 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Sampling Patterns for Compressed Sensing MRI with Diffusion Generative Models
Jun 05, 2023



Diffusion-based generative models have been used as powerful priors for magnetic resonance imaging (MRI) reconstruction. We present a learning method to optimize sub-sampling patterns for compressed sensing multi-coil MRI that leverages pre-trained diffusion generative models. Crucially, during training we use a single-step reconstruction based on the posterior mean estimate given by the diffusion model and the MRI measurement process. Experiments across varying anatomies, acceleration factors, and pattern types show that sampling operators learned with our method lead to competitive, and in the case of 2D patterns, improved reconstructions compared to baseline patterns. Our method requires as few as five training images to learn effective sampling patterns.
Ambient Diffusion: Learning Clean Distributions from Corrupted Data
May 30, 2023



We present the first diffusion-based framework that can learn an unknown distribution using only highly-corrupted samples. This problem arises in scientific applications where access to uncorrupted samples is impossible or expensive to acquire. Another benefit of our approach is the ability to train generative models that are less likely to memorize individual training samples since they never observe clean training data. Our main idea is to introduce additional measurement distortion during the diffusion process and require the model to predict the original corrupted image from the further corrupted image. We prove that our method leads to models that learn the conditional expectation of the full uncorrupted image given this additional measurement corruption. This holds for any corruption process that satisfies some technical conditions (and in particular includes inpainting and compressed sensing). We train models on standard benchmarks (CelebA, CIFAR-10 and AFHQ) and show that we can learn the distribution even when all the training samples have $90\%$ of their pixels missing. We also show that we can finetune foundation models on small corrupted datasets (e.g. MRI scans with block corruptions) and learn the clean distribution without memorizing the training set.
Restoration-Degradation Beyond Linear Diffusions: A Non-Asymptotic Analysis For DDIM-Type Samplers
Mar 06, 2023We develop a framework for non-asymptotic analysis of deterministic samplers used for diffusion generative modeling. Several recent works have analyzed stochastic samplers using tools like Girsanov's theorem and a chain rule variant of the interpolation argument. Unfortunately, these techniques give vacuous bounds when applied to deterministic samplers. We give a new operational interpretation for deterministic sampling by showing that one step along the probability flow ODE can be expressed as two steps: 1) a restoration step that runs gradient ascent on the conditional log-likelihood at some infinitesimally previous time, and 2) a degradation step that runs the forward process using noise pointing back towards the current iterate. This perspective allows us to extend denoising diffusion implicit models to general, non-linear forward processes. We then develop the first polynomial convergence bounds for these samplers under mild conditions on the data distribution.
Consistent Diffusion Models: Mitigating Sampling Drift by Learning to be Consistent
Feb 17, 2023



Imperfect score-matching leads to a shift between the training and the sampling distribution of diffusion models. Due to the recursive nature of the generation process, errors in previous steps yield sampling iterates that drift away from the training distribution. Yet, the standard training objective via Denoising Score Matching (DSM) is only designed to optimize over non-drifted data. To train on drifted data, we propose to enforce a \emph{consistency} property which states that predictions of the model on its own generated data are consistent across time. Theoretically, we show that if the score is learned perfectly on some non-drifted points (via DSM) and if the consistency property is enforced everywhere, then the score is learned accurately everywhere. Empirically we show that our novel training objective yields state-of-the-art results for conditional and unconditional generation in CIFAR-10 and baseline improvements in AFHQ and FFHQ. We open-source our code and models: https://github.com/giannisdaras/cdm
Multiresolution Textual Inversion
Nov 30, 2022We extend Textual Inversion to learn pseudo-words that represent a concept at different resolutions. This allows us to generate images that use the concept with different levels of detail and also to manipulate different resolutions using language. Once learned, the user can generate images at different levels of agreement to the original concept; "A photo of $S^*(0)$" produces the exact object while the prompt "A photo of $S^*(0.8)$" only matches the rough outlines and colors. Our framework allows us to generate images that use different resolutions of an image (e.g. details, textures, styles) as separate pseudo-words that can be composed in various ways. We open-soure our code in the following URL: https://github.com/giannisdaras/multires_textual_inversion
Zonotope Domains for Lagrangian Neural Network Verification
Oct 14, 2022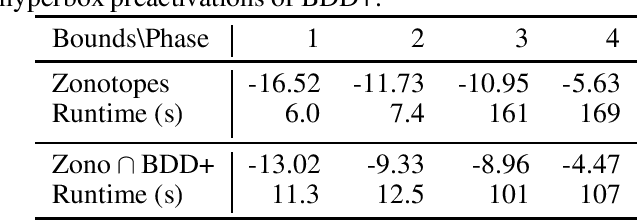
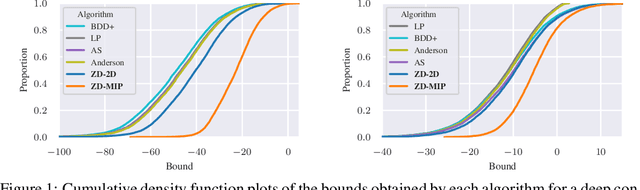
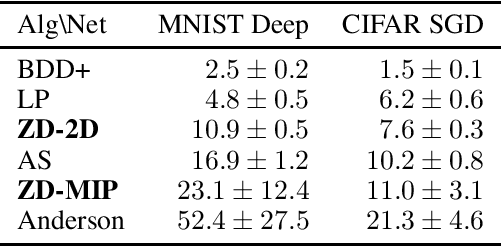
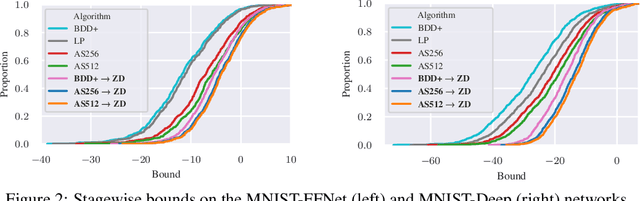
Neural network verification aims to provide provable bounds for the output of a neural network for a given input range. Notable prior works in this domain have either generated bounds using abstract domains, which preserve some dependency between intermediate neurons in the network; or framed verification as an optimization problem and solved a relaxation using Lagrangian methods. A key drawback of the latter technique is that each neuron is treated independently, thereby ignoring important neuron interactions. We provide an approach that merges these two threads and uses zonotopes within a Lagrangian decomposition. Crucially, we can decompose the problem of verifying a deep neural network into the verification of many 2-layer neural networks. While each of these problems is provably hard, we provide efficient relaxation methods that are amenable to efficient dual ascent procedures. Our technique yields bounds that improve upon both linear programming and Lagrangian-based verification techniques in both time and bound tightness.
Soft Diffusion: Score Matching for General Corruptions
Sep 12, 2022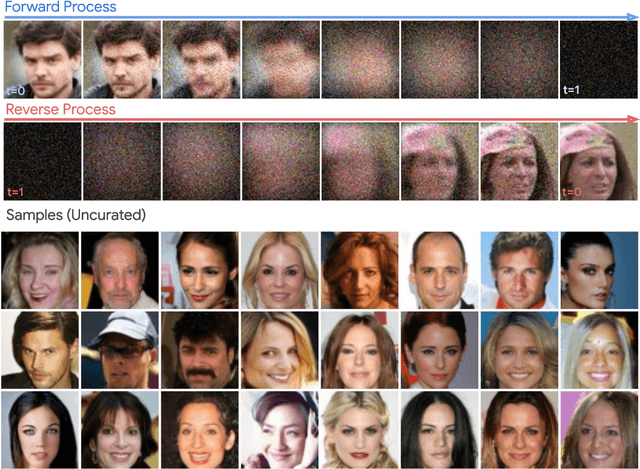

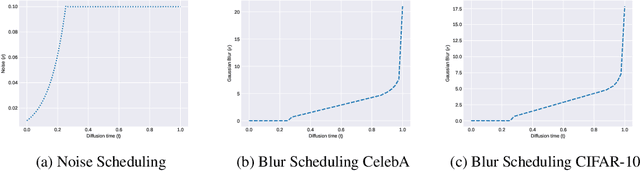

We define a broader family of corruption processes that generalizes previously known diffusion models. To reverse these general diffusions, we propose a new objective called Soft Score Matching that provably learns the score function for any linear corruption process and yields state of the art results for CelebA. Soft Score Matching incorporates the degradation process in the network and trains the model to predict a clean image that after corruption matches the diffused observation. We show that our objective learns the gradient of the likelihood under suitable regularity conditions for the family of corruption processes. We further develop a principled way to select the corruption levels for general diffusion processes and a novel sampling method that we call Momentum Sampler. We evaluate our framework with the corruption being Gaussian Blur and low magnitude additive noise. Our method achieves state-of-the-art FID score $1.85$ on CelebA-64, outperforming all previous linear diffusion models. We also show significant computational benefits compared to vanilla denoising diffusion.
Score-Guided Intermediate Layer Optimization: Fast Langevin Mixing for Inverse Problems
Jun 22, 2022

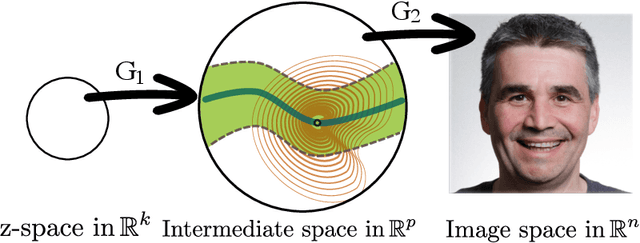
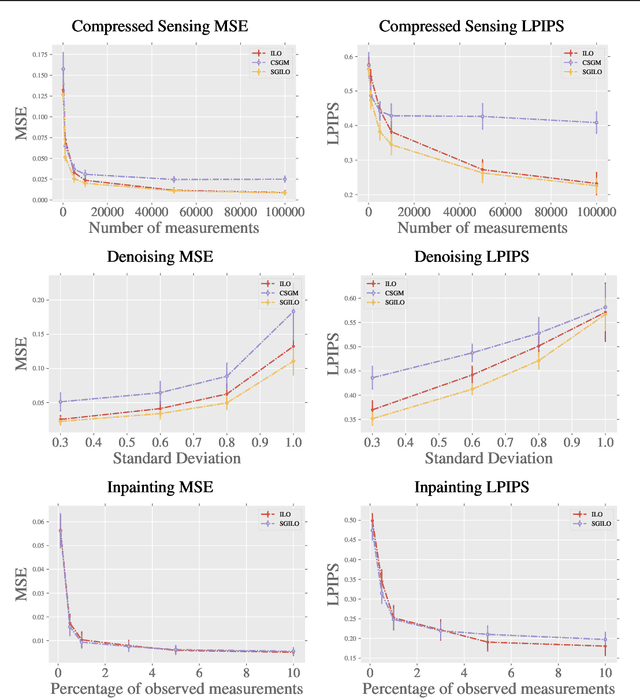
We prove fast mixing and characterize the stationary distribution of the Langevin Algorithm for inverting random weighted DNN generators. This result extends the work of Hand and Voroninski from efficient inversion to efficient posterior sampling. In practice, to allow for increased expressivity, we propose to do posterior sampling in the latent space of a pre-trained generative model. To achieve that, we train a score-based model in the latent space of a StyleGAN-2 and we use it to solve inverse problems. Our framework, Score-Guided Intermediate Layer Optimization (SGILO), extends prior work by replacing the sparsity regularization with a generative prior in the intermediate layer. Experimentally, we obtain significant improvements over the previous state-of-the-art, especially in the low measurement regime.
Discovering the Hidden Vocabulary of DALLE-2
Jun 01, 2022

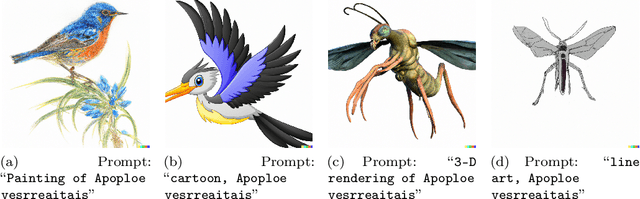

We discover that DALLE-2 seems to have a hidden vocabulary that can be used to generate images with absurd prompts. For example, it seems that \texttt{Apoploe vesrreaitais} means birds and \texttt{Contarra ccetnxniams luryca tanniounons} (sometimes) means bugs or pests. We find that these prompts are often consistent in isolation but also sometimes in combinations. We present our black-box method to discover words that seem random but have some correspondence to visual concepts. This creates important security and interpretability challenges.
Deblurring via Stochastic Refinement
Dec 28, 2021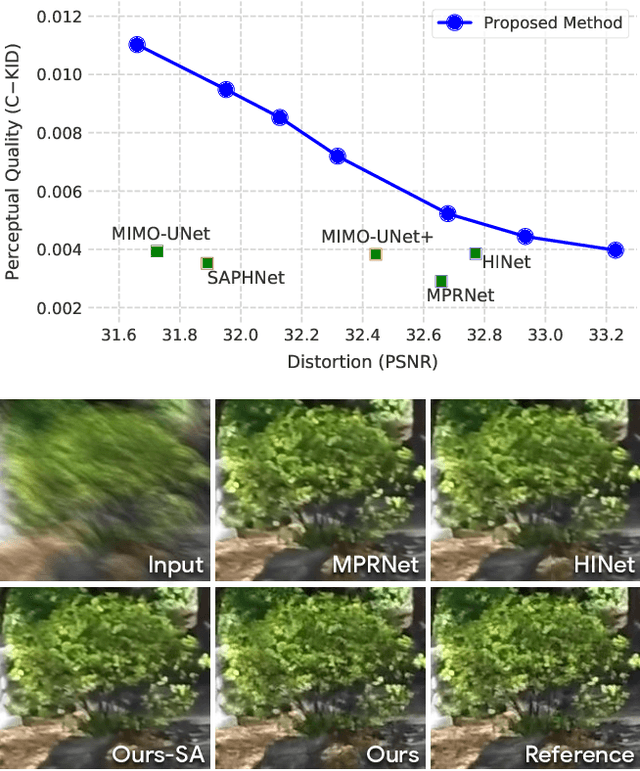
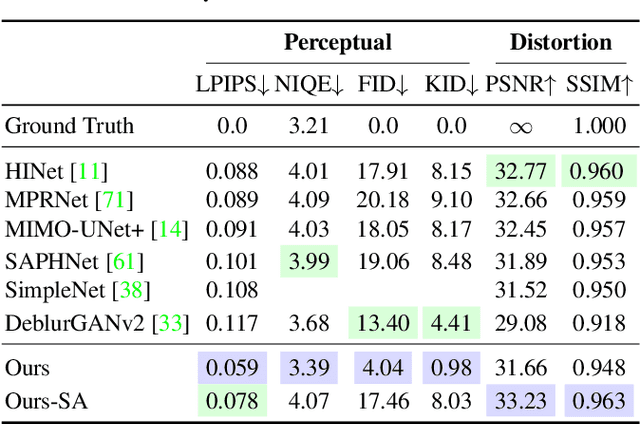
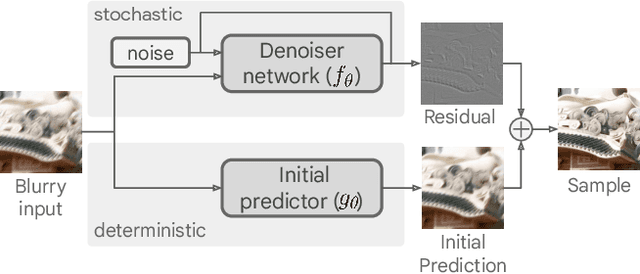

Image deblurring is an ill-posed problem with multiple plausible solutions for a given input image. However, most existing methods produce a deterministic estimate of the clean image and are trained to minimize pixel-level distortion. These metrics are known to be poorly correlated with human perception, and often lead to unrealistic reconstructions. We present an alternative framework for blind deblurring based on conditional diffusion models. Unlike existing techniques, we train a stochastic sampler that refines the output of a deterministic predictor and is capable of producing a diverse set of plausible reconstructions for a given input. This leads to a significant improvement in perceptual quality over existing state-of-the-art methods across multiple standard benchmarks. Our predict-and-refine approach also enables much more efficient sampling compared to typical diffusion models. Combined with a carefully tuned network architecture and inference procedure, our method is competitive in terms of distortion metrics such as PSNR. These results show clear benefits of our diffusion-based method for deblurring and challenge the widely used strategy of producing a single, deterministic reconstruction.