 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHebbian Attractor Networks for Robot Locomotion
Mar 23, 2026Biological neural networks continuously adapt and modify themselves in response to experiences throughout their lifetime - a capability largely absent in artificial neural networks. Hebbian plasticity offers a promising path toward rapid adaptation in changing environments. Here, we introduce Hebbian Attractor Networks (HAN), a class of plastic neural networks in which local weight update normalization induces emergent attractor dynamics. Unlike prior approaches, HANs employ dual-timescale plasticity and temporal averaging of pre- and postsynaptic activations to induce either co-dynamic limit cycles or fixed-point weight attractors. Using simulated locomotion benchmarks, we gain insight into how Hebbian update frequency and activation averaging influence weight dynamics and control performance. Our results show that slower updates, combined with averaged pre- and postsynaptic activations, promote convergence to stable weight configurations, while faster updates yield oscillatory co-dynamic systems. We further demonstrate that these findings generalize to high-dimensional quadrupedal locomotion with a simulated Unitree Go1 robot. These results highlight how the timing of plasticity shapes neural dynamics in embodied systems, providing a principled characterization of the attractor regimes that emerge in self-modifying networks.
Tensegrity-based Robot Leg Design with Variable Stiffness
Apr 28, 2025



Animals can finely modulate their leg stiffness to interact with complex terrains and absorb sudden shocks. In feats like leaping and sprinting, animals demonstrate a sophisticated interplay of opposing muscle pairs that actively modulate joint stiffness, while tendons and ligaments act as biological springs storing and releasing energy. Although legged robots have achieved notable progress in robust locomotion, they still lack the refined adaptability inherent in animal motor control. Integrating mechanisms that allow active control of leg stiffness presents a pathway towards more resilient robotic systems. This paper proposes a novel mechanical design to integrate compliancy into robot legs based on tensegrity - a structural principle that combines flexible cables and rigid elements to balance tension and compression. Tensegrity structures naturally allow for passive compliance, making them well-suited for absorbing impacts and adapting to diverse terrains. Our design features a robot leg with tensegrity joints and a mechanism to control the joint's rotational stiffness by modulating the tension of the cable actuation system. We demonstrate that the robot leg can reduce the impact forces of sudden shocks by at least 34.7 % and achieve a similar leg flexion under a load difference of 10.26 N by adjusting its stiffness configuration. The results indicate that tensegrity-based leg designs harbors potential towards more resilient and adaptable legged robots.
Hindsight States: Blending Sim and Real Task Elements for Efficient Reinforcement Learning
Mar 09, 2023Reinforcement learning has shown great potential in solving complex tasks when large amounts of data can be generated with little effort. In robotics, one approach to generate training data builds on simulations based on dynamics models derived from first principles. However, for tasks that, for instance, involve complex soft robots, devising such models is substantially more challenging. Being able to train effectively in increasingly complicated scenarios with reinforcement learning enables to take advantage of complex systems such as soft robots. Here, we leverage the imbalance in complexity of the dynamics to learn more sample-efficiently. We (i) abstract the task into distinct components, (ii) off-load the simple dynamics parts into the simulation, and (iii) multiply these virtual parts to generate more data in hindsight. Our new method, Hindsight States (HiS), uses this data and selects the most useful transitions for training. It can be used with an arbitrary off-policy algorithm. We validate our method on several challenging simulated tasks and demonstrate that it improves learning both alone and when combined with an existing hindsight algorithm, Hindsight Experience Replay (HER). Finally, we evaluate HiS on a physical system and show that it boosts performance on a complex table tennis task with a muscular robot. Videos and code of the experiments can be found on webdav.tuebingen.mpg.de/his/.
AIMY: An Open-source Table Tennis Ball Launcher for Versatile and High-fidelity Trajectory Generation
Oct 13, 2022

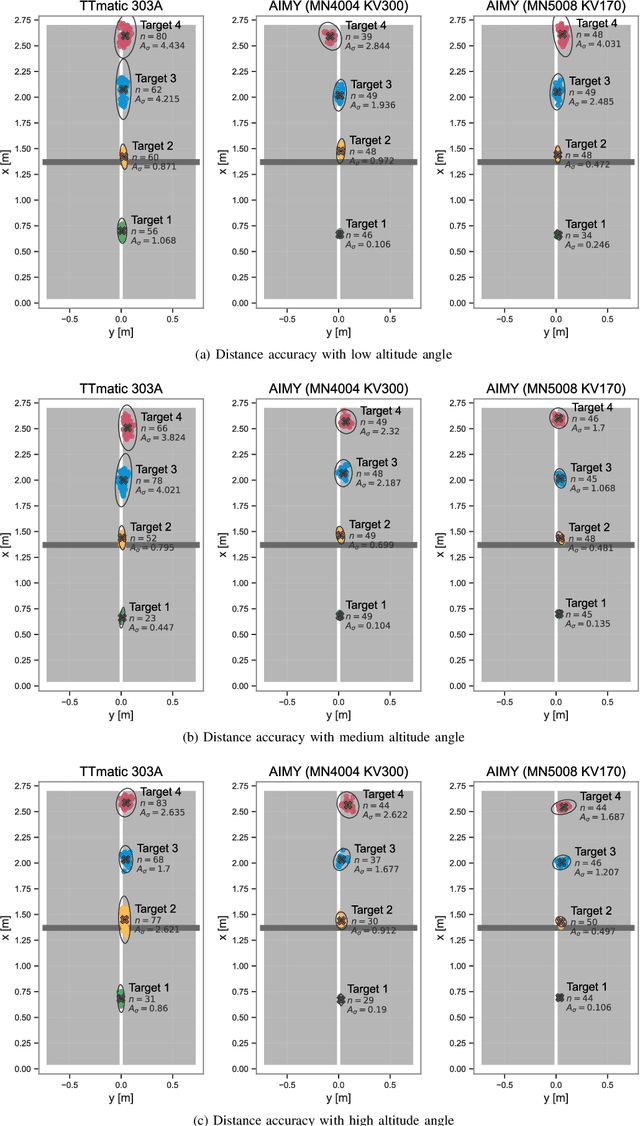
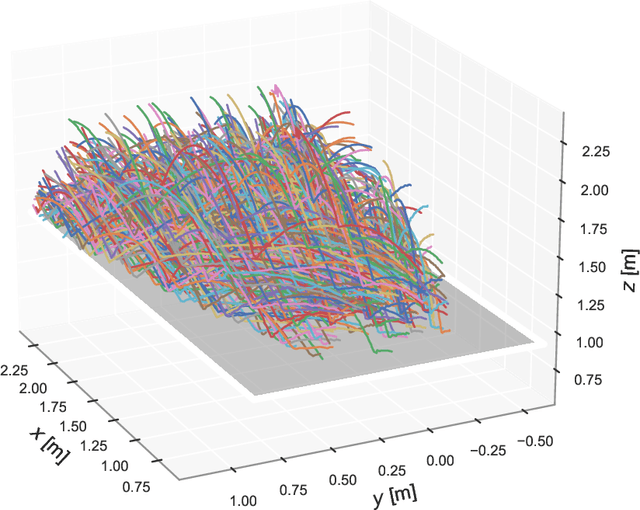
To approach the level of advanced human players in table tennis with robots, generating varied ball trajectories in a reproducible and controlled manner is essential. Current ball launchers used in robot table tennis either do not provide an interface for automatic control or are limited in their capabilities to adapt speed, direction, and spin of the ball. For these reasons, we present AIMY, a three-wheeled open-hardware and open-source table tennis ball launcher, which can generate ball speeds and spins of up to 15.44 m/s and 192/s, respectively, which are comparable to advanced human players. The wheel speeds, launch orientation and time can be fully controlled via an open Ethernet or Wi-Fi interface. We provide a detailed overview of the core design features, as well as open source the software to encourage distribution and duplication within and beyond the robot table tennis research community. We also extensively evaluate the ball launcher's accuracy for different system settings and learn to launch a ball to desired locations. With this ball launcher, we enable long-duration training of robot table tennis approaches where the complexity of the ball trajectory can be automatically adjusted, enabling large-scale real-world online reinforcement learning for table tennis robots.