 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtistic style transfer for videos
Oct 19, 2016
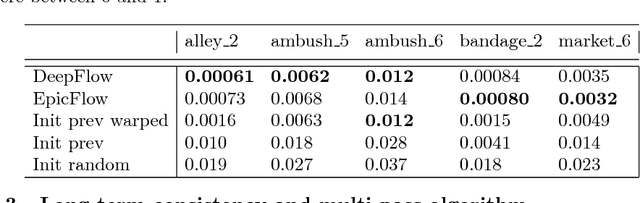


In the past, manually re-drawing an image in a certain artistic style required a professional artist and a long time. Doing this for a video sequence single-handed was beyond imagination. Nowadays computers provide new possibilities. We present an approach that transfers the style from one image (for example, a painting) to a whole video sequence. We make use of recent advances in style transfer in still images and propose new initializations and loss functions applicable to videos. This allows us to generate consistent and stable stylized video sequences, even in cases with large motion and strong occlusion. We show that the proposed method clearly outperforms simpler baselines both qualitatively and quantitatively.
* final version appeared in GCPR-2016; minor changes to improve the clarity
Multi-view 3D Models from Single Images with a Convolutional Network
Aug 02, 2016


We present a convolutional network capable of inferring a 3D representation of a previously unseen object given a single image of this object. Concretely, the network can predict an RGB image and a depth map of the object as seen from an arbitrary view. Several of these depth maps fused together give a full point cloud of the object. The point cloud can in turn be transformed into a surface mesh. The network is trained on renderings of synthetic 3D models of cars and chairs. It successfully deals with objects on cluttered background and generates reasonable predictions for real images of cars.
Inverting Visual Representations with Convolutional Networks
Apr 26, 2016
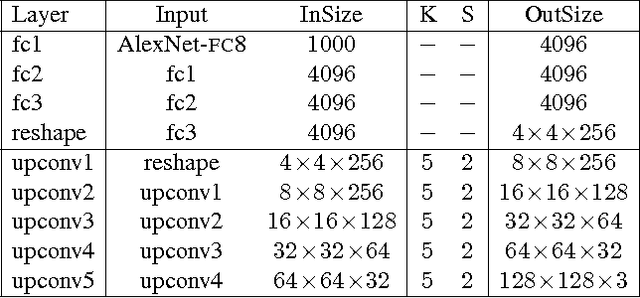


Feature representations, both hand-designed and learned ones, are often hard to analyze and interpret, even when they are extracted from visual data. We propose a new approach to study image representations by inverting them with an up-convolutional neural network. We apply the method to shallow representations (HOG, SIFT, LBP), as well as to deep networks. For shallow representations our approach provides significantly better reconstructions than existing methods, revealing that there is surprisingly rich information contained in these features. Inverting a deep network trained on ImageNet provides several insights into the properties of the feature representation learned by the network. Most strikingly, the colors and the rough contours of an image can be reconstructed from activations in higher network layers and even from the predicted class probabilities.
Generating Images with Perceptual Similarity Metrics based on Deep Networks
Feb 09, 2016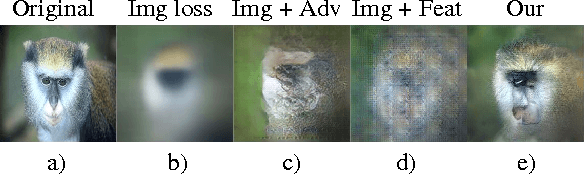

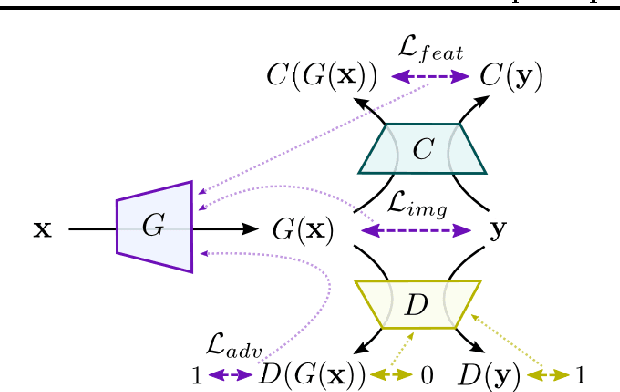
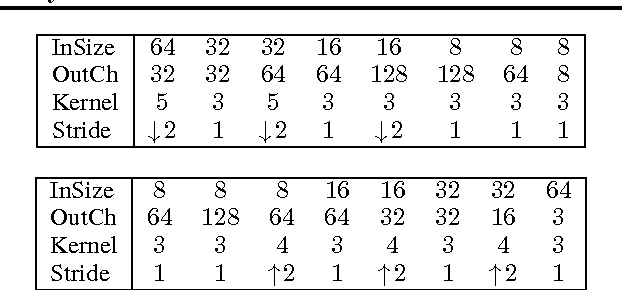
Image-generating machine learning models are typically trained with loss functions based on distance in the image space. This often leads to over-smoothed results. We propose a class of loss functions, which we call deep perceptual similarity metrics (DeePSiM), that mitigate this problem. Instead of computing distances in the image space, we compute distances between image features extracted by deep neural networks. This metric better reflects perceptually similarity of images and thus leads to better results. We show three applications: autoencoder training, a modification of a variational autoencoder, and inversion of deep convolutional networks. In all cases, the generated images look sharp and resemble natural images.
A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation
Dec 07, 2015
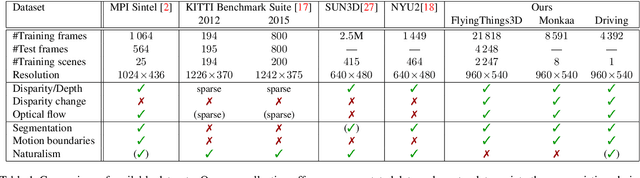

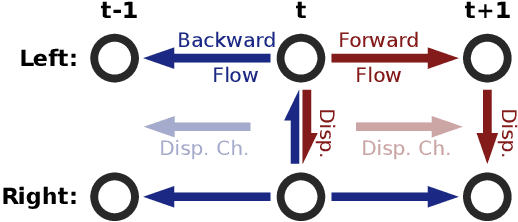
Recent work has shown that optical flow estimation can be formulated as a supervised learning task and can be successfully solved with convolutional networks. Training of the so-called FlowNet was enabled by a large synthetically generated dataset. The present paper extends the concept of optical flow estimation via convolutional networks to disparity and scene flow estimation. To this end, we propose three synthetic stereo video datasets with sufficient realism, variation, and size to successfully train large networks. Our datasets are the first large-scale datasets to enable training and evaluating scene flow methods. Besides the datasets, we present a convolutional network for real-time disparity estimation that provides state-of-the-art results. By combining a flow and disparity estimation network and training it jointly, we demonstrate the first scene flow estimation with a convolutional network.
Descriptor Matching with Convolutional Neural Networks: a Comparison to SIFT
Jun 24, 2015
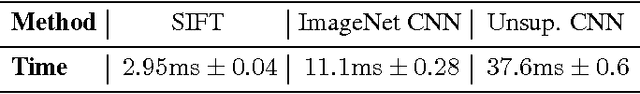


Latest results indicate that features learned via convolutional neural networks outperform previous descriptors on classification tasks by a large margin. It has been shown that these networks still work well when they are applied to datasets or recognition tasks different from those they were trained on. However, descriptors like SIFT are not only used in recognition but also for many correspondence problems that rely on descriptor matching. In this paper we compare features from various layers of convolutional neural nets to standard SIFT descriptors. We consider a network that was trained on ImageNet and another one that was trained without supervision. Surprisingly, convolutional neural networks clearly outperform SIFT on descriptor matching. This paper has been merged with arXiv:1406.6909
Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
Jun 19, 2015
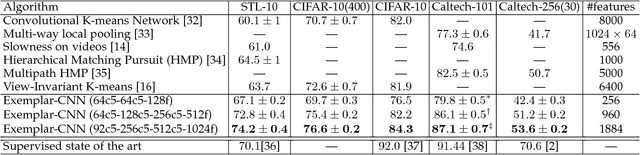

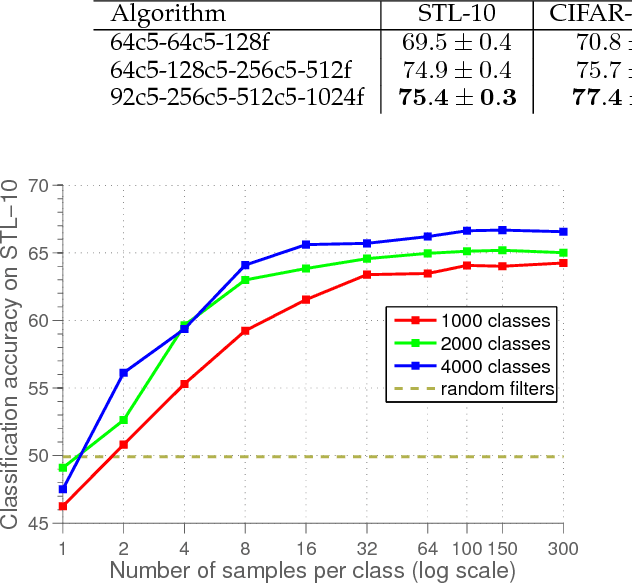
Deep convolutional networks have proven to be very successful in learning task specific features that allow for unprecedented performance on various computer vision tasks. Training of such networks follows mostly the supervised learning paradigm, where sufficiently many input-output pairs are required for training. Acquisition of large training sets is one of the key challenges, when approaching a new task. In this paper, we aim for generic feature learning and present an approach for training a convolutional network using only unlabeled data. To this end, we train the network to discriminate between a set of surrogate classes. Each surrogate class is formed by applying a variety of transformations to a randomly sampled 'seed' image patch. In contrast to supervised network training, the resulting feature representation is not class specific. It rather provides robustness to the transformations that have been applied during training. This generic feature representation allows for classification results that outperform the state of the art for unsupervised learning on several popular datasets (STL-10, CIFAR-10, Caltech-101, Caltech-256). While such generic features cannot compete with class specific features from supervised training on a classification task, we show that they are advantageous on geometric matching problems, where they also outperform the SIFT descriptor.
FlowNet: Learning Optical Flow with Convolutional Networks
May 04, 2015
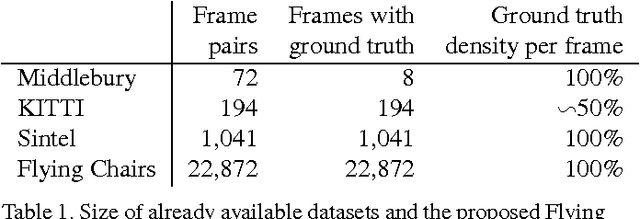

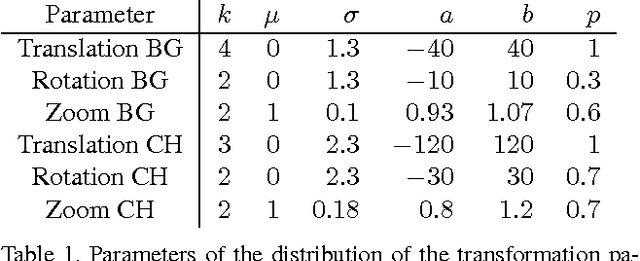
Convolutional neural networks (CNNs) have recently been very successful in a variety of computer vision tasks, especially on those linked to recognition. Optical flow estimation has not been among the tasks where CNNs were successful. In this paper we construct appropriate CNNs which are capable of solving the optical flow estimation problem as a supervised learning task. We propose and compare two architectures: a generic architecture and another one including a layer that correlates feature vectors at different image locations. Since existing ground truth data sets are not sufficiently large to train a CNN, we generate a synthetic Flying Chairs dataset. We show that networks trained on this unrealistic data still generalize very well to existing datasets such as Sintel and KITTI, achieving competitive accuracy at frame rates of 5 to 10 fps.
Striving for Simplicity: The All Convolutional Net
Apr 13, 2015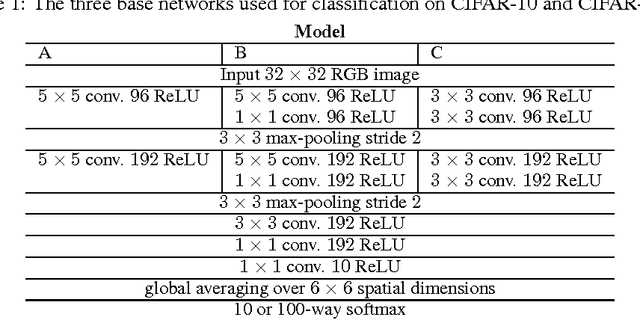
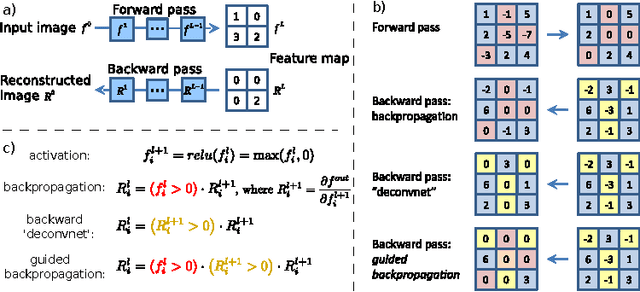
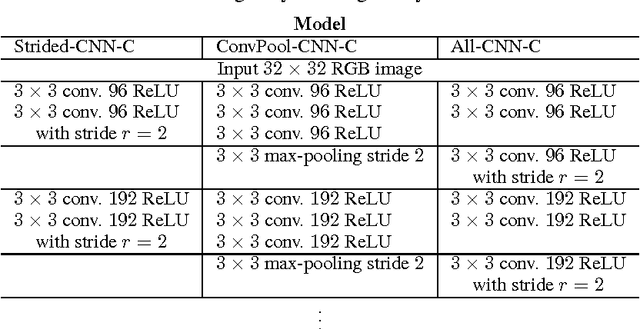

Most modern convolutional neural networks (CNNs) used for object recognition are built using the same principles: Alternating convolution and max-pooling layers followed by a small number of fully connected layers. We re-evaluate the state of the art for object recognition from small images with convolutional networks, questioning the necessity of different components in the pipeline. We find that max-pooling can simply be replaced by a convolutional layer with increased stride without loss in accuracy on several image recognition benchmarks. Following this finding -- and building on other recent work for finding simple network structures -- we propose a new architecture that consists solely of convolutional layers and yields competitive or state of the art performance on several object recognition datasets (CIFAR-10, CIFAR-100, ImageNet). To analyze the network we introduce a new variant of the "deconvolution approach" for visualizing features learned by CNNs, which can be applied to a broader range of network structures than existing approaches.
Unsupervised feature learning by augmenting single images
Feb 16, 2014
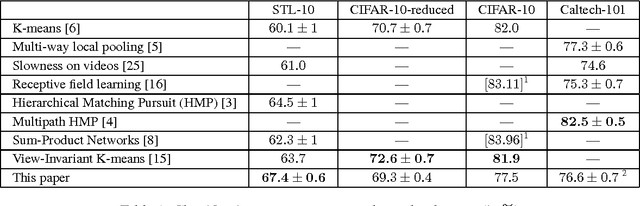
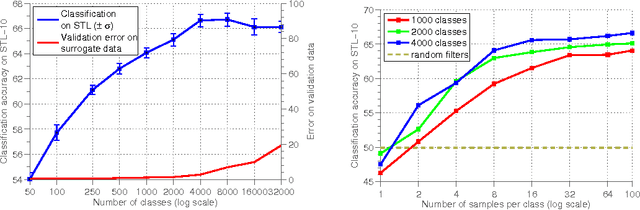
When deep learning is applied to visual object recognition, data augmentation is often used to generate additional training data without extra labeling cost. It helps to reduce overfitting and increase the performance of the algorithm. In this paper we investigate if it is possible to use data augmentation as the main component of an unsupervised feature learning architecture. To that end we sample a set of random image patches and declare each of them to be a separate single-image surrogate class. We then extend these trivial one-element classes by applying a variety of transformations to the initial 'seed' patches. Finally we train a convolutional neural network to discriminate between these surrogate classes. The feature representation learned by the network can then be used in various vision tasks. We find that this simple feature learning algorithm is surprisingly successful, achieving competitive classification results on several popular vision datasets (STL-10, CIFAR-10, Caltech-101).