 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformational Space of Meaning for Scientific Texts
Apr 28, 2020In Natural Language Processing, automatic extracting the meaning of texts constitutes an important problem. Our focus is the computational analysis of meaning of short scientific texts (abstracts or brief reports). In this paper, a vector space model is developed for quantifying the meaning of words and texts. We introduce the Meaning Space, in which the meaning of a word is represented by a vector of Relative Information Gain (RIG) about the subject categories that the text belongs to, which can be obtained from observing the word in the text. This new approach is applied to construct the Meaning Space based on Leicester Scientific Corpus (LSC) and Leicester Scientific Dictionary-Core (LScDC). The LSC is a scientific corpus of 1,673,350 abstracts and the LScDC is a scientific dictionary which words are extracted from the LSC. Each text in the LSC belongs to at least one of 252 subject categories of Web of Science (WoS). These categories are used in construction of vectors of information gains. The Meaning Space is described and statistically analysed for the LSC with the LScDC. The usefulness of the proposed representation model is evaluated through top-ranked words in each category. The most informative n words are ordered. We demonstrated that RIG-based word ranking is much more useful than ranking based on raw word frequency in determining the science-specific meaning and importance of a word. The proposed model based on RIG is shown to have ability to stand out topic-specific words in categories. The most informative words are presented for 252 categories. The new scientific dictionary and the 103,998 x 252 Word-Category RIG Matrix are available online. Analysis of the Meaning Space provides us with a tool to further explore quantifying the meaning of a text using more complex and context-dependent meaning models that use co-occurrence of words and their combinations.
On Adversarial Examples and Stealth Attacks in Artificial Intelligence Systems
Apr 09, 2020In this work we present a formal theoretical framework for assessing and analyzing two classes of malevolent action towards generic Artificial Intelligence (AI) systems. Our results apply to general multi-class classifiers that map from an input space into a decision space, including artificial neural networks used in deep learning applications. Two classes of attacks are considered. The first class involves adversarial examples and concerns the introduction of small perturbations of the input data that cause misclassification. The second class, introduced here for the first time and named stealth attacks, involves small perturbations to the AI system itself. Here the perturbed system produces whatever output is desired by the attacker on a specific small data set, perhaps even a single input, but performs as normal on a validation set (which is unknown to the attacker). We show that in both cases, i.e., in the case of an attack based on adversarial examples and in the case of a stealth attack, the dimensionality of the AI's decision-making space is a major contributor to the AI's susceptibility. For attacks based on adversarial examples, a second crucial parameter is the absence of local concentrations in the data probability distribution, a property known as Smeared Absolute Continuity. According to our findings, robustness to adversarial examples requires either (a) the data distributions in the AI's feature space to have concentrated probability density functions or (b) the dimensionality of the AI's decision variables to be sufficiently small. We also show how to construct stealth attacks on high-dimensional AI systems that are hard to spot unless the validation set is made exponentially large.
High--Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality
Jan 14, 2020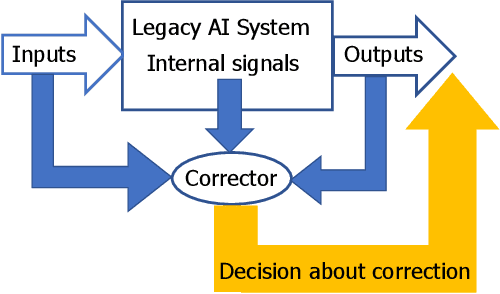

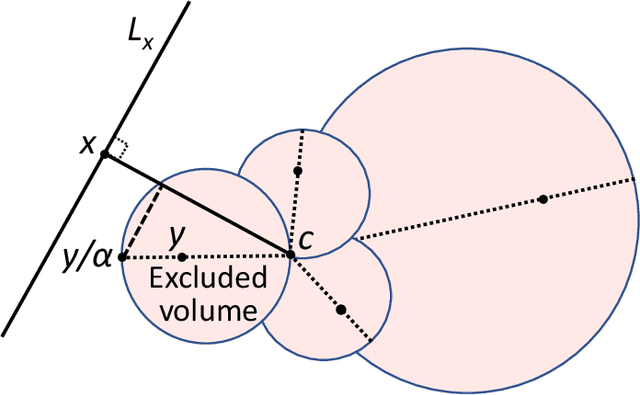
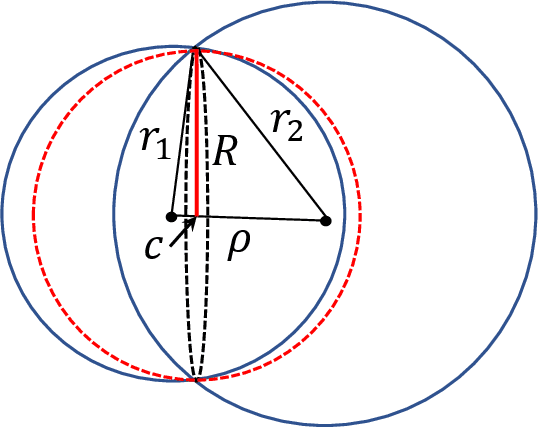
High-dimensional data and high-dimensional representations of reality are inherent features of modern Artificial Intelligence systems and applications of machine learning. The well-known phenomenon of the "curse of dimensionality" states: many problems become exponentially difficult in high dimensions. Recently, the other side of the coin, the "blessing of dimensionality", has attracted much attention. It turns out that generic high-dimensional datasets exhibit fairly simple geometric properties. Thus, there is a fundamental tradeoff between complexity and simplicity in high dimensional spaces. Here we present a brief explanatory review of recent ideas, results and hypotheses about the blessing of dimensionality and related simplifying effects relevant to machine learning and neuroscience.
LScDC-new large scientific dictionary
Dec 14, 2019
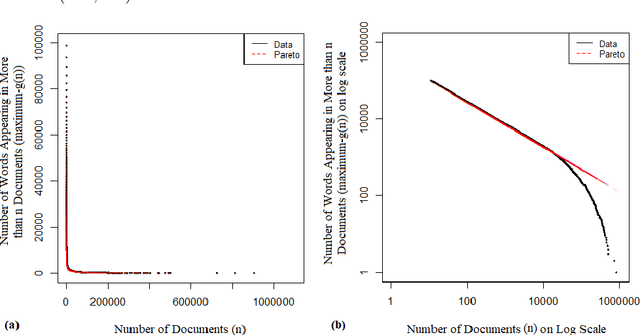
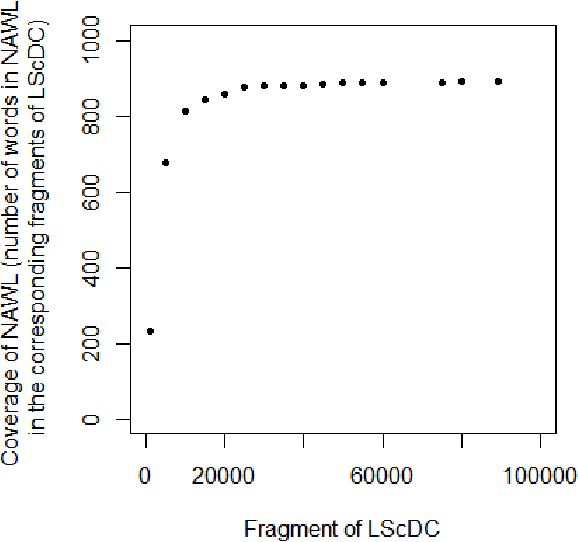
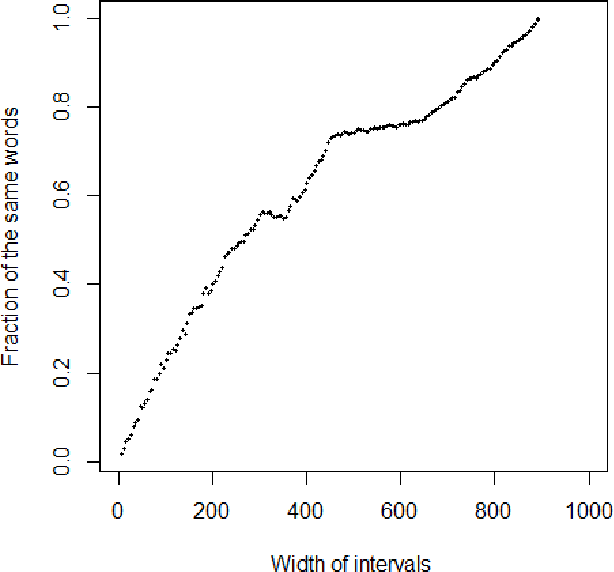
In this paper, we present a scientific corpus of abstracts of academic papers in English -- Leicester Scientific Corpus (LSC). The LSC contains 1,673,824 abstracts of research articles and proceeding papers indexed by Web of Science (WoS) in which publication year is 2014. Each abstract is assigned to at least one of 252 subject categories. Paper metadata include these categories and the number of citations. We then develop scientific dictionaries named Leicester Scientific Dictionary (LScD) and Leicester Scientific Dictionary-Core (LScDC), where words are extracted from the LSC. The LScD is a list of 974,238 unique words (lemmas). The LScDC is a core list (sub-list) of the LScD with 104,223 lemmas. It was created by removing LScD words appearing in not greater than 10 texts in the LSC. LScD and LScDC are available online. Both the corpus and dictionaries are developed to be later used for quantification of meaning in academic texts. Finally, the core list LScDC was analysed by comparing its words and word frequencies with a classic academic word list 'New Academic Word List (NAWL)' containing 963 word families, which is also sampled from an academic corpus. The major sources of the corpus where NAWL is extracted are Cambridge English Corpus (CEC), oral sources and textbooks. We investigate whether two dictionaries are similar in terms of common words and ranking of words. Our comparison leads us to main conclusion: most of words of NAWL (99.6%) are present in the LScDC but two lists differ in word ranking. This difference is measured.
Blessing of dimensionality at the edge
Sep 30, 2019
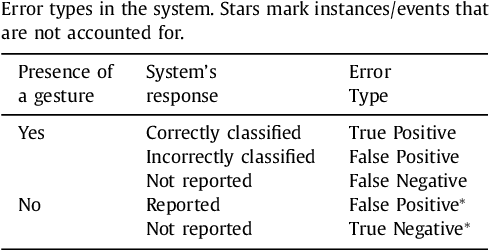
In this paper we present theory and algorithms enabling classes of Artificial Intelligence (AI) systems to continuously and incrementally improve with a-priori quantifiable guarantees - or more specifically remove classification errors - over time. This is distinct from state-of-the-art machine learning, AI, and software approaches. Another feature of this approach is that, in the supervised setting, the computational complexity of training is linear in the number of training samples. At the time of classification, the computational complexity is bounded by few inner product calculations. Moreover, the implementation is shown to be very scalable. This makes it viable for deployment in applications where computational power and memory are limited, such as embedded environments. It enables the possibility for fast on-line optimisation using improved training samples. The approach is based on the concentration of measure effects and stochastic separation theorems.
Symphony of high-dimensional brain
Jun 27, 2019This paper is the final part of the scientific discussion organised by the Journal "Physics of Life Rviews" about the simplicity revolution in neuroscience and AI. This discussion was initiated by the review paper "The unreasonable effectiveness of small neural ensembles in high-dimensional brain". Phys Life Rev 2019, doi 10.1016/j.plrev.2018.09.005, arXiv:1809.07656. The topics of the discussion varied from the necessity to take into account the difference between the theoretical random distributions and "extremely non-random" real distributions and revise the common machine learning theory, to different forms of the curse of dimensionality and high-dimensional pitfalls in neuroscience. V. K{\r{u}}rkov{\'a}, A. Tozzi and J.F. Peters, R. Quian Quiroga, P. Varona, R. Barrio, G. Kreiman, L. Fortuna, C. van Leeuwen, R. Quian Quiroga, and V. Kreinovich, A.N. Gorban, V.A. Makarov, and I.Y. Tyukin participated in the discussion. In this paper we analyse the symphony of opinions and the possible outcomes of the simplicity revolution for machine learning and neuroscience.
Fast Construction of Correcting Ensembles for Legacy Artificial Intelligence Systems: Algorithms and a Case Study
Oct 12, 2018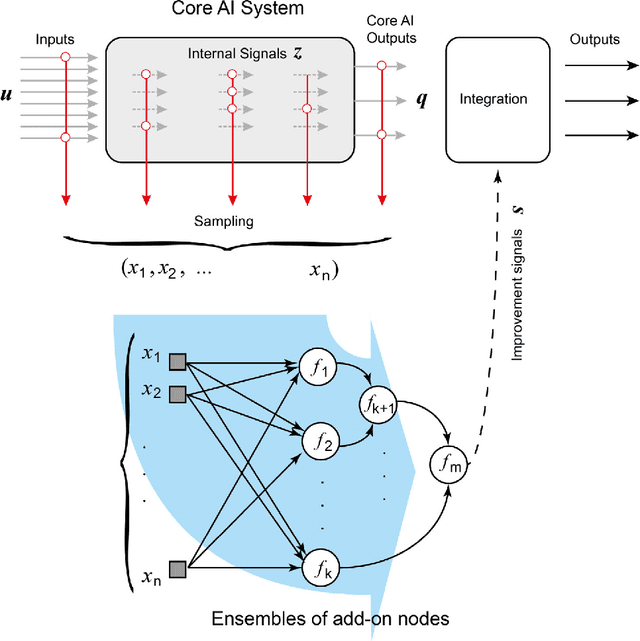
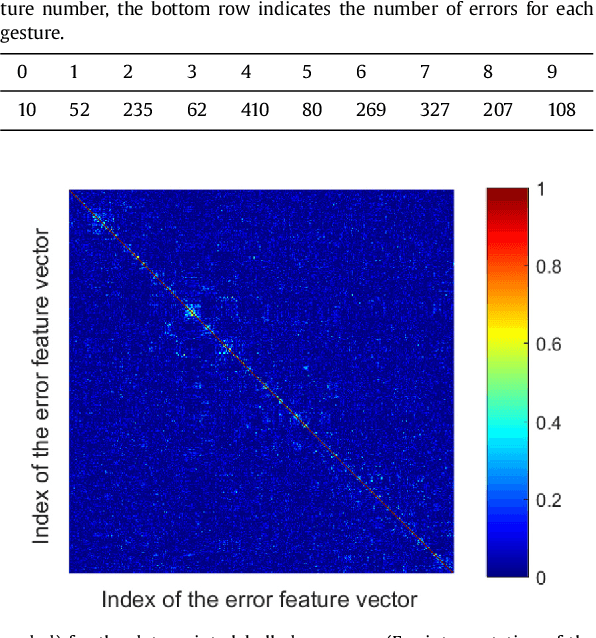
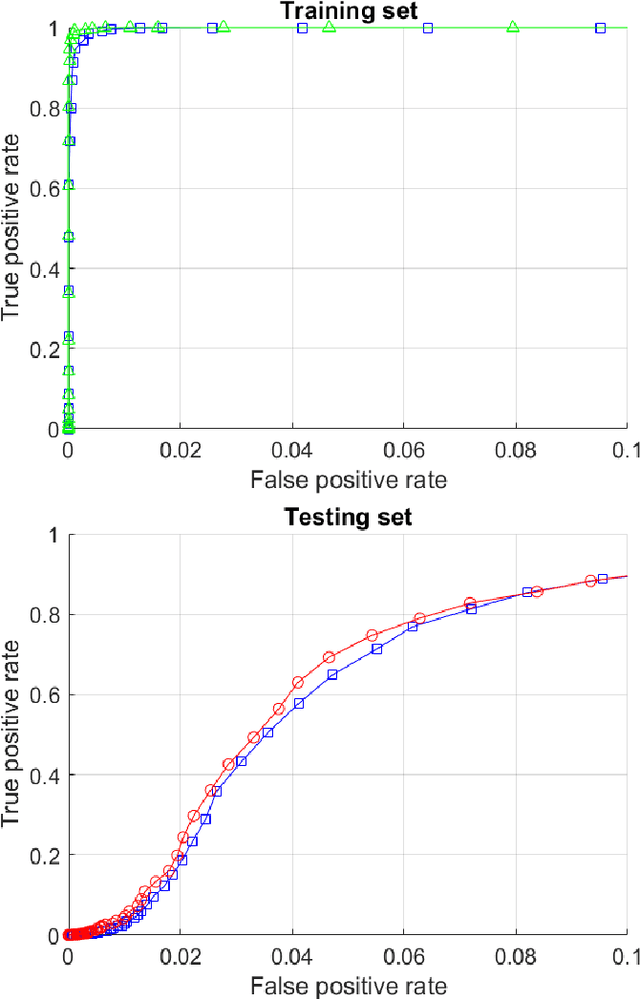
This paper presents a technology for simple and computationally efficient improvements of a generic Artificial Intelligence (AI) system, including Multilayer and Deep Learning neural networks. The improvements are, in essence, small network ensembles constructed on top of the existing AI architectures. Theoretical foundations of the technology are based on Stochastic Separation Theorems and the ideas of the concentration of measure. We show that, subject to mild technical assumptions on statistical properties of internal signals in the original AI system, the technology enables instantaneous and computationally efficient removal of spurious and systematic errors with probability close to one on the datasets which are exponentially large in dimension. The method is illustrated with numerical examples and a case study of ten digits recognition from American Sign Language.
Robust And Scalable Learning Of Complex Dataset Topologies Via Elpigraph
Jun 20, 2018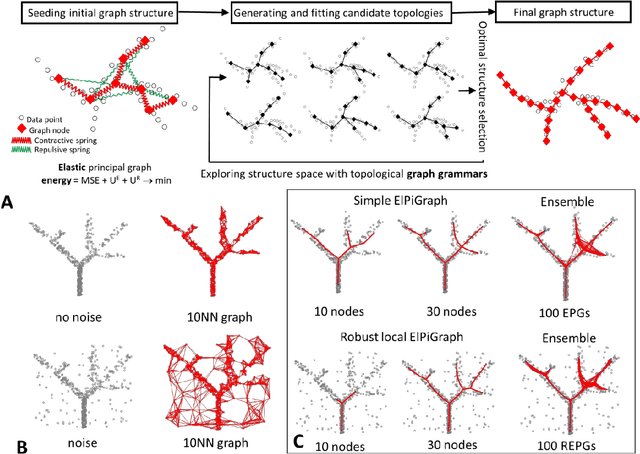
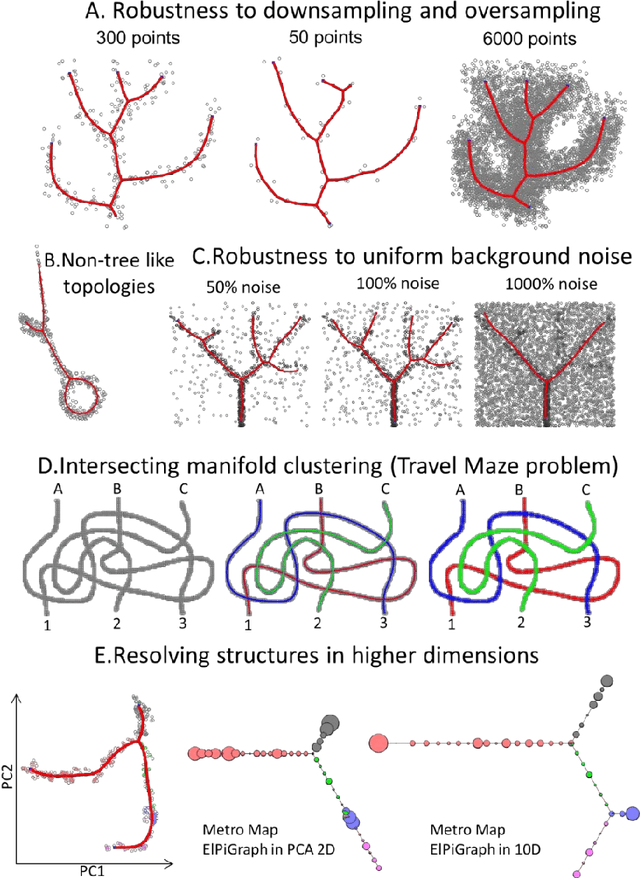

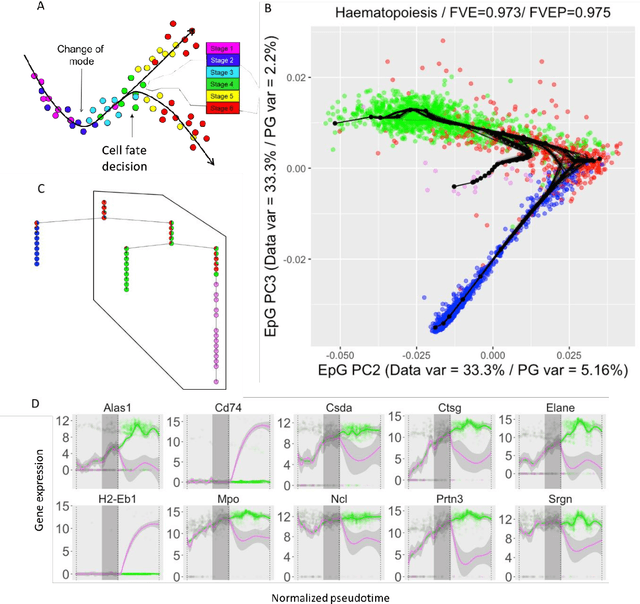
Large datasets represented by multidimensional data point clouds often possess non-trivial distributions with branching trajectories and excluded regions, with the recent single-cell transcriptomic studies of developing embryo being notable examples. Reducing the complexity and producing compact and interpretable representations of such data remains a challenging task. Most of the existing computational methods are based on exploring the local data point neighbourhood relations, a step that can perform poorly in the case of multidimensional and noisy data. Here we present ElPiGraph, a scalable and robust method for approximation of datasets with complex structures which does not require computing the complete data distance matrix or the data point neighbourhood graph. This method is able to withstand high levels of noise and is capable of approximating complex topologies via principal graph ensembles that can be combined into a consensus principal graph. ElPiGraph deals efficiently with large and complex datasets in various fields from biology, where it can be used to infer gene dynamics from single-cell RNA-Seq, to astronomy, where it can be used to explore complex structures in the distribution of galaxies.
Augmented Artificial Intelligence: a Conceptual Framework
Mar 24, 2018
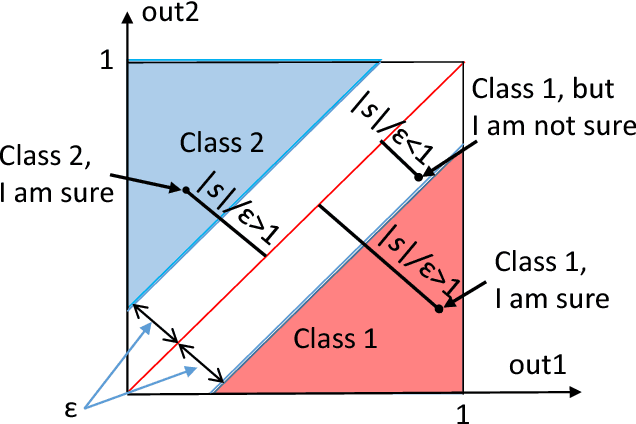
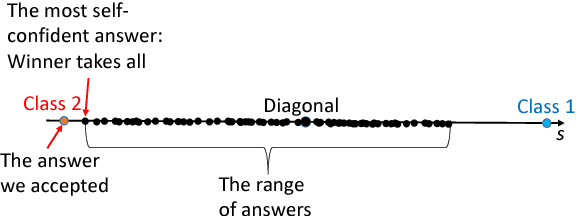
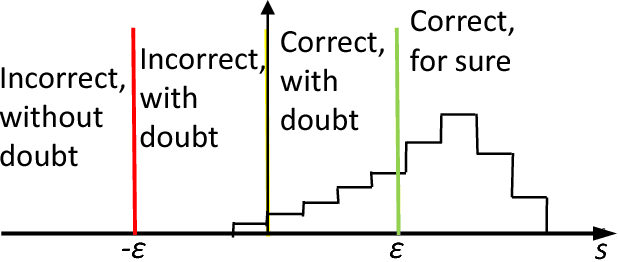
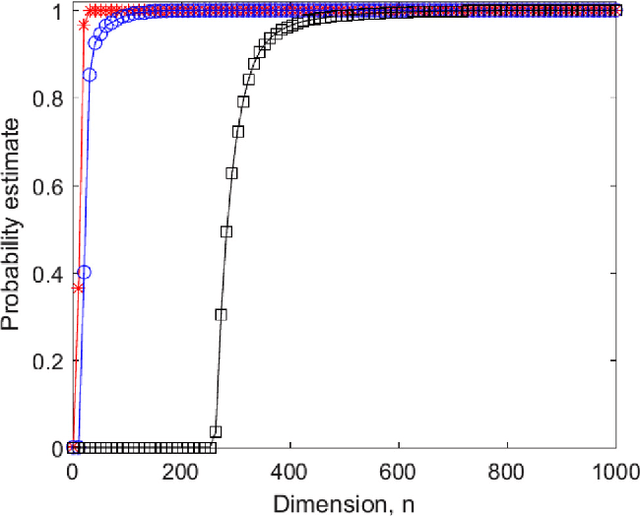
All artificial Intelligence (AI) systems make errors. These errors are unexpected, and differ often from the typical human mistakes ("non-human" errors). The AI errors should be corrected without damage of existing skills and, hopefully, avoiding direct human expertise. This paper presents an initial summary report of project taking new and systematic approach to improving the intellectual effectiveness of the individual AI by communities of AIs. We combine some ideas of learning in heterogeneous multiagent systems with new and original mathematical approaches for non-iterative corrections of errors of legacy AI systems. The mathematical foundations of AI non-destructive correction are presented and a series of new stochastic separation theorems is proven. These theorems provide a new instrument for the development, analysis, and assessment of machine learning methods and algorithms in high dimension. They demonstrate that in high dimensions and even for exponentially large samples, linear classifiers in their classical Fisher's form are powerful enough to separate errors from correct responses with high probability and to provide efficient solution to the non-destructive corrector problem. In particular, we prove some hypotheses formulated in our paper `Stochastic Separation Theorems' (Neural Networks, 94, 255--259, 2017), and answer one general problem published by Donoho and Tanner in 2009.
Multivariate Gaussian and Student$-t$ Process Regression for Multi-output Prediction
Jan 18, 2018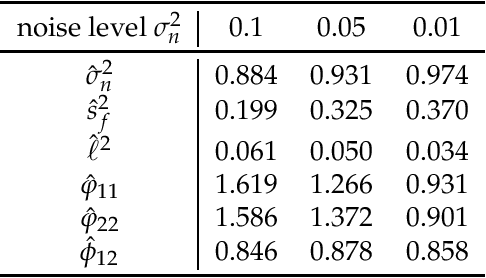
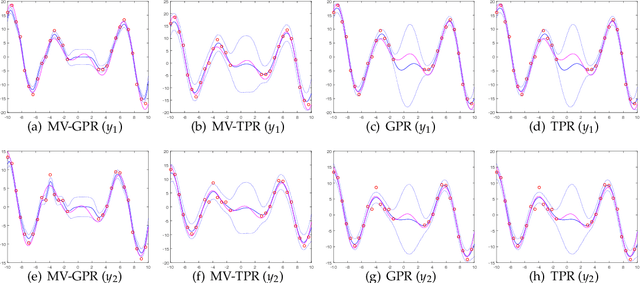
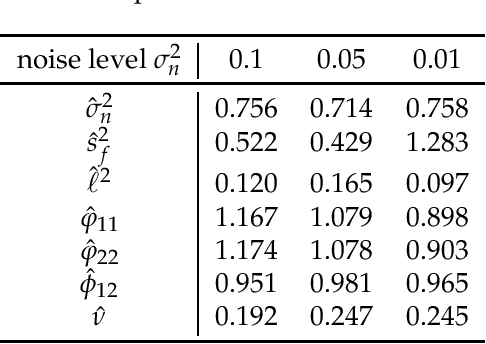
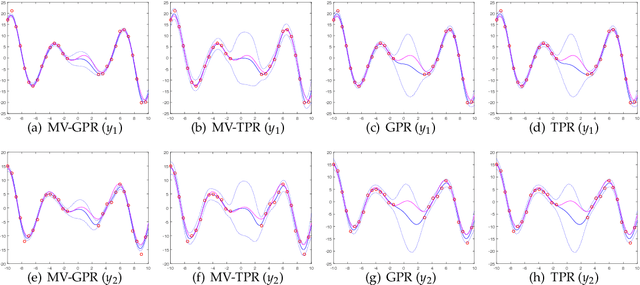
Gaussian process for vector-valued function model has been shown to be a useful method for multi-output prediction. The existing method for this model is to re-formulate the matrix-variate Gaussian distribution as a multivariate normal distribution. Although it is effective in many cases, re-formulation is not always workable and difficult to extend because not all matrix-variate distributions can be transformed to related multivariate distributions, such as the case for matrix-variate Student$-t$ distribution. In this paper, we propose a new derivation of multivariate Gaussian process regression (MV-GPR), where the model settings, derivations and computations are all directly performed in matrix form, rather than vectorizing the matrices as done in the existing methods. Furthermore, we introduce the multivariate Student$-t$ process and then derive a new method, multivariate Student$-t$ process regression (MV-TPR) for multi-output prediction. Both MV-GPR and MV-TPR have closed-form expressions for the marginal likelihoods and predictive distributions. The usefulness of the proposed methods is illustrated through several simulated examples. In particular, we verify empirically that MV-TPR has superiority for the datasets considered, including air quality prediction and bike rent prediction. At last, the proposed methods are shown to produce profitable investment strategies in the stock markets.