 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIME: Localized Image Editing via Attention Regularization in Diffusion Models
Dec 14, 2023



Diffusion models (DMs) have gained prominence due to their ability to generate high-quality, varied images, with recent advancements in text-to-image generation. The research focus is now shifting towards the controllability of DMs. A significant challenge within this domain is localized editing, where specific areas of an image are modified without affecting the rest of the content. This paper introduces LIME for localized image editing in diffusion models that do not require user-specified regions of interest (RoI) or additional text input. Our method employs features from pre-trained methods and a simple clustering technique to obtain precise semantic segmentation maps. Then, by leveraging cross-attention maps, it refines these segments for localized edits. Finally, we propose a novel cross-attention regularization technique that penalizes unrelated cross-attention scores in the RoI during the denoising steps, ensuring localized edits. Our approach, without re-training and fine-tuning, consistently improves the performance of existing methods in various editing benchmarks.
TouchSDF: A DeepSDF Approach for 3D Shape Reconstruction using Vision-Based Tactile Sensing
Nov 21, 2023



Humans rely on their visual and tactile senses to develop a comprehensive 3D understanding of their physical environment. Recently, there has been a growing interest in exploring and manipulating objects using data-driven approaches that utilise high-resolution vision-based tactile sensors. However, 3D shape reconstruction using tactile sensing has lagged behind visual shape reconstruction because of limitations in existing techniques, including the inability to generalise over unseen shapes, the absence of real-world testing, and limited expressive capacity imposed by discrete representations. To address these challenges, we propose TouchSDF, a Deep Learning approach for tactile 3D shape reconstruction that leverages the rich information provided by a vision-based tactile sensor and the expressivity of the implicit neural representation DeepSDF. Our technique consists of two components: (1) a Convolutional Neural Network that maps tactile images into local meshes representing the surface at the touch location, and (2) an implicit neural function that predicts a signed distance function to extract the desired 3D shape. This combination allows TouchSDF to reconstruct smooth and continuous 3D shapes from tactile inputs in simulation and real-world settings, opening up research avenues for robust 3D-aware representations and improved multimodal perception in robotics. Code and supplementary material are available at: https://touchsdf.github.io/
TextMesh: Generation of Realistic 3D Meshes From Text Prompts
Apr 24, 2023



The ability to generate highly realistic 2D images from mere text prompts has recently made huge progress in terms of speed and quality, thanks to the advent of image diffusion models. Naturally, the question arises if this can be also achieved in the generation of 3D content from such text prompts. To this end, a new line of methods recently emerged trying to harness diffusion models, trained on 2D images, for supervision of 3D model generation using view dependent prompts. While achieving impressive results, these methods, however, have two major drawbacks. First, rather than commonly used 3D meshes, they instead generate neural radiance fields (NeRFs), making them impractical for most real applications. Second, these approaches tend to produce over-saturated models, giving the output a cartoonish looking effect. Therefore, in this work we propose a novel method for generation of highly realistic-looking 3D meshes. To this end, we extend NeRF to employ an SDF backbone, leading to improved 3D mesh extraction. In addition, we propose a novel way to finetune the mesh texture, removing the effect of high saturation and improving the details of the output 3D mesh.
NeRF-Supervised Deep Stereo
Mar 30, 2023We introduce a novel framework for training deep stereo networks effortlessly and without any ground-truth. By leveraging state-of-the-art neural rendering solutions, we generate stereo training data from image sequences collected with a single handheld camera. On top of them, a NeRF-supervised training procedure is carried out, from which we exploit rendered stereo triplets to compensate for occlusions and depth maps as proxy labels. This results in stereo networks capable of predicting sharp and detailed disparity maps. Experimental results show that models trained under this regime yield a 30-40% improvement over existing self-supervised methods on the challenging Middlebury dataset, filling the gap to supervised models and, most times, outperforming them at zero-shot generalization.
NeRF-GAN Distillation for Efficient 3D-Aware Generation with Convolutions
Mar 22, 2023Pose-conditioned convolutional generative models struggle with high-quality 3D-consistent image generation from single-view datasets, due to their lack of sufficient 3D priors. Recently, the integration of Neural Radiance Fields (NeRFs) and generative models, such as Generative Adversarial Networks (GANs), has transformed 3D-aware generation from single-view images. NeRF-GANs exploit the strong inductive bias of 3D neural representations and volumetric rendering at the cost of higher computational complexity. This study aims at revisiting pose-conditioned 2D GANs for efficient 3D-aware generation at inference time by distilling 3D knowledge from pretrained NeRF-GANS. We propose a simple and effective method, based on re-using the well-disentangled latent space of a pre-trained NeRF-GAN in a pose-conditioned convolutional network to directly generate 3D-consistent images corresponding to the underlying 3D representations. Experiments on several datasets demonstrate that the proposed method obtains results comparable with volumetric rendering in terms of quality and 3D consistency while benefiting from the superior computational advantage of convolutional networks. The code will be available at: https://github.com/mshahbazi72/NeRF-GAN-Distillation
Learning Good Features to Transfer Across Tasks and Domains
Jan 26, 2023



Availability of labelled data is the major obstacle to the deployment of deep learning algorithms for computer vision tasks in new domains. The fact that many frameworks adopted to solve different tasks share the same architecture suggests that there should be a way of reusing the knowledge learned in a specific setting to solve novel tasks with limited or no additional supervision. In this work, we first show that such knowledge can be shared across tasks by learning a mapping between task-specific deep features in a given domain. Then, we show that this mapping function, implemented by a neural network, is able to generalize to novel unseen domains. Besides, we propose a set of strategies to constrain the learned feature spaces, to ease learning and increase the generalization capability of the mapping network, thereby considerably improving the final performance of our framework. Our proposal obtains compelling results in challenging synthetic-to-real adaptation scenarios by transferring knowledge between monocular depth estimation and semantic segmentation tasks.
LatentSwap3D: Semantic Edits on 3D Image GANs
Dec 02, 2022Recent 3D-aware GANs rely on volumetric rendering techniques to disentangle the pose and appearance of objects, de facto generating entire 3D volumes rather than single-view 2D images from a latent code. Complex image editing tasks can be performed in standard 2D-based GANs (e.g., StyleGAN models) as manipulation of latent dimensions. However, to the best of our knowledge, similar properties have only been partially explored for 3D-aware GAN models. This work aims to fill this gap by showing the limitations of existing methods and proposing LatentSwap3D, a model-agnostic approach designed to enable attribute editing in the latent space of pre-trained 3D-aware GANs. We first identify the most relevant dimensions in the latent space of the model controlling the targeted attribute by relying on the feature importance ranking of a random forest classifier. Then, to apply the transformation, we swap the top-K most relevant latent dimensions of the image being edited with an image exhibiting the desired attribute. Despite its simplicity, LatentSwap3D provides remarkable semantic edits in a disentangled manner and outperforms alternative approaches both qualitatively and quantitatively. We demonstrate our semantic edit approach on various 3D-aware generative models such as pi-GAN, GIRAFFE, StyleSDF, MVCGAN, EG3D and VolumeGAN, and on diverse datasets, such as FFHQ, AFHQ, Cats, MetFaces, and CompCars. The project page can be found: \url{https://enisimsar.github.io/latentswap3d/}.
ParGAN: Learning Real Parametrizable Transformations
Nov 09, 2022Current methods for image-to-image translation produce compelling results, however, the applied transformation is difficult to control, since existing mechanisms are often limited and non-intuitive. We propose ParGAN, a generalization of the cycle-consistent GAN framework to learn image transformations with simple and intuitive controls. The proposed generator takes as input both an image and a parametrization of the transformation. We train this network to preserve the content of the input image while ensuring that the result is consistent with the given parametrization. Our approach does not require paired data and can learn transformations across several tasks and datasets. We show how, with disjoint image domains with no annotated parametrization, our framework can create smooth interpolations as well as learn multiple transformations simultaneously.
LegoFormer: Transformers for Block-by-Block Multi-view 3D Reconstruction
Jun 23, 2021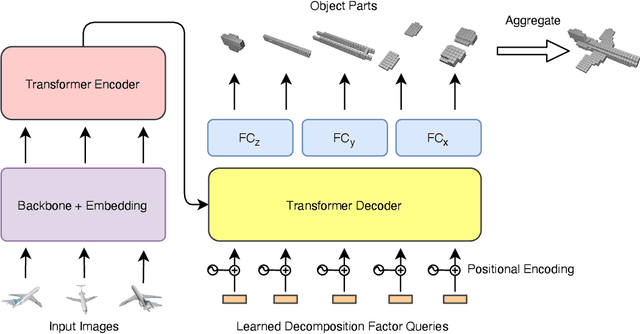
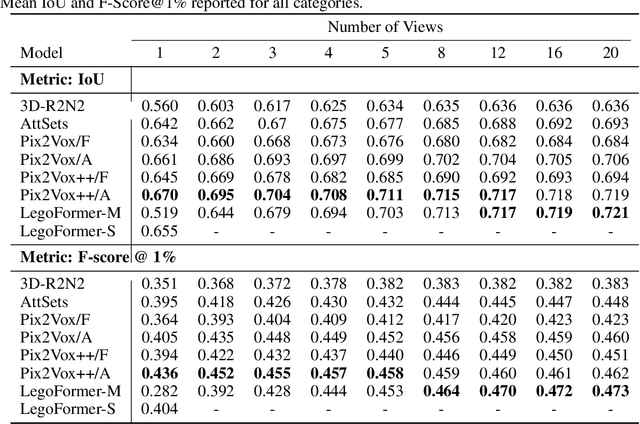
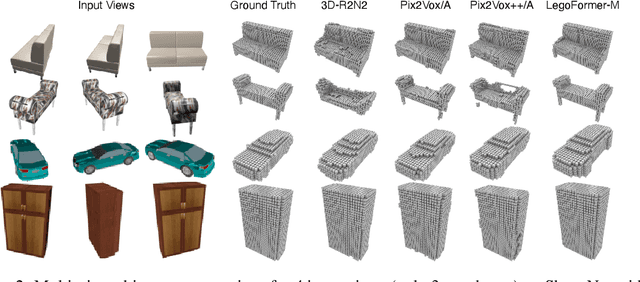
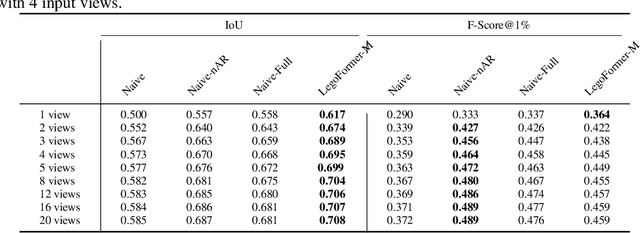
Most modern deep learning-based multi-view 3D reconstruction techniques use RNNs or fusion modules to combine information from multiple images after encoding them. These two separate steps have loose connections and do not consider all available information while encoding each view. We propose LegoFormer, a transformer-based model that unifies object reconstruction under a single framework and parametrizes the reconstructed occupancy grid by its decomposition factors. This reformulation allows the prediction of an object as a set of independent structures then aggregated to obtain the final reconstruction. Experiments conducted on ShapeNet display the competitive performance of our network with respect to the state-of-the-art methods. We also demonstrate how the use of self-attention leads to increased interpretability of the model output.
Unsupervised Novel View Synthesis from a Single Image
Feb 05, 2021

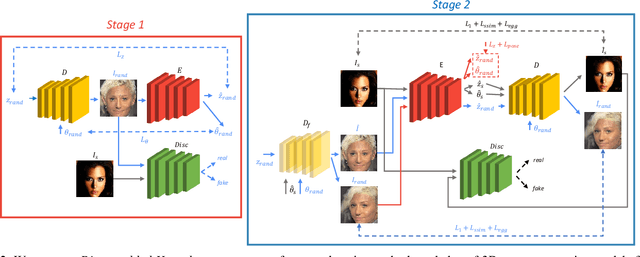
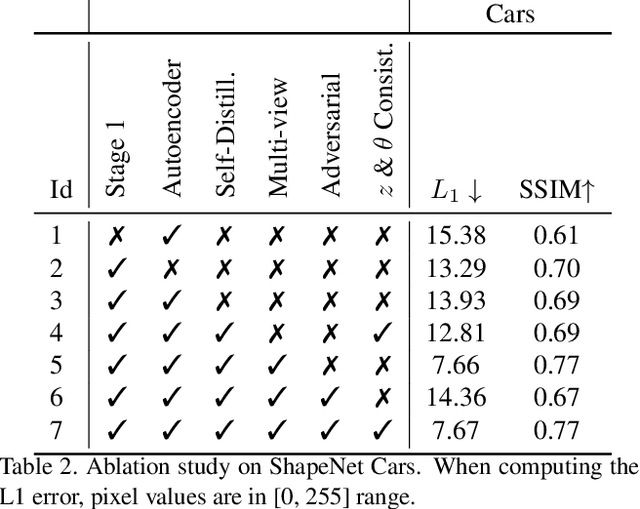
Novel view synthesis from a single image aims at generating novel views from a single input image of an object. Several works recently achieved remarkable results, though require some form of multi-view supervision at training time, therefore limiting their deployment in real scenarios. This work aims at relaxing this assumption enabling training of conditional generative model for novel view synthesis in a completely unsupervised manner. We first pre-train a purely generative decoder model using a GAN formulation while at the same time training an encoder network to invert the mapping from latent code to images. Then we swap encoder and decoder and train the network as a conditioned GAN with a mixture of auto-encoder-like objective and self-distillation. At test time, given a view of an object, our model first embeds the image content in a latent code and regresses its pose w.r.t. a canonical reference system, then generates novel views of it by keeping the code and varying the pose. We show that our framework achieves results comparable to the state of the art on ShapeNet and that it can be employed on unconstrained collections of natural images, where no competing method can be trained.