 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUL-QMoE: Multiple Non-crossing Quantile Mixture-of-Experts for Probabilistic Remaining Useful Life Predictions of Varying Battery Materials
Dec 19, 2025Lithium-ion batteries are the major type of battery used in a variety of everyday applications, including electric vehicles (EVs), mobile devices, and energy storage systems. Predicting the Remaining Useful Life (RUL) of Li-ion batteries is crucial for ensuring their reliability, safety, and cost-effectiveness in battery-powered systems. The materials used for the battery cathodes and their designs play a significant role in determining the degradation rates and RUL, as they lead to distinct electrochemical reactions. Unfortunately, RUL prediction models often overlook the cathode materials and designs to simplify the model-building process, ignoring the effects of these electrochemical reactions. Other reasons are that specifications related to battery materials may not always be readily available, and a battery might consist of a mix of different materials. As a result, the predictive models that are developed often lack generalizability. To tackle these challenges, this paper proposes a novel material-based Mixture-of-Experts (MoE) approach for predicting the RUL of batteries, specifically addressing the complexities associated with heterogeneous battery chemistries. The MoE is integrated into a probabilistic framework, called Multiple Non-crossing Quantile Mixture-of-Experts for Probabilistic Prediction (RUL-QMoE), which accommodates battery operational conditions and enables uncertainty quantification. The RUL-QMoE model integrates specialized expert networks for five battery types: LFP, NCA, NMC, LCO, and NMC-LCO, within a gating mechanism that dynamically assigns relevance based on the battery's input features. Furthermore, by leveraging non-crossing quantile regression, the proposed RUL-QMoE produces coherent and interpretable predictive distributions of the battery's RUL, enabling robust uncertainty quantification in the battery's RUL prediction.
Synthetic Data Generation and Differential Privacy using Tensor Networks' Matrix Product States (MPS)
Aug 08, 2025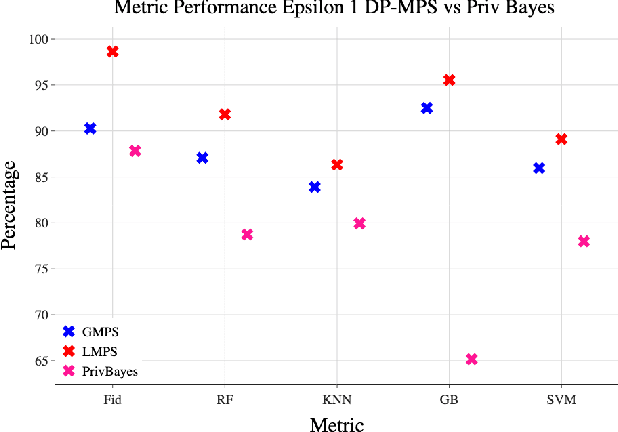
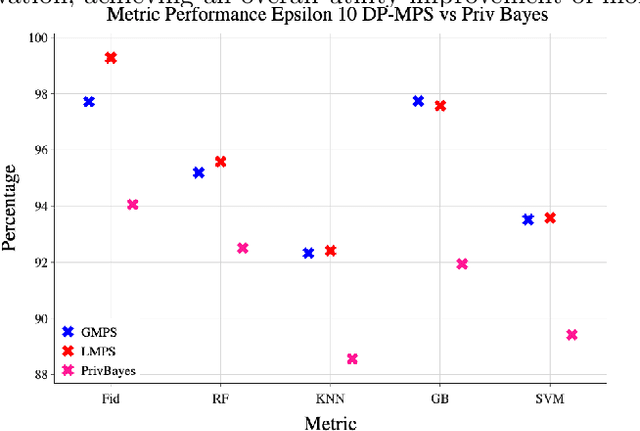
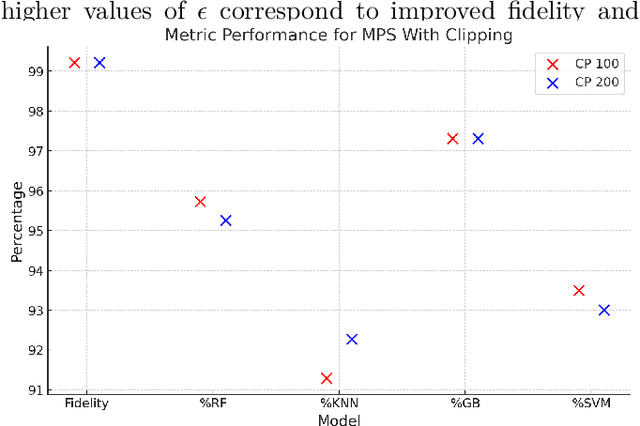
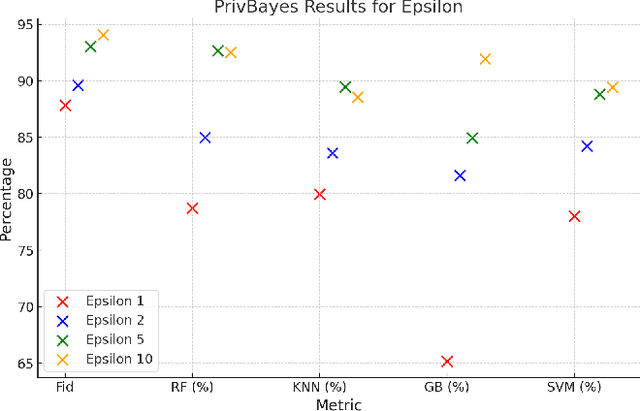
Synthetic data generation is a key technique in modern artificial intelligence, addressing data scarcity, privacy constraints, and the need for diverse datasets in training robust models. In this work, we propose a method for generating privacy-preserving high-quality synthetic tabular data using Tensor Networks, specifically Matrix Product States (MPS). We benchmark the MPS-based generative model against state-of-the-art models such as CTGAN, VAE, and PrivBayes, focusing on both fidelity and privacy-preserving capabilities. To ensure differential privacy (DP), we integrate noise injection and gradient clipping during training, enabling privacy guarantees via R\'enyi Differential Privacy accounting. Across multiple metrics analyzing data fidelity and downstream machine learning task performance, our results show that MPS outperforms classical models, particularly under strict privacy constraints. This work highlights MPS as a promising tool for privacy-aware synthetic data generation. By combining the expressive power of tensor network representations with formal privacy mechanisms, the proposed approach offers an interpretable and scalable alternative for secure data sharing. Its structured design facilitates integration into sensitive domains where both data quality and confidentiality are critical.
Word and Phrase Features in Graph Convolutional Network for Automatic Question Classification
Sep 04, 2024



Effective question classification is crucial for AI-driven educational tools, enabling adaptive learning systems to categorize questions by skill area, difficulty level, and competence. This classification not only supports educational diagnostics and analytics but also enhances complex tasks like information retrieval and question answering by associating questions with relevant categories. Traditional methods, often based on word embeddings and conventional classifiers, struggle to capture the nuanced relationships in natural language, leading to suboptimal performance. To address this, we propose a novel approach leveraging graph convolutional networks (GCNs), named Phrase Question-Graph Convolutional Network (PQ-GCN) to better model the inherent structure of questions. By representing questions as graphs -- where nodes signify words or phrases and edges denote syntactic or semantic relationships -- our method allows GCNs to learn from the interconnected nature of language more effectively. Additionally, we explore the incorporation of phrase-based features to enhance classification accuracy, especially in low-resource settings. Our findings demonstrate that GCNs, augmented with these features, offer a promising solution for more accurate and context-aware question classification, bridging the gap between graph neural network research and practical educational applications.