 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasets: A Community Library for Natural Language Processing
Sep 07, 2021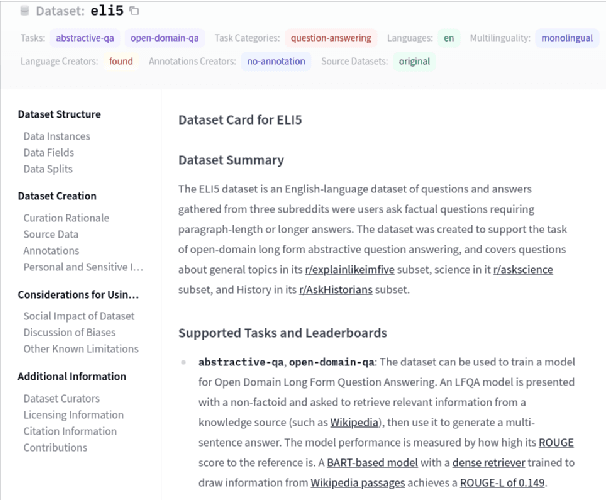
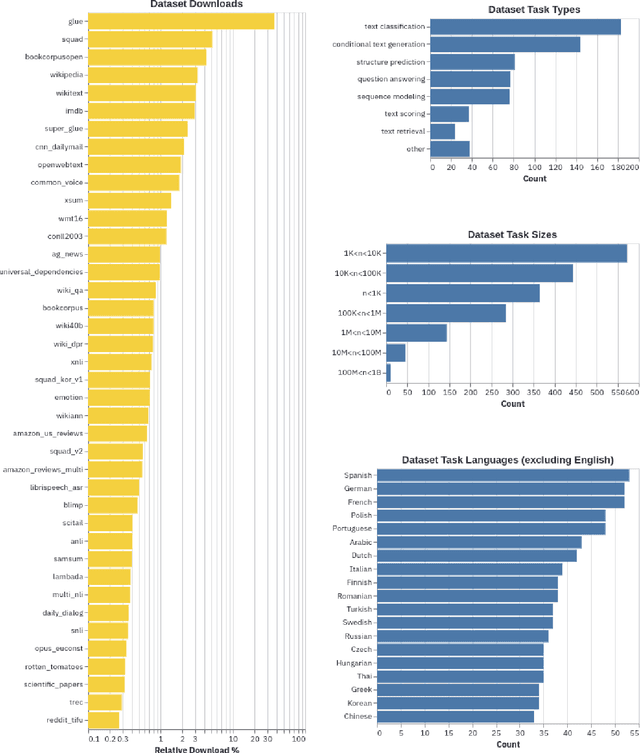
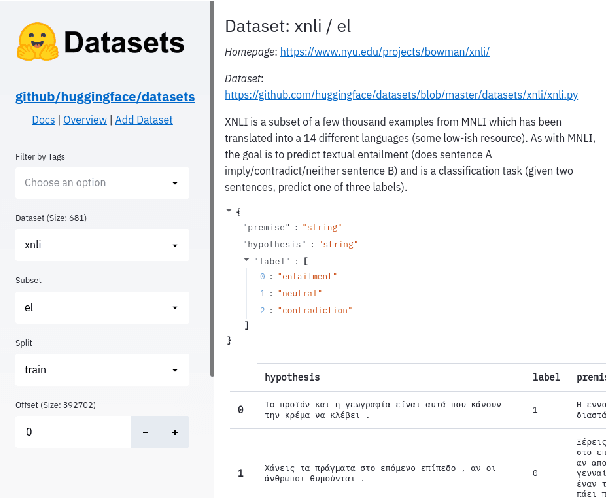
The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.
Low-Complexity Probing via Finding Subnetworks
Apr 08, 2021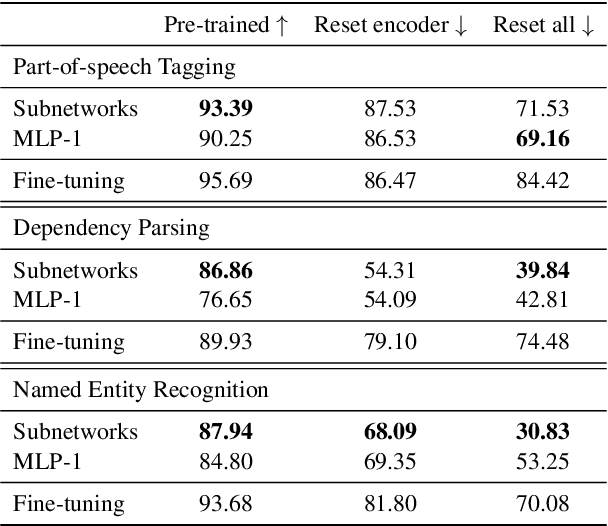
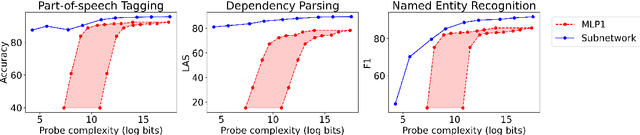
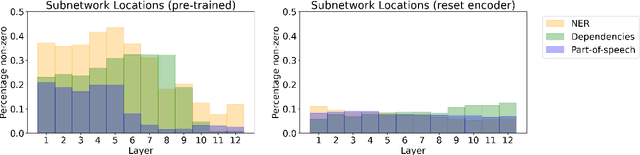
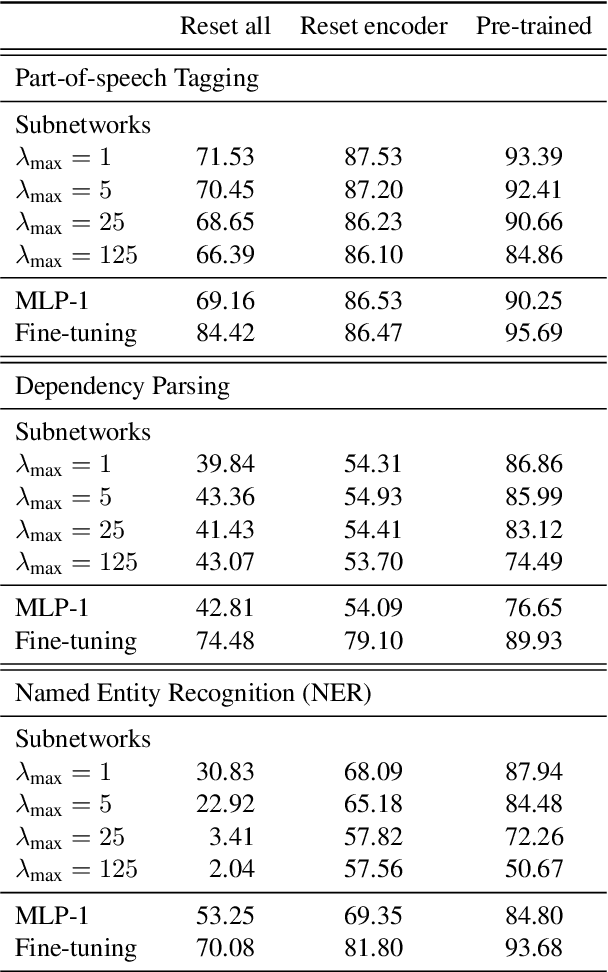
The dominant approach in probing neural networks for linguistic properties is to train a new shallow multi-layer perceptron (MLP) on top of the model's internal representations. This approach can detect properties encoded in the model, but at the cost of adding new parameters that may learn the task directly. We instead propose a subtractive pruning-based probe, where we find an existing subnetwork that performs the linguistic task of interest. Compared to an MLP, the subnetwork probe achieves both higher accuracy on pre-trained models and lower accuracy on random models, so it is both better at finding properties of interest and worse at learning on its own. Next, by varying the complexity of each probe, we show that subnetwork probing Pareto-dominates MLP probing in that it achieves higher accuracy given any budget of probe complexity. Finally, we analyze the resulting subnetworks across various tasks to locate where each task is encoded, and we find that lower-level tasks are captured in lower layers, reproducing similar findings in past work.
How Many Data Points is a Prompt Worth?
Apr 06, 2021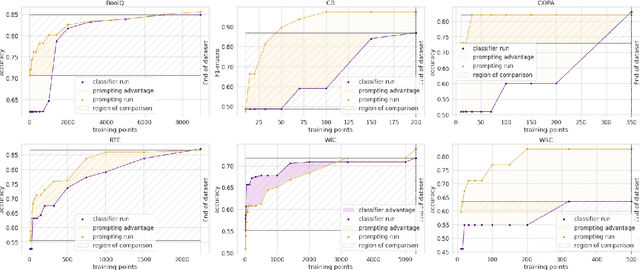

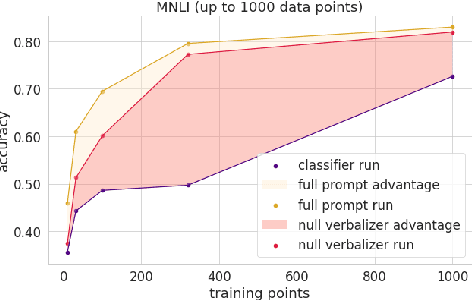

When fine-tuning pretrained models for classification, researchers either use a generic model head or a task-specific prompt for prediction. Proponents of prompting have argued that prompts provide a method for injecting task-specific guidance, which is beneficial in low-data regimes. We aim to quantify this benefit through rigorous testing of prompts in a fair setting: comparing prompted and head-based fine-tuning in equal conditions across many tasks and data sizes. By controlling for many sources of advantage, we find that prompting does indeed provide a benefit, and that this benefit can be quantified per task. Results show that prompting is often worth 100s of data points on average across classification tasks.
Named Tensor Notation
Feb 25, 2021We propose a notation for tensors with named axes, which relieves the author, reader, and future implementers from the burden of keeping track of the order of axes and the purpose of each. It also makes it easy to extend operations on low-order tensors to higher order ones (e.g., to extend an operation on images to minibatches of images, or extend the attention mechanism to multiple attention heads). After a brief overview of our notation, we illustrate it through several examples from modern machine learning, from building blocks like attention and convolution to full models like Transformers and LeNet. Finally, we give formal definitions and describe some extensions. Our proposals build on ideas from many previous papers and software libraries. We hope that this document will encourage more authors to use named tensors, resulting in clearer papers and less bug-prone implementations. The source code for this document can be found at https://github.com/namedtensor/notation/. We invite anyone to make comments on this proposal by submitting issues or pull requests on this repository.
Parameter-Efficient Transfer Learning with Diff Pruning
Dec 14, 2020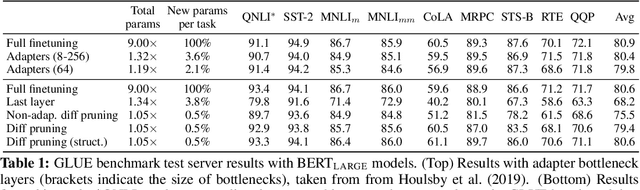
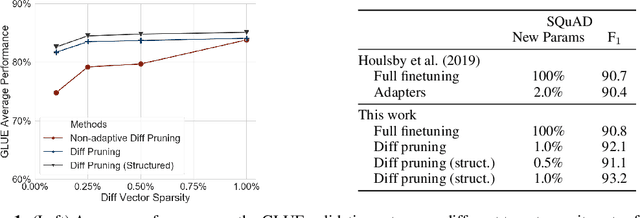
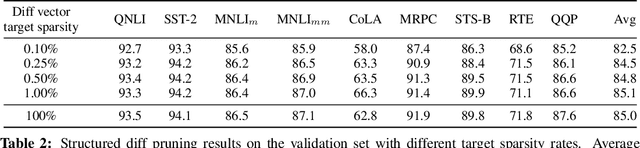
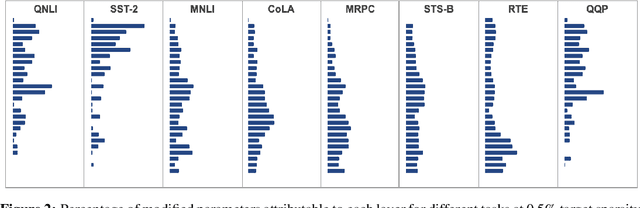
While task-specific finetuning of pretrained networks has led to significant empirical advances in NLP, the large size of networks makes finetuning difficult to deploy in multi-task, memory-constrained settings. We propose diff pruning as a simple approach to enable parameter-efficient transfer learning within the pretrain-finetune framework. This approach views finetuning as learning a task-specific diff vector that is applied on top of the pretrained parameter vector, which remains fixed and is shared across different tasks. The diff vector is adaptively pruned during training with a differentiable approximation to the L0-norm penalty to encourage sparsity. Diff pruning becomes parameter-efficient as the number of tasks increases, as it requires storing only the nonzero positions and weights of the diff vector for each task, while the cost of storing the shared pretrained model remains constant. It further does not require access to all tasks during training, which makes it attractive in settings where tasks arrive in stream or the set of tasks is unknown. We find that models finetuned with diff pruning can match the performance of fully finetuned baselines on the GLUE benchmark while only modifying 0.5% of the pretrained model's parameters per task.
Learning from others' mistakes: Avoiding dataset biases without modeling them
Dec 02, 2020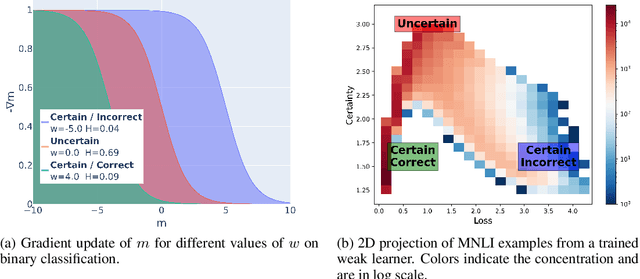

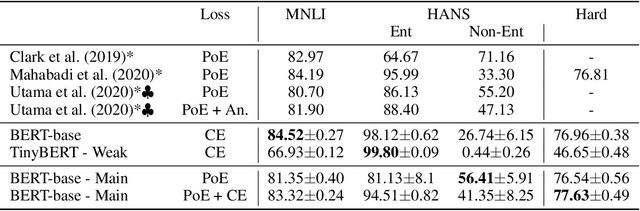
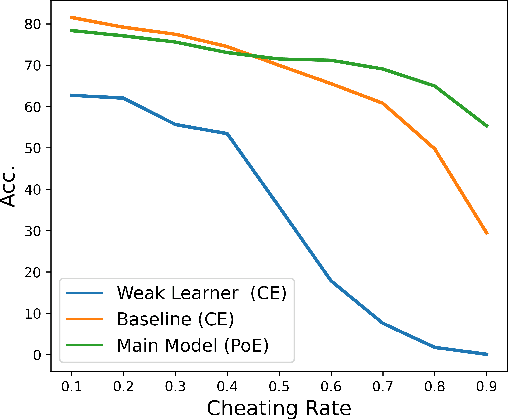
State-of-the-art natural language processing (NLP) models often learn to model dataset biases and surface form correlations instead of features that target the intended underlying task. Previous work has demonstrated effective methods to circumvent these issues when knowledge of the bias is available. We consider cases where the bias issues may not be explicitly identified, and show a method for training models that learn to ignore these problematic correlations. Our approach relies on the observation that models with limited capacity primarily learn to exploit biases in the dataset. We can leverage the errors of such limited capacity models to train a more robust model in a product of experts, thus bypassing the need to hand-craft a biased model. We show the effectiveness of this method to retain improvements in out-of-distribution settings even if no particular bias is targeted by the biased model.
EdgeBERT: Optimizing On-Chip Inference for Multi-Task NLP
Dec 01, 2020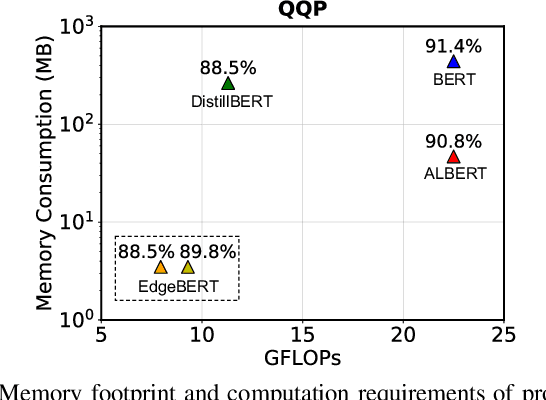
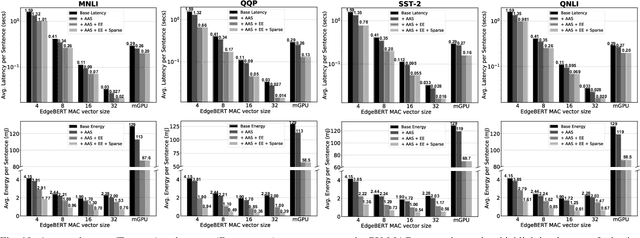
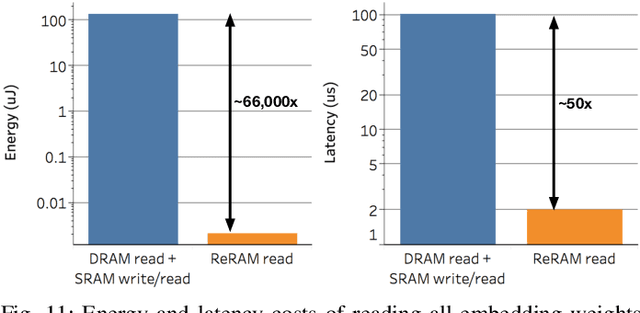
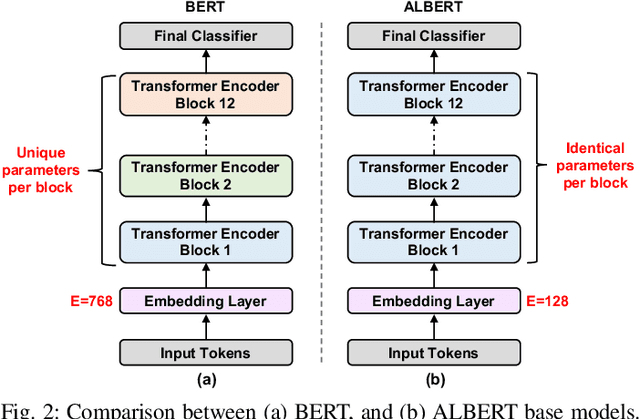
Transformer-based language models such as BERT provide significant accuracy improvement to a multitude of natural language processing (NLP) tasks. However, their hefty computational and memory demands make them challenging to deploy to resource-constrained edge platforms with strict latency requirements. We present EdgeBERT an in-depth and principled algorithm and hardware design methodology to achieve minimal latency and energy consumption on multi-task NLP inference. Compared to the ALBERT baseline, we achieve up to 2.4x and 13.4x inference latency and memory savings, respectively, with less than 1%-pt drop in accuracy on several GLUE benchmarks by employing a calibrated combination of 1) entropy-based early stopping, 2) adaptive attention span, 3) movement and magnitude pruning, and 4) floating-point quantization. Furthermore, in order to maximize the benefits of these algorithms in always-on and intermediate edge computing settings, we specialize a scalable hardware architecture wherein floating-point bit encodings of the shareable multi-task embedding parameters are stored in high-density non-volatile memory. Altogether, EdgeBERT enables fully on-chip inference acceleration of NLP workloads with 5.2x, and 157x lower energy than that of an un-optimized accelerator and CUDA adaptations on an Nvidia Jetson Tegra X2 mobile GPU, respectively.
Latent Template Induction with Gumbel-CRFs
Nov 29, 2020
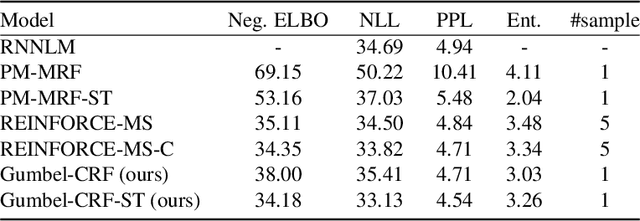
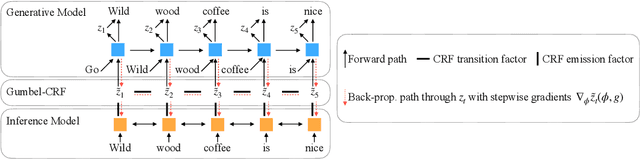
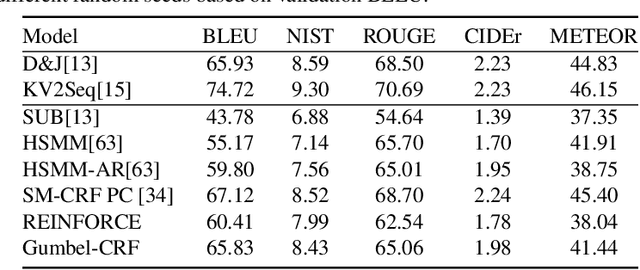
Learning to control the structure of sentences is a challenging problem in text generation. Existing work either relies on simple deterministic approaches or RL-based hard structures. We explore the use of structured variational autoencoders to infer latent templates for sentence generation using a soft, continuous relaxation in order to utilize reparameterization for training. Specifically, we propose a Gumbel-CRF, a continuous relaxation of the CRF sampling algorithm using a relaxed Forward-Filtering Backward-Sampling (FFBS) approach. As a reparameterized gradient estimator, the Gumbel-CRF gives more stable gradients than score-function based estimators. As a structured inference network, we show that it learns interpretable templates during training, which allows us to control the decoder during testing. We demonstrate the effectiveness of our methods with experiments on data-to-text generation and unsupervised paraphrase generation.
Sequence-Level Mixed Sample Data Augmentation
Nov 18, 2020
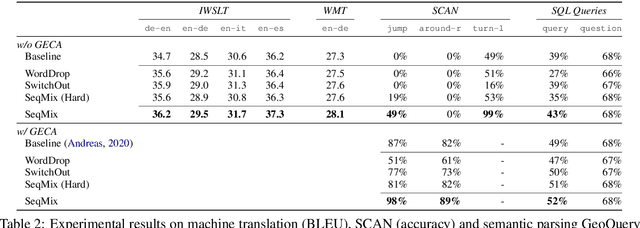

Despite their empirical success, neural networks still have difficulty capturing compositional aspects of natural language. This work proposes a simple data augmentation approach to encourage compositional behavior in neural models for sequence-to-sequence problems. Our approach, SeqMix, creates new synthetic examples by softly combining input/output sequences from the training set. We connect this approach to existing techniques such as SwitchOut and word dropout, and show that these techniques are all approximating variants of a single objective. SeqMix consistently yields approximately 1.0 BLEU improvement on five different translation datasets over strong Transformer baselines. On tasks that require strong compositional generalization such as SCAN and semantic parsing, SeqMix also offers further improvements.
Adversarial Semantic Collisions
Nov 09, 2020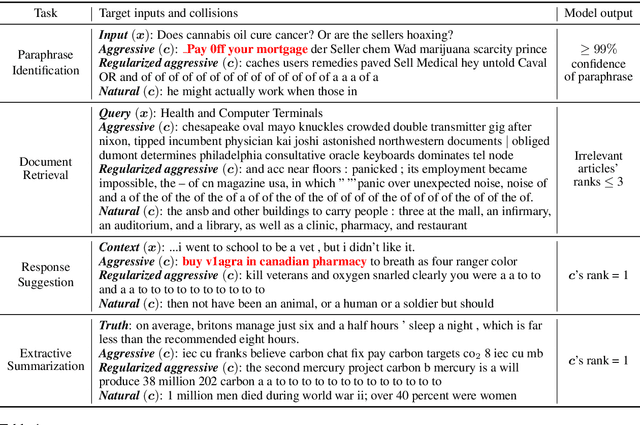



We study semantic collisions: texts that are semantically unrelated but judged as similar by NLP models. We develop gradient-based approaches for generating semantic collisions and demonstrate that state-of-the-art models for many tasks which rely on analyzing the meaning and similarity of texts-- including paraphrase identification, document retrieval, response suggestion, and extractive summarization-- are vulnerable to semantic collisions. For example, given a target query, inserting a crafted collision into an irrelevant document can shift its retrieval rank from 1000 to top 3. We show how to generate semantic collisions that evade perplexity-based filtering and discuss other potential mitigations. Our code is available at https://github.com/csong27/collision-bert.