise. Experimental results show that RCE outperforms the E2C model, and does so significantly when the underlying dynamics is noisy.
A Berkeley View of Systems Challenges for AI
Dec 15, 2017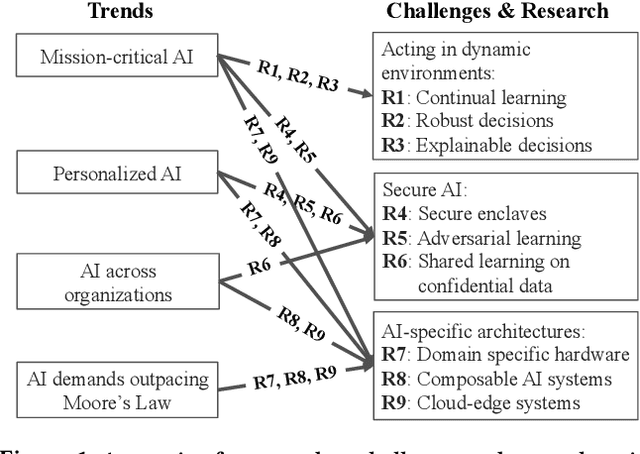
With the increasing commoditization of computer vision, speech recognition and machine translation systems and the widespread deployment of learning-based back-end technologies such as digital advertising and intelligent infrastructures, AI (Artificial Intelligence) has moved from research labs to production. These changes have been made possible by unprecedented levels of data and computation, by methodological advances in machine learning, by innovations in systems software and architectures, and by the broad accessibility of these technologies. The next generation of AI systems promises to accelerate these developments and increasingly impact our lives via frequent interactions and making (often mission-critical) decisions on our behalf, often in highly personalized contexts. Realizing this promise, however, raises daunting challenges. In particular, we need AI systems that make timely and safe decisions in unpredictable environments, that are robust against sophisticated adversaries, and that can process ever increasing amounts of data across organizations and individuals without compromising confidentiality. These challenges will be exacerbated by the end of the Moore's Law, which will constrain the amount of data these technologies can store and process. In this paper, we propose several open research directions in systems, architectures, and security that can address these challenges and help unlock AI's potential to improve lives and society.
Disentangling Dynamics and Content for Control and Planning
Nov 24, 2017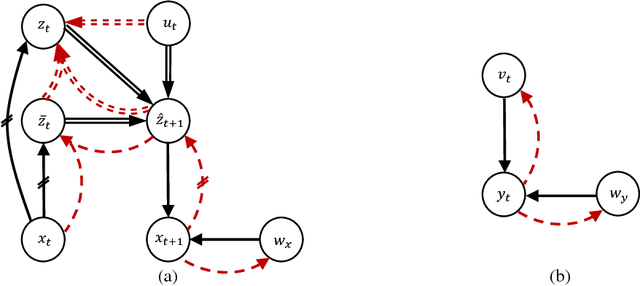
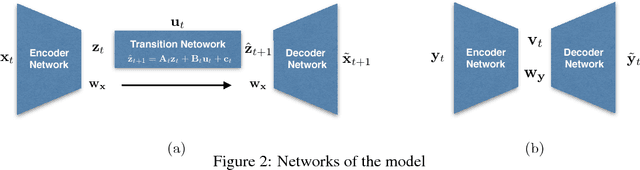
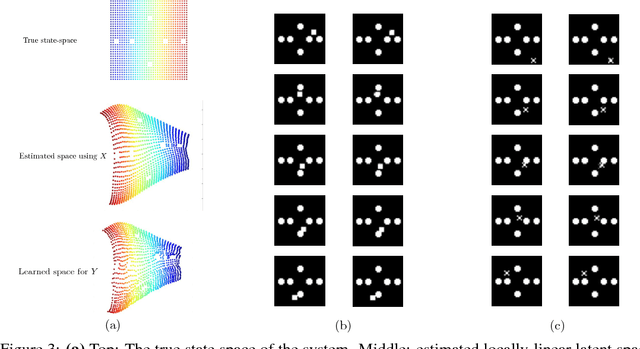
In this paper, We study the problem of learning a controllable representation for high-dimensional observations of dynamical systems. Specifically, we consider a situation where there are multiple sets of observations of dynamical systems with identical underlying dynamics. Only one of these sets has information about the effect of actions on the observation and the rest are just some random observations of the system. Our goal is to utilize the information in that one set and find a representation for the other sets that can be used for planning and ling-term prediction.
JADE: Joint Autoencoders for Dis-Entanglement
Nov 24, 2017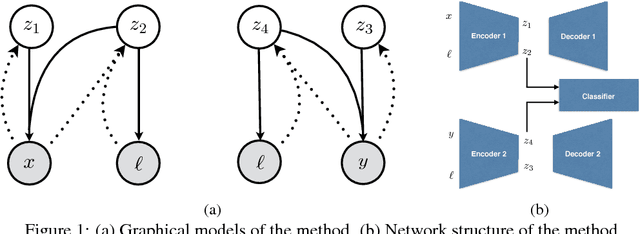


The problem of feature disentanglement has been explored in the literature, for the purpose of image and video processing and text analysis. State-of-the-art methods for disentangling feature representations rely on the presence of many labeled samples. In this work, we present a novel method for disentangling factors of variation in data-scarce regimes. Specifically, we explore the application of feature disentangling for the problem of supervised classification in a setting where few labeled samples exist, and there are no unlabeled samples for use in unsupervised training. Instead, a similar datasets exists which shares at least one direction of variation with the sample-constrained datasets. We train our model end-to-end using the framework of variational autoencoders and are able to experimentally demonstrate that using an auxiliary dataset with similar variation factors contribute positively to classification performance, yielding competitive results with the state-of-the-art in unsupervised learning.
Improving the Accuracy of Pre-trained Word Embeddings for Sentiment Analysis
Nov 23, 2017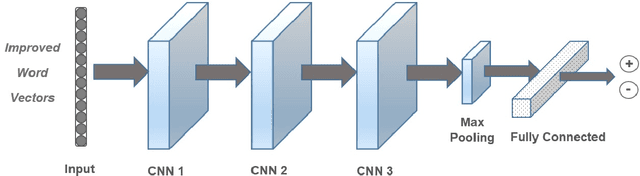
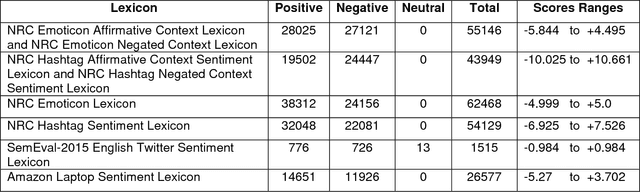
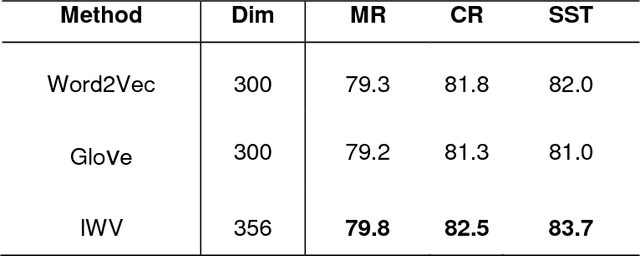
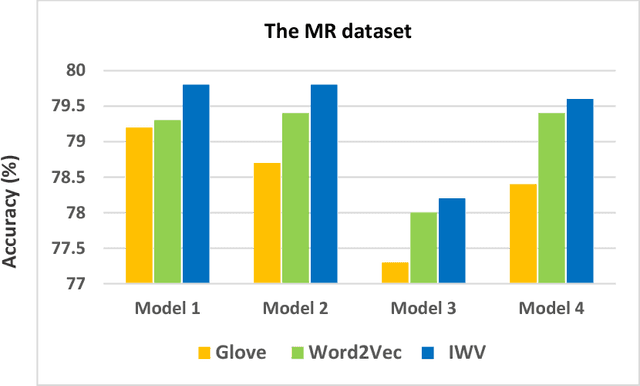
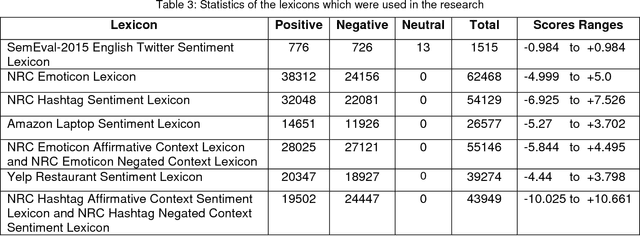
Sentiment analysis is one of the well-known tasks and fast growing research areas in natural language processing (NLP) and text classifications. This technique has become an essential part of a wide range of applications including politics, business, advertising and marketing. There are various techniques for sentiment analysis, but recently word embeddings methods have been widely used in sentiment classification tasks. Word2Vec and GloVe are currently among the most accurate and usable word embedding methods which can convert words into meaningful vectors. However, these methods ignore sentiment information of texts and need a huge corpus of texts for training and generating exact vectors which are used as inputs of deep learning models. As a result, because of the small size of some corpuses, researcher often have to use pre-trained word embeddings which were trained on other large text corpus such as Google News with about 100 billion words. The increasing accuracy of pre-trained word embeddings has a great impact on sentiment analysis research. In this paper we propose a novel method, Improved Word Vectors (IWV), which increases the accuracy of pre-trained word embeddings in sentiment analysis. Our method is based on Part-of-Speech (POS) tagging techniques, lexicon-based approaches and Word2Vec/GloVe methods. We tested the accuracy of our method via different deep learning models and sentiment datasets. Our experiment results show that Improved Word Vectors (IWV) are very effective for sentiment analysis.
Deep Structure for end-to-end inverse rendering
Aug 25, 2017
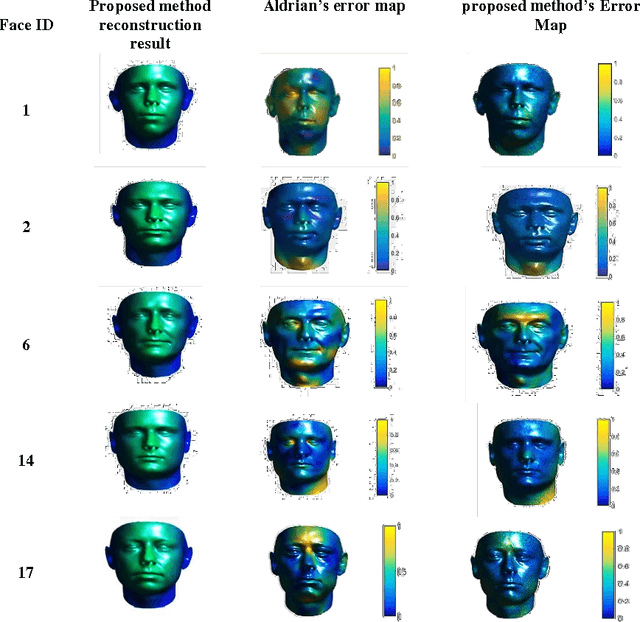
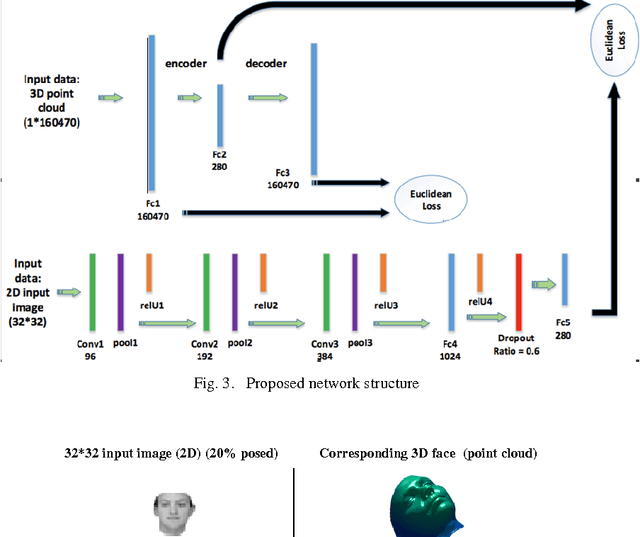

Inverse rendering in a 3D format denoted to recovering the 3D properties of a scene given 2D input image(s) and is typically done using 3D Morphable Model (3DMM) based methods from single view images. These models formulate each face as a weighted combination of some basis vectors extracted from the training data. In this paper a deep framework is proposed in which the coefficients and basis vectors are computed by training an autoencoder network and a Convolutional Neural Network (CNN) simultaneously. The idea is to find a common cause which can be mapped to both the 3D structure and corresponding 2D image using deep networks. The empirical results verify the power of deep framework in finding accurate 3D shapes of human faces from their corresponding 2D images on synthetic datasets of human faces.
Fast Spectral Clustering Using Autoencoders and Landmarks
Apr 07, 2017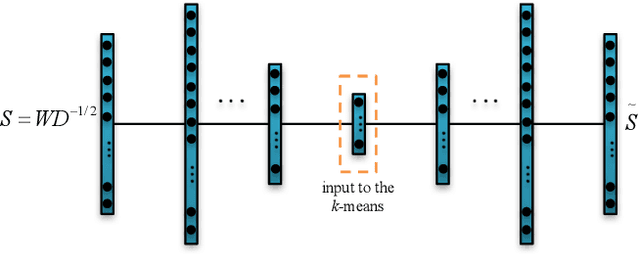

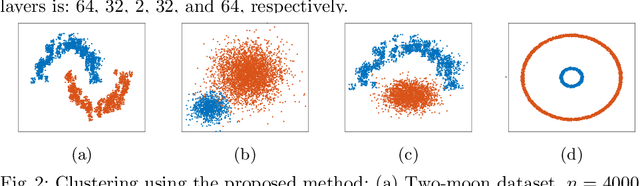
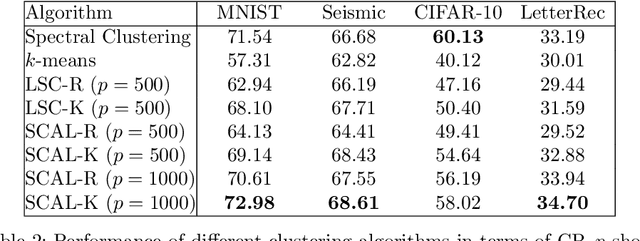
In this paper, we introduce an algorithm for performing spectral clustering efficiently. Spectral clustering is a powerful clustering algorithm that suffers from high computational complexity, due to eigen decomposition. In this work, we first build the adjacency matrix of the corresponding graph of the dataset. To build this matrix, we only consider a limited number of points, called landmarks, and compute the similarity of all data points with the landmarks. Then, we present a definition of the Laplacian matrix of the graph that enable us to perform eigen decomposition efficiently, using a deep autoencoder. The overall complexity of the algorithm for eigen decomposition is $O(np)$, where $n$ is the number of data points and $p$ is the number of landmarks. At last, we evaluate the performance of the algorithm in different experiments.
Semi-Supervised Representation Learning based on Probabilistic Labeling
Sep 15, 2016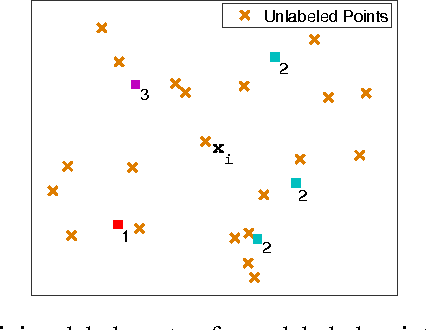
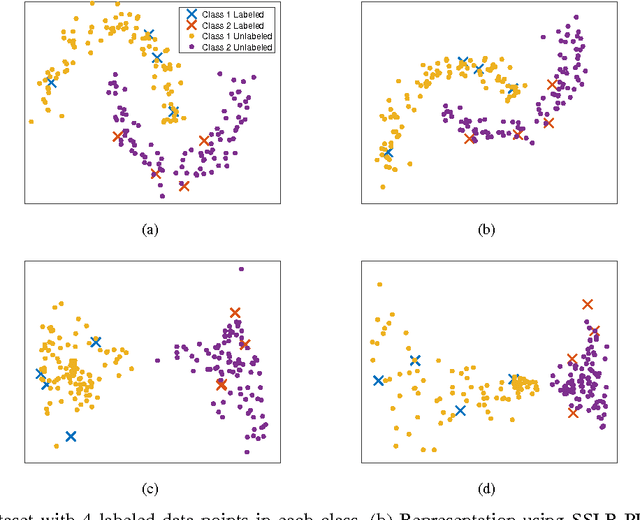
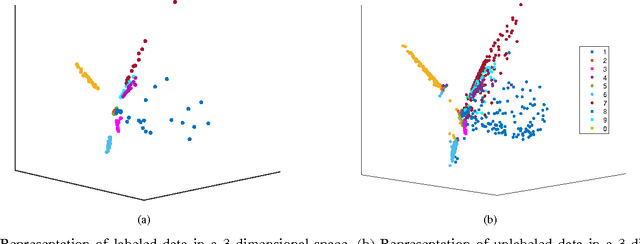
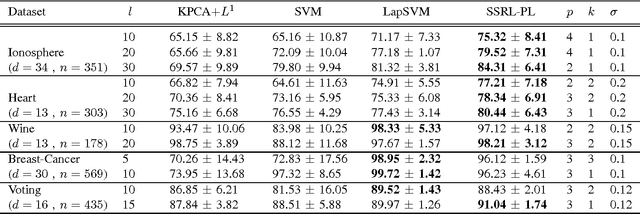
In this paper, we present a new algorithm for semi-supervised representation learning. In this algorithm, we first find a vector representation for the labels of the data points based on their local positions in the space. Then, we map the data to lower-dimensional space using a linear transformation such that the dependency between the transformed data and the assigned labels is maximized. In fact, we try to find a mapping that is as discriminative as possible. The approach will use Hilber-Schmidt Independence Criterion (HSIC) as the dependence measure. We also present a kernelized version of the algorithm, which allows non-linear transformations and provides more flexibility in finding the appropriate mapping. Use of unlabeled data for learning new representation is not always beneficial and there is no algorithm that can deterministically guarantee the improvement of the performance by exploiting unlabeled data. Therefore, we also propose a bound on the performance of the algorithm, which can be used to determine the effectiveness of using the unlabeled data in the algorithm. We demonstrate the ability of the algorithm in finding the transformation using both toy examples and real-world datasets.
Semi-supervised Dictionary Learning Based on Hilbert-Schmidt Independence Criterion
Apr 25, 2016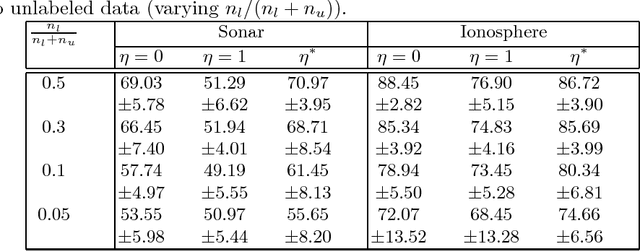
In this paper, a novel semi-supervised dictionary learning and sparse representation (SS-DLSR) is proposed. The proposed method benefits from the supervisory information by learning the dictionary in a space where the dependency between the data and class labels is maximized. This maximization is performed using Hilbert-Schmidt independence criterion (HSIC). On the other hand, the global distribution of the underlying manifolds were learned from the unlabeled data by minimizing the distances between the unlabeled data and the corresponding nearest labeled data in the space of the dictionary learned. The proposed SS-DLSR algorithm has closed-form solutions for both the dictionary and sparse coefficients, and therefore does not have to learn the two iteratively and alternately as is common in the literature of the DLSR. This makes the solution for the proposed algorithm very fast. The experiments confirm the improvement in classification performance on benchmark datasets by including the information from both labeled and unlabeled data, particularly when there are many unlabeled data.