 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluate & Evaluation on the Hub: Better Best Practices for Data and Model Measurements
Oct 06, 2022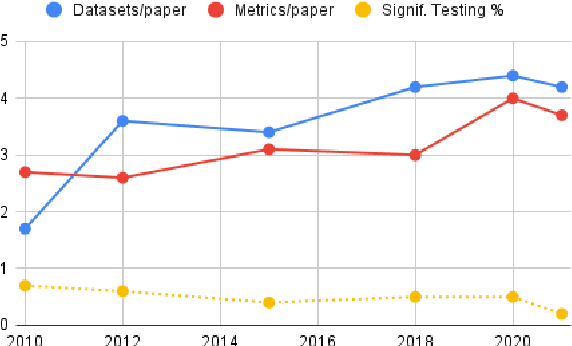
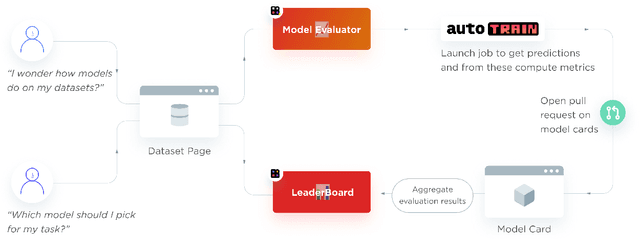
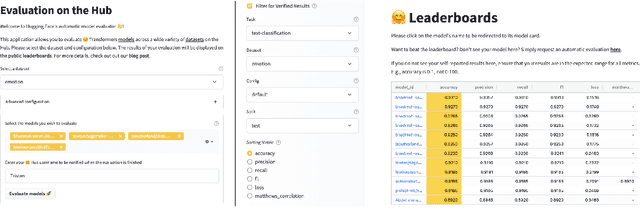
Evaluation is a key part of machine learning (ML), yet there is a lack of support and tooling to enable its informed and systematic practice. We introduce Evaluate and Evaluation on the Hub --a set of tools to facilitate the evaluation of models and datasets in ML. Evaluate is a library to support best practices for measurements, metrics, and comparisons of data and models. Its goal is to support reproducibility of evaluation, centralize and document the evaluation process, and broaden evaluation to cover more facets of model performance. It includes over 50 efficient canonical implementations for a variety of domains and scenarios, interactive documentation, and the ability to easily share implementations and outcomes. The library is available at https://github.com/huggingface/evaluate. In addition, we introduce Evaluation on the Hub, a platform that enables the large-scale evaluation of over 75,000 models and 11,000 datasets on the Hugging Face Hub, for free, at the click of a button. Evaluation on the Hub is available at https://huggingface.co/autoevaluate.
Bugs in the Data: How ImageNet Misrepresents Biodiversity
Aug 24, 2022
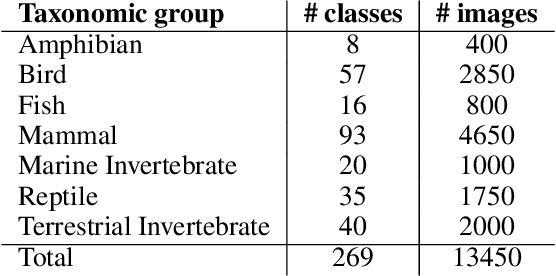
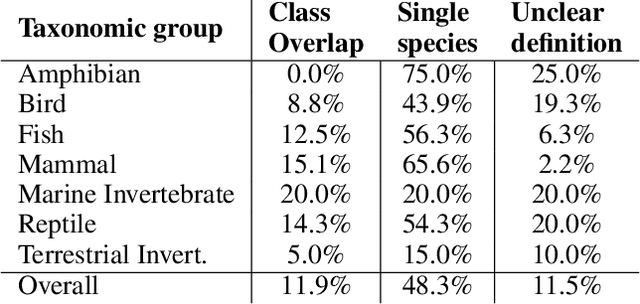
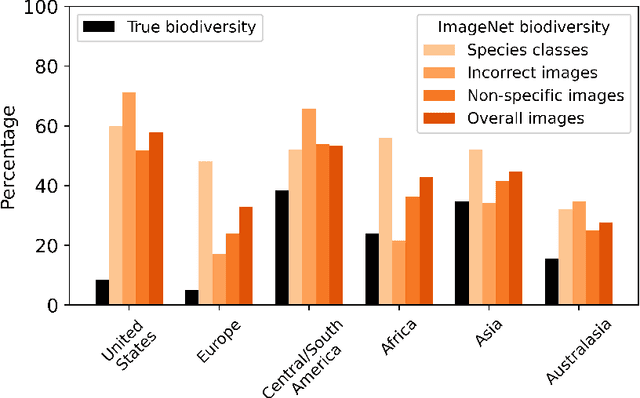
ImageNet-1k is a dataset often used for benchmarking machine learning (ML) models and evaluating tasks such as image recognition and object detection. Wild animals make up 27% of ImageNet-1k but, unlike classes representing people and objects, these data have not been closely scrutinized. In the current paper, we analyze the 13,450 images from 269 classes that represent wild animals in the ImageNet-1k validation set, with the participation of expert ecologists. We find that many of the classes are ill-defined or overlapping, and that 12% of the images are incorrectly labeled, with some classes having >90% of images incorrect. We also find that both the wildlife-related labels and images included in ImageNet-1k present significant geographical and cultural biases, as well as ambiguities such as artificial animals, multiple species in the same image, or the presence of humans. Our findings highlight serious issues with the extensive use of this dataset for evaluating ML systems, the use of such algorithms in wildlife-related tasks, and more broadly the ways in which ML datasets are commonly created and curated.
Measuring the Carbon Intensity of AI in Cloud Instances
Jun 10, 2022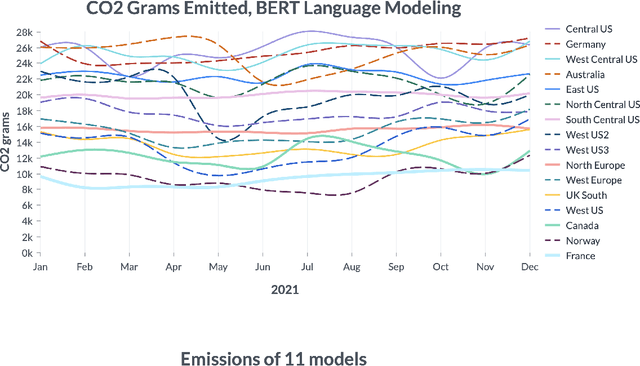

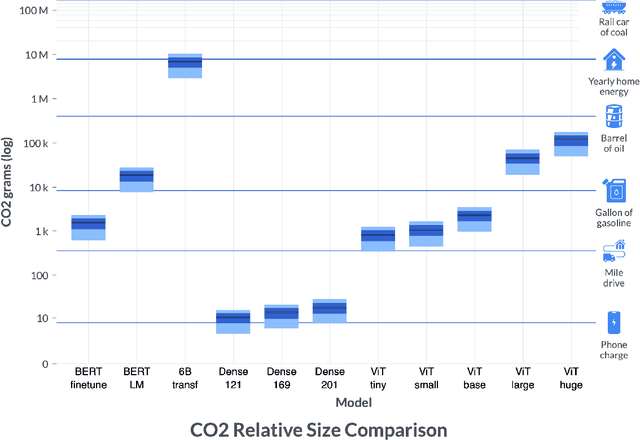

By providing unprecedented access to computational resources, cloud computing has enabled rapid growth in technologies such as machine learning, the computational demands of which incur a high energy cost and a commensurate carbon footprint. As a result, recent scholarship has called for better estimates of the greenhouse gas impact of AI: data scientists today do not have easy or reliable access to measurements of this information, precluding development of actionable tactics. Cloud providers presenting information about software carbon intensity to users is a fundamental stepping stone towards minimizing emissions. In this paper, we provide a framework for measuring software carbon intensity, and propose to measure operational carbon emissions by using location-based and time-specific marginal emissions data per energy unit. We provide measurements of operational software carbon intensity for a set of modern models for natural language processing and computer vision, and a wide range of model sizes, including pretraining of a 6.1 billion parameter language model. We then evaluate a suite of approaches for reducing emissions on the Microsoft Azure cloud compute platform: using cloud instances in different geographic regions, using cloud instances at different times of day, and dynamically pausing cloud instances when the marginal carbon intensity is above a certain threshold. We confirm previous results that the geographic region of the data center plays a significant role in the carbon intensity for a given cloud instance, and find that choosing an appropriate region can have the largest operational emissions reduction impact. We also show that the time of day has notable impact on operational software carbon intensity. Finally, we conclude with recommendations for how machine learning practitioners can use software carbon intensity information to reduce environmental impact.
Metaethical Perspectives on 'Benchmarking' AI Ethics
Apr 11, 2022Benchmarks are seen as the cornerstone for measuring technical progress in Artificial Intelligence (AI) research and have been developed for a variety of tasks ranging from question answering to facial recognition. An increasingly prominent research area in AI is ethics, which currently has no set of benchmarks nor commonly accepted way for measuring the 'ethicality' of an AI system. In this paper, drawing upon research in moral philosophy and metaethics, we argue that it is impossible to develop such a benchmark. As such, alternative mechanisms are necessary for evaluating whether an AI system is 'ethical'. This is especially pressing in light of the prevalence of applied, industrial AI research. We argue that it makes more sense to talk about 'values' (and 'value alignment') rather than 'ethics' when considering the possible actions of present and future AI systems. We further highlight that, because values are unambiguously relative, focusing on values forces us to consider explicitly what the values are and whose values they are. Shifting the emphasis from ethics to values therefore gives rise to several new ways of understanding how researchers might advance research programmes for robustly safe or beneficial AI. We conclude by highlighting a number of possible ways forward for the field as a whole, and we advocate for different approaches towards more value-aligned AI research.
The Problem of Zombie Datasets:A Framework For Deprecating Datasets
Oct 18, 2021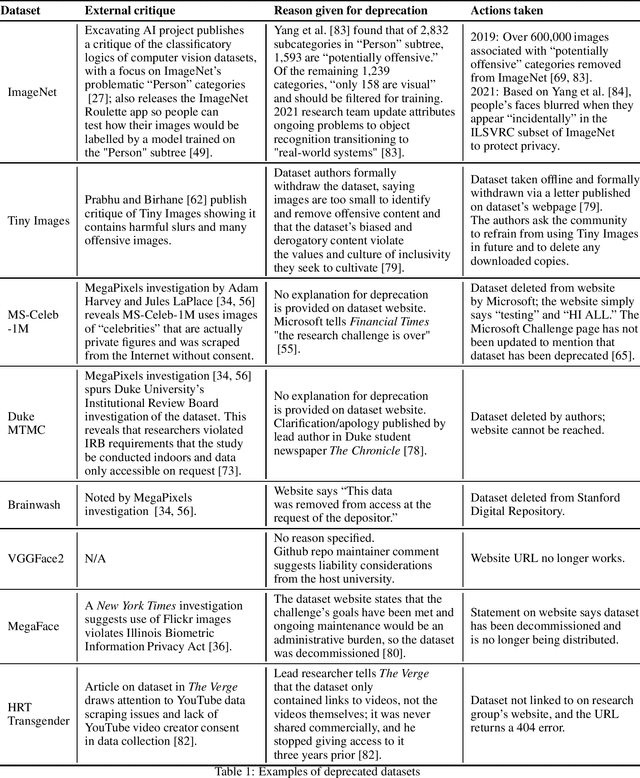
What happens when a machine learning dataset is deprecated for legal, ethical, or technical reasons, but continues to be widely used? In this paper, we examine the public afterlives of several prominent deprecated or redacted datasets, including ImageNet, 80 Million Tiny Images, MS-Celeb-1M, Duke MTMC, Brainwash, and HRT Transgender, in order to inform a framework for more consistent, ethical, and accountable dataset deprecation. Building on prior research, we find that there is a lack of consistency, transparency, and centralized sourcing of information on the deprecation of datasets, and as such, these datasets and their derivatives continue to be cited in papers and circulate online. These datasets that never die -- which we term "zombie datasets" -- continue to inform the design of production-level systems, causing technical, legal, and ethical challenges; in so doing, they risk perpetuating the harms that prompted their supposed withdrawal, including concerns around bias, discrimination, and privacy. Based on this analysis, we propose a Dataset Deprecation Framework that includes considerations of risk, mitigation of impact, appeal mechanisms, timeline, post-deprecation protocol, and publication checks that can be adapted and implemented by the machine learning community. Drawing on work on datasheets and checklists, we further offer two sample dataset deprecation sheets and propose a centralized repository that tracks which datasets have been deprecated and could be incorporated into the publication protocols of venues like NeurIPS.
ClimateGAN: Raising Climate Change Awareness by Generating Images of Floods
Oct 06, 2021
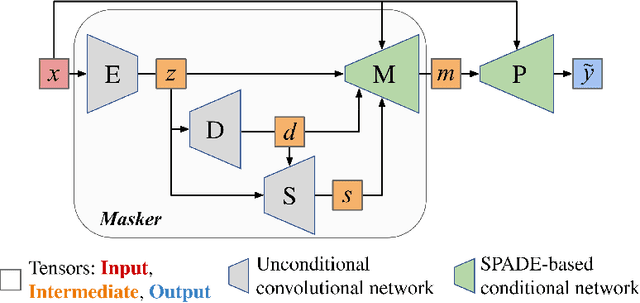

Climate change is a major threat to humanity, and the actions required to prevent its catastrophic consequences include changes in both policy-making and individual behaviour. However, taking action requires understanding the effects of climate change, even though they may seem abstract and distant. Projecting the potential consequences of extreme climate events such as flooding in familiar places can help make the abstract impacts of climate change more concrete and encourage action. As part of a larger initiative to build a website that projects extreme climate events onto user-chosen photos, we present our solution to simulate photo-realistic floods on authentic images. To address this complex task in the absence of suitable training data, we propose ClimateGAN, a model that leverages both simulated and real data for unsupervised domain adaptation and conditional image generation. In this paper, we describe the details of our framework, thoroughly evaluate components of our architecture and demonstrate that our model is capable of robustly generating photo-realistic flooding.
Ensuring the Inclusive Use of Natural Language Processing in the Global Response to COVID-19
Aug 11, 2021Natural language processing (NLP) plays a significant role in tools for the COVID-19 pandemic response, from detecting misinformation on social media to helping to provide accurate clinical information or summarizing scientific research. However, the approaches developed thus far have not benefited all populations, regions or languages equally. We discuss ways in which current and future NLP approaches can be made more inclusive by covering low-resource languages, including alternative modalities, leveraging out-of-the-box tools and forming meaningful partnerships. We suggest several future directions for researchers interested in maximizing the positive societal impacts of NLP.
What's in the Box? A Preliminary Analysis of Undesirable Content in the Common Crawl Corpus
May 31, 2021
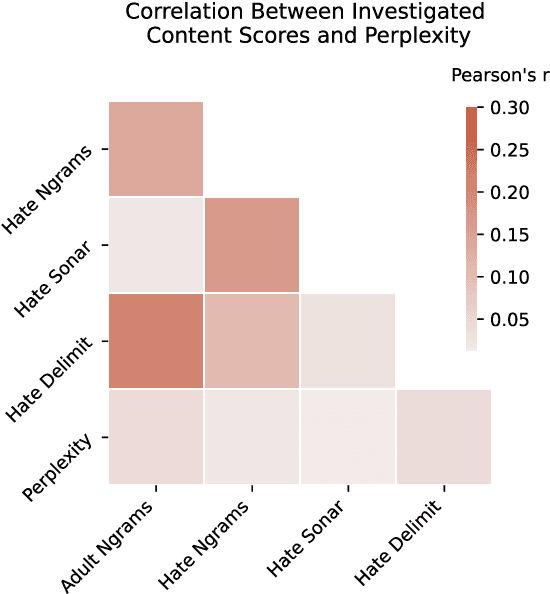

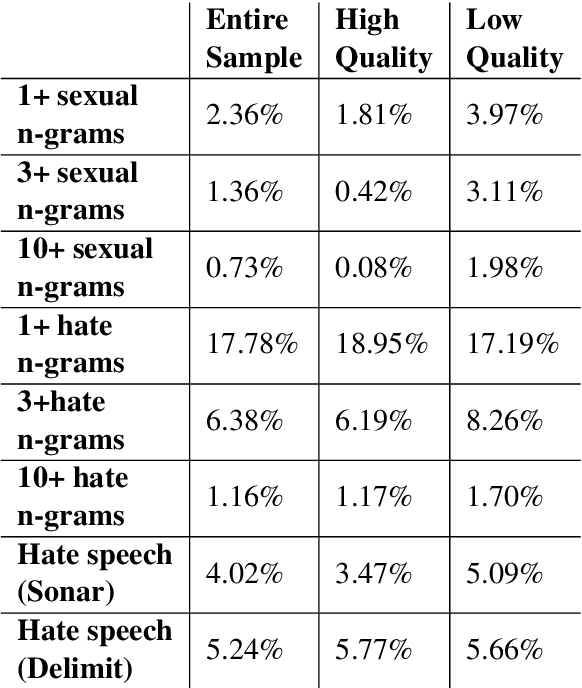
Whereas much of the success of the current generation of neural language models has been driven by increasingly large training corpora, relatively little research has been dedicated to analyzing these massive sources of textual data. In this exploratory analysis, we delve deeper into the Common Crawl, a colossal web corpus that is extensively used for training language models. We find that it contains a significant amount of undesirable content, including hate speech and sexually explicit content, even after filtering procedures. We discuss the potential impacts of this content on language models and conclude with future research directions and a more mindful approach to corpus collection and analysis.