 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow good are deep models in understanding the generated images?
Aug 25, 2022
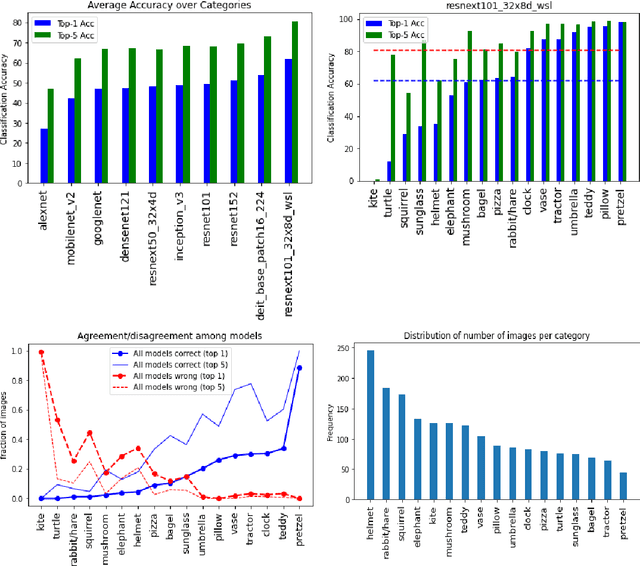


My goal in this paper is twofold: to study how well deep models can understand the images generated by DALL-E 2 and Midjourney, and to quantitatively evaluate these generative models. Two sets of generated images are collected for object recognition and visual question answering (VQA) tasks. On object recognition, the best model, out of 10 state-of-the-art object recognition models, achieves about 60\% and 80\% top-1 and top-5 accuracy, respectively. These numbers are much lower than the best accuracy on the ImageNet dataset (91\% and 99\%). On VQA, the OFA model scores 77.3\% on answering 241 binary questions across 50 images. This model scores 94.7\% on the binary VQA-v2 dataset. Humans are able to recognize the generated images and answer questions on them easily. We conclude that a) deep models struggle to understand the generated content, and may do better after fine-tuning, and b) there is a large distribution shift between the generated images and the real photographs. The distribution shift appears to be category-dependent. Data is available at: https://drive.google.com/file/d/1n2nCiaXtYJRRF2R73-LNE3zggeU_HeH0/view?usp=sharing.
Is current research on adversarial robustness addressing the right problem?
Aug 04, 2022
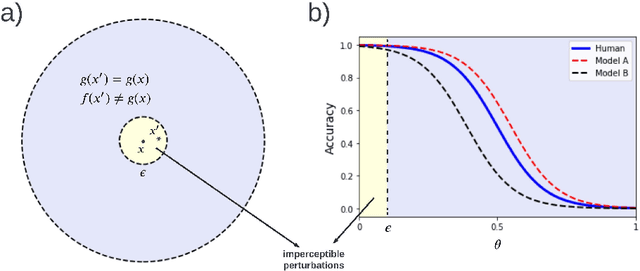
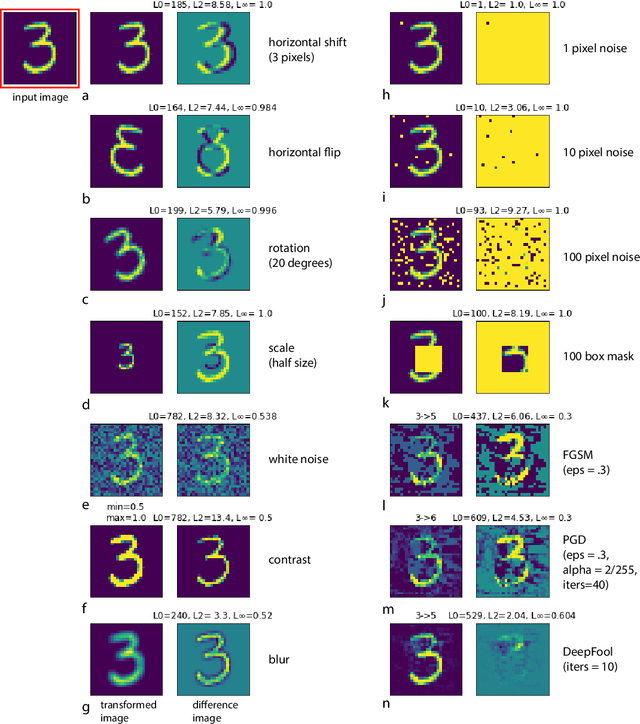
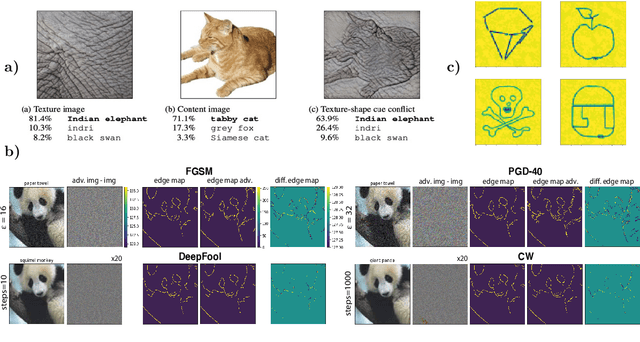
Short answer: Yes, Long answer: No! Indeed, research on adversarial robustness has led to invaluable insights helping us understand and explore different aspects of the problem. Many attacks and defenses have been proposed over the last couple of years. The problem, however, remains largely unsolved and poorly understood. Here, I argue that the current formulation of the problem serves short term goals, and needs to be revised for us to achieve bigger gains. Specifically, the bound on perturbation has created a somewhat contrived setting and needs to be relaxed. This has misled us to focus on model classes that are not expressive enough to begin with. Instead, inspired by human vision and the fact that we rely more on robust features such as shape, vertices, and foreground objects than non-robust features such as texture, efforts should be steered towards looking for significantly different classes of models. Maybe instead of narrowing down on imperceptible adversarial perturbations, we should attack a more general problem which is finding architectures that are simultaneously robust to perceptible perturbations, geometric transformations (e.g. rotation, scaling), image distortions (lighting, blur), and more (e.g. occlusion, shadow). Only then we may be able to solve the problem of adversarial vulnerability.
A New Kind of Adversarial Example
Aug 04, 2022

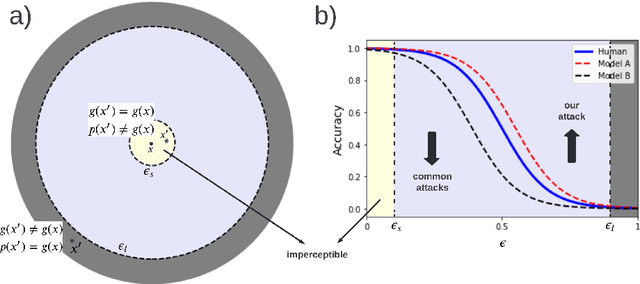
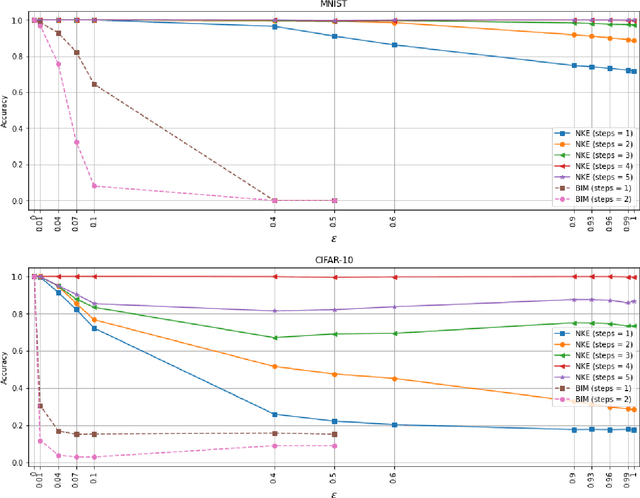
Almost all adversarial attacks are formulated to add an imperceptible perturbation to an image in order to fool a model. Here, we consider the opposite which is adversarial examples that can fool a human but not a model. A large enough and perceptible perturbation is added to an image such that a model maintains its original decision, whereas a human will most likely make a mistake if forced to decide (or opt not to decide at all). Existing targeted attacks can be reformulated to synthesize such adversarial examples. Our proposed attack, dubbed NKE, is similar in essence to the fooling images, but is more efficient since it uses gradient descent instead of evolutionary algorithms. It also offers a new and unified perspective into the problem of adversarial vulnerability. Experimental results over MNIST and CIFAR-10 datasets show that our attack is quite efficient in fooling deep neural networks. Code is available at https://github.com/aliborji/NKE.
SplitMixer: Fat Trimmed From MLP-like Models
Jul 25, 2022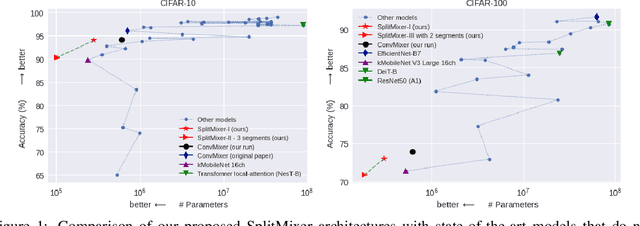
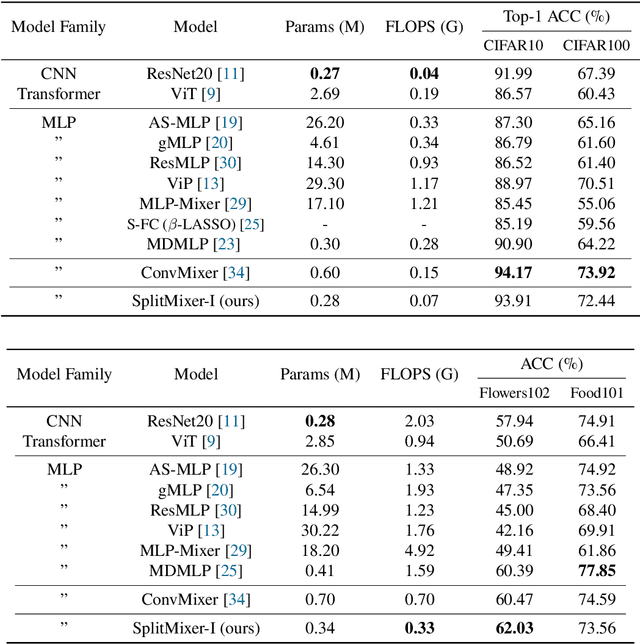
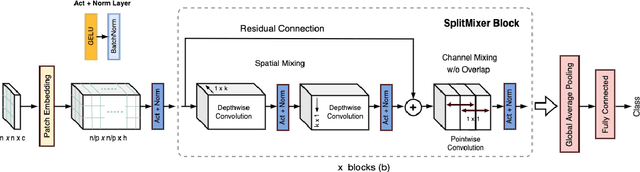
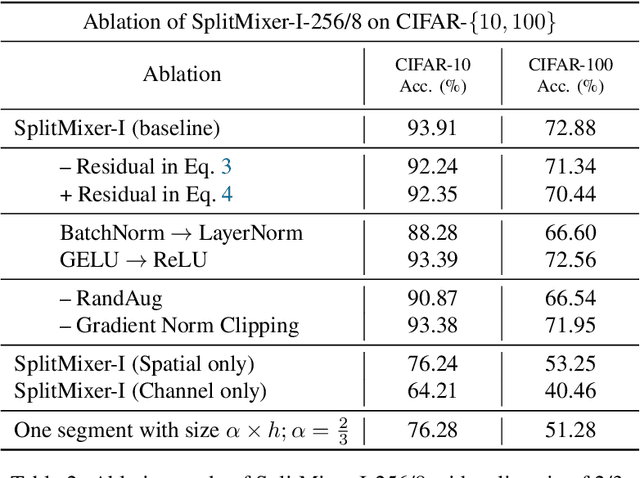
We present SplitMixer, a simple and lightweight isotropic MLP-like architecture, for visual recognition. It contains two types of interleaving convolutional operations to mix information across spatial locations (spatial mixing) and channels (channel mixing). The first one includes sequentially applying two depthwise 1D kernels, instead of a 2D kernel, to mix spatial information. The second one is splitting the channels into overlapping or non-overlapping segments, with or without shared parameters, and applying our proposed channel mixing approaches or 3D convolution to mix channel information. Depending on design choices, a number of SplitMixer variants can be constructed to balance accuracy, the number of parameters, and speed. We show, both theoretically and experimentally, that SplitMixer performs on par with the state-of-the-art MLP-like models while having a significantly lower number of parameters and FLOPS. For example, without strong data augmentation and optimization, SplitMixer achieves around 94% accuracy on CIFAR-10 with only 0.28M parameters, while ConvMixer achieves the same accuracy with about 0.6M parameters. The well-known MLP-Mixer achieves 85.45% with 17.1M parameters. On CIFAR-100 dataset, SplitMixer achieves around 73% accuracy, on par with ConvMixer, but with about 52% fewer parameters and FLOPS. We hope that our results spark further research towards finding more efficient vision architectures and facilitate the development of MLP-like models. Code is available at https://github.com/aliborji/splitmixer.
Complementary datasets to COCO for object detection
Jun 23, 2022
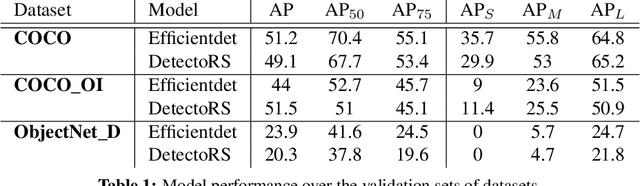
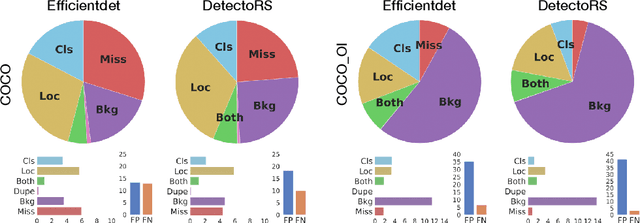
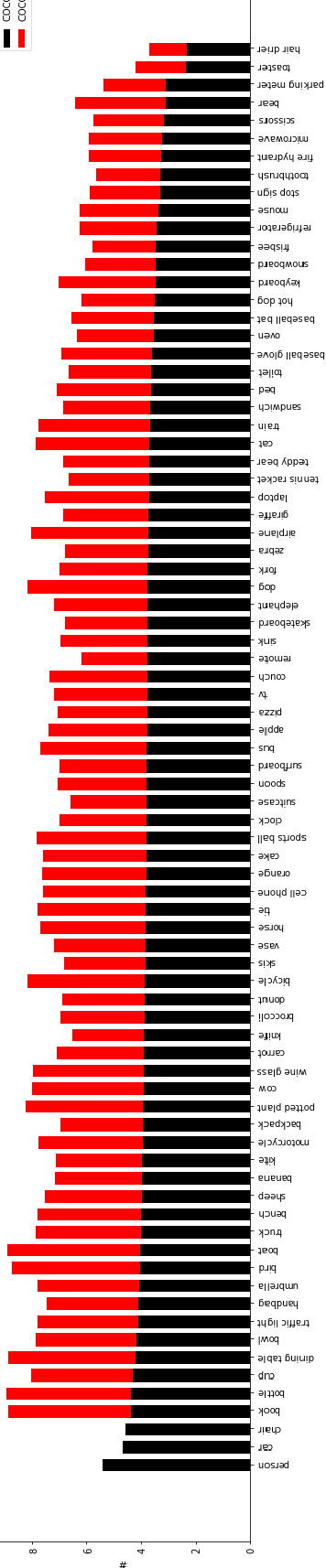
For nearly a decade, the COCO dataset has been the central test bed of research in object detection. According to the recent benchmarks, however, it seems that performance on this dataset has started to saturate. One possible reason can be that perhaps it is not large enough for training deep models. To address this limitation, here we introduce two complementary datasets to COCO: i) COCO_OI, composed of images from COCO and OpenImages (from their 80 classes in common) with 1,418,978 training bounding boxes over 380,111 images, and 41,893 validation bounding boxes over 18,299 images, and ii) ObjectNet_D containing objects in daily life situations (originally created for object recognition known as ObjectNet; 29 categories in common with COCO). The latter can be used to test the generalization ability of object detectors. We evaluate some models on these datasets and pinpoint the source of errors. We encourage the community to utilize these datasets for training and testing object detection models. Code and data is available at https://github.com/aliborji/COCO_OI.
Sensitivity of Average Precision to Bounding Box Perturbations
Jun 21, 2022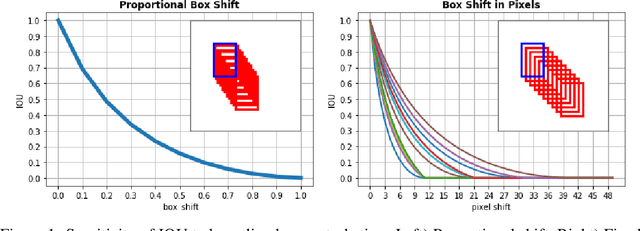
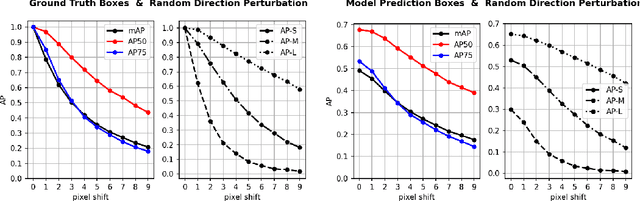
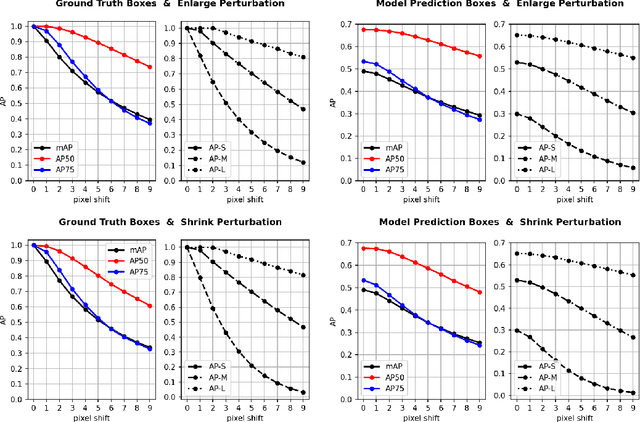
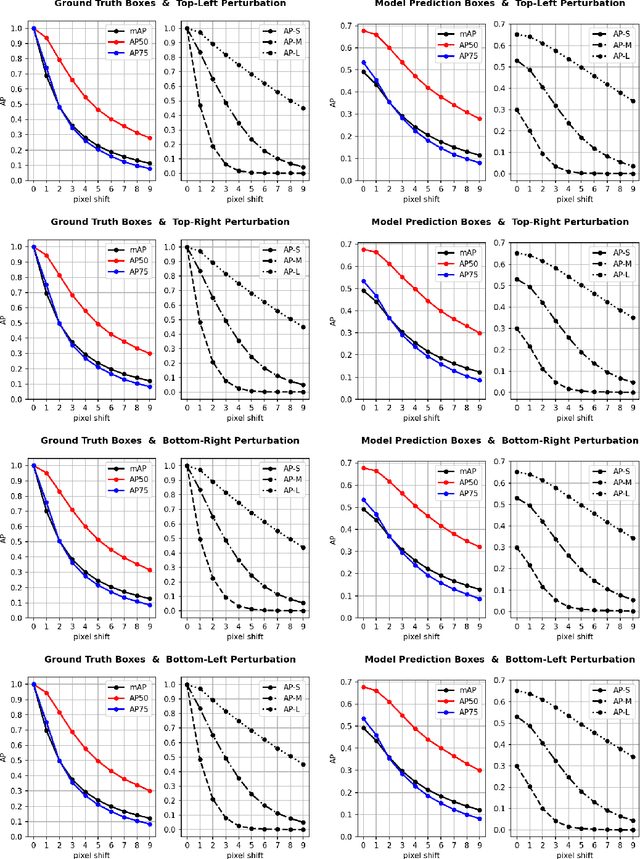
Object detection is a fundamental vision task. It has been highly researched in academia and has been widely adopted in industry. Average Precision (AP) is the standard score for evaluating object detectors. Our understanding of the subtleties of this score, however, is limited. Here, we quantify the sensitivity of AP to bounding box perturbations and show that AP is very sensitive to small translations. Only one pixel shift is enough to drop the mAP of a model by 8.4%. The mAP drop over small objects with only one pixel shift is 23.1%. The corresponding numbers when ground-truth (GT) boxes are used as predictions are 23% and 41.7%, respectively. These results explain why achieving higher mAP becomes increasingly harder as models get better. We also investigate the effect of box scaling on AP. Code and data is available at https://github.com/aliborji/AP_Box_Perturbation.
CNNs and Transformers Perceive Hybrid Images Similar to Humans
Mar 19, 2022

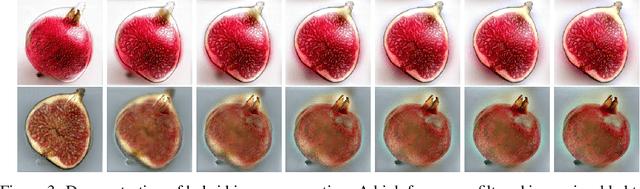
Hybrid images is a technique to generate images with two interpretations that change as a function of viewing distance. It has been utilized to study multiscale processing of images by the human visual system. Using 63,000 hybrid images across 10 fruit categories, here we show that predictions of deep learning vision models qualitatively matches with the human perception of these images. Our results provide yet another evidence in support of the hypothesis that Convolutional Neural Networks (CNNs) and Transformers are good at modeling the feedforward sweep of information in the ventral stream of visual cortex. Code and data is available at https://github.com/aliborji/hybrid_images.git.
Overparametrization improves robustness against adversarial attacks: A replication study
Feb 20, 2022Overparametrization has become a de facto standard in machine learning. Despite numerous efforts, our understanding of how and where overparametrization helps model accuracy and robustness is still limited. To this end, here we conduct an empirical investigation to systemically study and replicate previous findings in this area, in particular the study by Madry et al. Together with this study, our findings support the "universal law of robustness" recently proposed by Bubeck et al. We argue that while critical for robust perception, overparametrization may not be enough to achieve full robustness and smarter architectures e.g. the ones implemented by the human visual cortex) seem inevitable.
Joint Learning of Visual-Audio Saliency Prediction and Sound Source Localization on Multi-face Videos
Nov 05, 2021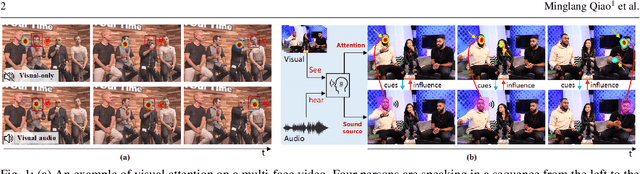
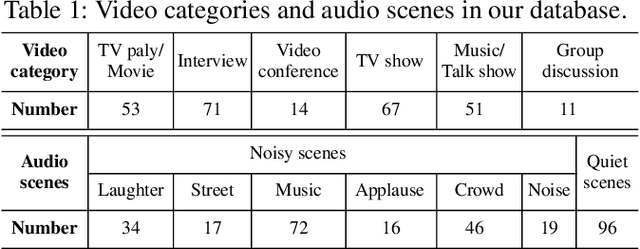

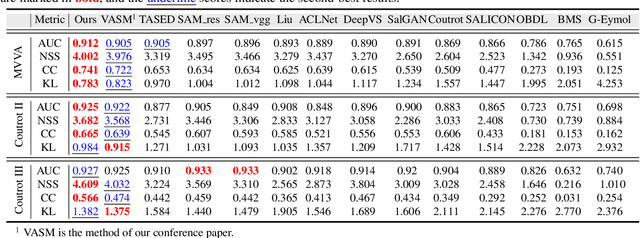
Visual and audio events simultaneously occur and both attract attention. However, most existing saliency prediction works ignore the influence of audio and only consider vision modality. In this paper, we propose a multitask learning method for visual-audio saliency prediction and sound source localization on multi-face video by leveraging visual, audio and face information. Specifically, we first introduce a large-scale database of multi-face video in visual-audio condition (MVVA), containing eye-tracking data and sound source annotations. Using this database, we find that sound influences human attention, and conversly attention offers a cue to determine sound source on multi-face video. Guided by these findings, a visual-audio multi-task network (VAM-Net) is introduced to predict saliency and locate sound source. VAM-Net consists of three branches corresponding to visual, audio and face modalities. Visual branch has a two-stream architecture to capture spatial and temporal information. Face and audio branches encode audio signals and faces, respectively. Finally, a spatio-temporal multi-modal graph (STMG) is constructed to model the interaction among multiple faces. With joint optimization of these branches, the intrinsic correlation of the tasks of saliency prediction and sound source localization is utilized and their performance is boosted by each other. Experiments show that the proposed method outperforms 12 state-of-the-art saliency prediction methods, and achieves competitive results in sound source localization.
Learning to Predict Salient Faces: A Novel Visual-Audio Saliency Model
Mar 29, 2021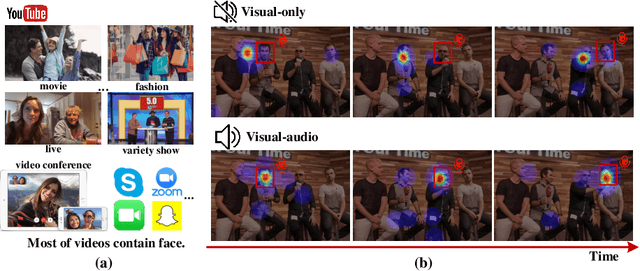
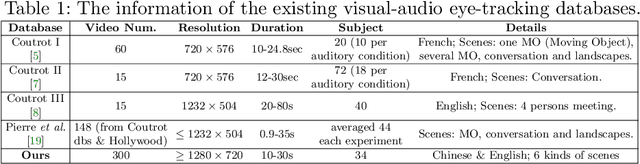
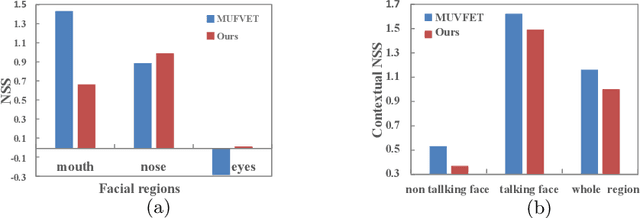
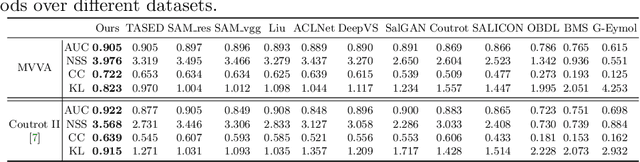
Recently, video streams have occupied a large proportion of Internet traffic, most of which contain human faces. Hence, it is necessary to predict saliency on multiple-face videos, which can provide attention cues for many content based applications. However, most of multiple-face saliency prediction works only consider visual information and ignore audio, which is not consistent with the naturalistic scenarios. Several behavioral studies have established that sound influences human attention, especially during the speech turn-taking in multiple-face videos. In this paper, we thoroughly investigate such influences by establishing a large-scale eye-tracking database of Multiple-face Video in Visual-Audio condition (MVVA). Inspired by the findings of our investigation, we propose a novel multi-modal video saliency model consisting of three branches: visual, audio and face. The visual branch takes the RGB frames as the input and encodes them into visual feature maps. The audio and face branches encode the audio signal and multiple cropped faces, respectively. A fusion module is introduced to integrate the information from three modalities, and to generate the final saliency map. Experimental results show that the proposed method outperforms 11 state-of-the-art saliency prediction works. It performs closer to human multi-modal attention.