 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Accurate Estimation of Linear Models
Jul 29, 2017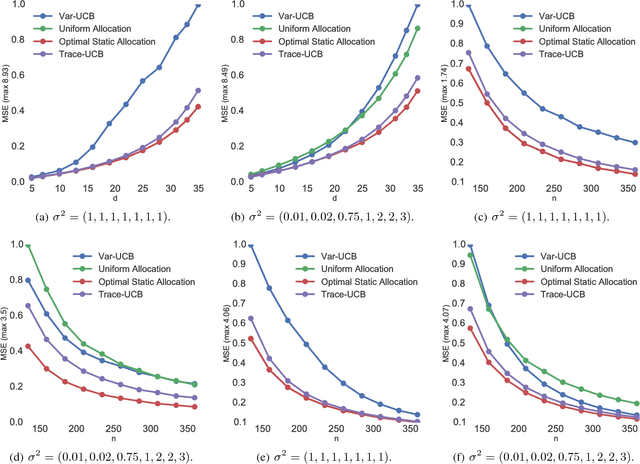
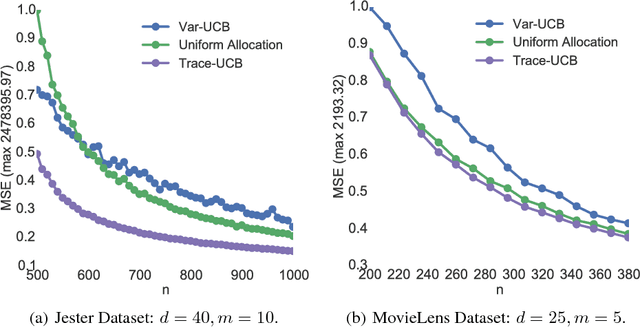
We explore the sequential decision making problem where the goal is to estimate uniformly well a number of linear models, given a shared budget of random contexts independently sampled from a known distribution. The decision maker must query one of the linear models for each incoming context, and receives an observation corrupted by noise levels that are unknown, and depend on the model instance. We present Trace-UCB, an adaptive allocation algorithm that learns the noise levels while balancing contexts accordingly across the different linear functions, and derive guarantees for simple regret in both expectation and high-probability. Finally, we extend the algorithm and its guarantees to high dimensional settings, where the number of linear models times the dimension of the contextual space is higher than the total budget of samples. Simulations with real data suggest that Trace-UCB is remarkably robust, outperforming a number of baselines even when its assumptions are violated.
Second-Order Kernel Online Convex Optimization with Adaptive Sketching
Jun 15, 2017Kernel online convex optimization (KOCO) is a framework combining the expressiveness of non-parametric kernel models with the regret guarantees of online learning. First-order KOCO methods such as functional gradient descent require only $\mathcal{O}(t)$ time and space per iteration, and, when the only information on the losses is their convexity, achieve a minimax optimal $\mathcal{O}(\sqrt{T})$ regret. Nonetheless, many common losses in kernel problems, such as squared loss, logistic loss, and squared hinge loss posses stronger curvature that can be exploited. In this case, second-order KOCO methods achieve $\mathcal{O}(\log(\text{Det}(\boldsymbol{K})))$ regret, which we show scales as $\mathcal{O}(d_{\text{eff}}\log T)$, where $d_{\text{eff}}$ is the effective dimension of the problem and is usually much smaller than $\mathcal{O}(\sqrt{T})$. The main drawback of second-order methods is their much higher $\mathcal{O}(t^2)$ space and time complexity. In this paper, we introduce kernel online Newton step (KONS), a new second-order KOCO method that also achieves $\mathcal{O}(d_{\text{eff}}\log T)$ regret. To address the computational complexity of second-order methods, we introduce a new matrix sketching algorithm for the kernel matrix $\boldsymbol{K}_t$, and show that for a chosen parameter $\gamma \leq 1$ our Sketched-KONS reduces the space and time complexity by a factor of $\gamma^2$ to $\mathcal{O}(t^2\gamma^2)$ space and time per iteration, while incurring only $1/\gamma$ times more regret.
Experimental results : Reinforcement Learning of POMDPs using Spectral Methods
May 07, 2017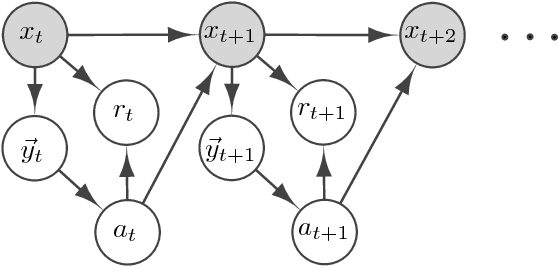
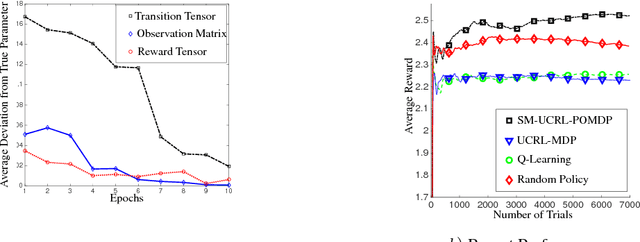
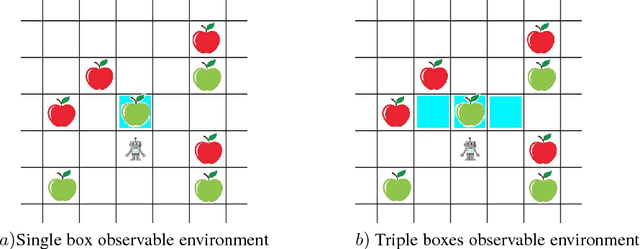
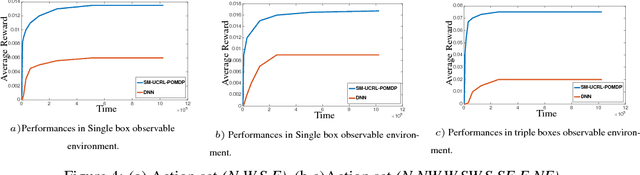
We propose a new reinforcement learning algorithm for partially observable Markov decision processes (POMDP) based on spectral decomposition methods. While spectral methods have been previously employed for consistent learning of (passive) latent variable models such as hidden Markov models, POMDPs are more challenging since the learner interacts with the environment and possibly changes the future observations in the process. We devise a learning algorithm running through epochs, in each epoch we employ spectral techniques to learn the POMDP parameters from a trajectory generated by a fixed policy. At the end of the epoch, an optimization oracle returns the optimal memoryless planning policy which maximizes the expected reward based on the estimated POMDP model. We prove an order-optimal regret bound with respect to the optimal memoryless policy and efficient scaling with respect to the dimensionality of observation and action spaces.
* 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain
Exploration--Exploitation in MDPs with Options
Apr 17, 2017
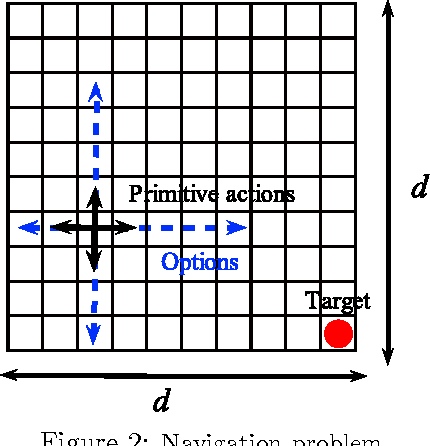
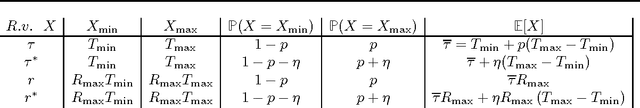
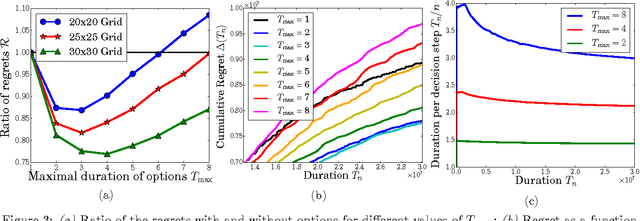
While a large body of empirical results show that temporally-extended actions and options may significantly affect the learning performance of an agent, the theoretical understanding of how and when options can be beneficial in online reinforcement learning is relatively limited. In this paper, we derive an upper and lower bound on the regret of a variant of UCRL using options. While we first analyze the algorithm in the general case of semi-Markov decision processes (SMDPs), we show how these results can be translated to the specific case of MDPs with options and we illustrate simple scenarios in which the regret of learning with options can be \textit{provably} much smaller than the regret suffered when learning with primitive actions.
Linear Thompson Sampling Revisited
Mar 27, 2017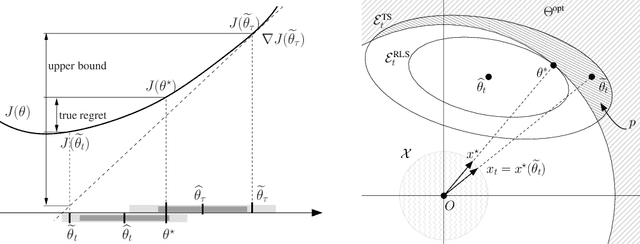
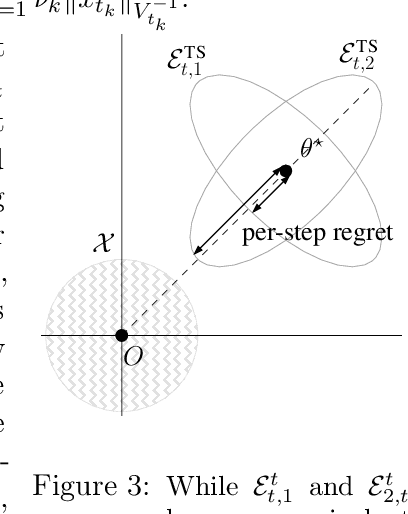
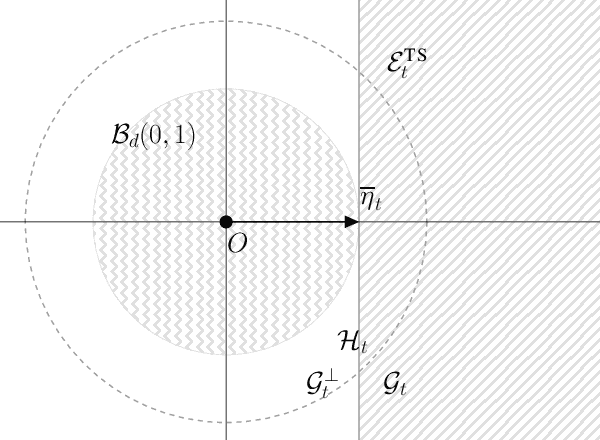
We derive an alternative proof for the regret of Thompson sampling (\ts) in the stochastic linear bandit setting. While we obtain a regret bound of order $\widetilde{O}(d^{3/2}\sqrt{T})$ as in previous results, the proof sheds new light on the functioning of the \ts. We leverage on the structure of the problem to show how the regret is related to the sensitivity (i.e., the gradient) of the objective function and how selecting optimal arms associated to \textit{optimistic} parameters does control it. Thus we show that \ts can be seen as a generic randomized algorithm where the sampling distribution is designed to have a fixed probability of being optimistic, at the cost of an additional $\sqrt{d}$ regret factor compared to a UCB-like approach. Furthermore, we show that our proof can be readily applied to regularized linear optimization and generalized linear model problems.
Thompson Sampling for Linear-Quadratic Control Problems
Mar 27, 2017
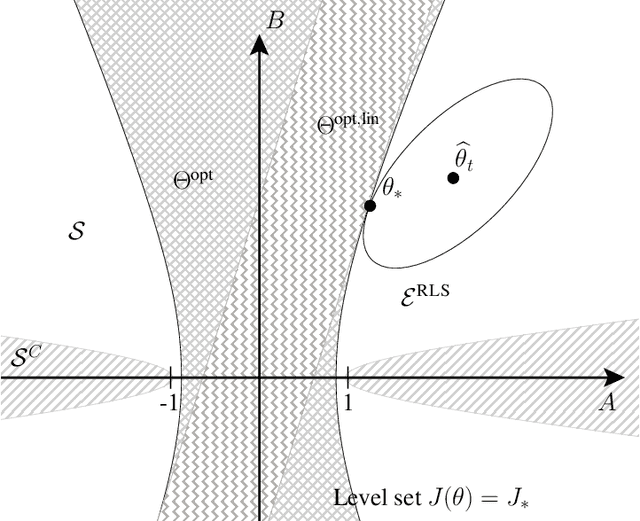
We consider the exploration-exploitation tradeoff in linear quadratic (LQ) control problems, where the state dynamics is linear and the cost function is quadratic in states and controls. We analyze the regret of Thompson sampling (TS) (a.k.a. posterior-sampling for reinforcement learning) in the frequentist setting, i.e., when the parameters characterizing the LQ dynamics are fixed. Despite the empirical and theoretical success in a wide range of problems from multi-armed bandit to linear bandit, we show that when studying the frequentist regret TS in control problems, we need to trade-off the frequency of sampling optimistic parameters and the frequency of switches in the control policy. This results in an overall regret of $O(T^{2/3})$, which is significantly worse than the regret $O(\sqrt{T})$ achieved by the optimism-in-face-of-uncertainty algorithm in LQ control problems.
Analysis of Kelner and Levin graph sparsification algorithm for a streaming setting
Sep 13, 2016

We derive a new proof to show that the incremental resparsification algorithm proposed by Kelner and Levin (2013) produces a spectral sparsifier in high probability. We rigorously take into account the dependencies across subsequent resparsifications using martingale inequalities, fixing a flaw in the original analysis.
Open Problem: Approximate Planning of POMDPs in the class of Memoryless Policies
Aug 17, 2016
Planning plays an important role in the broad class of decision theory. Planning has drawn much attention in recent work in the robotics and sequential decision making areas. Recently, Reinforcement Learning (RL), as an agent-environment interaction problem, has brought further attention to planning methods. Generally in RL, one can assume a generative model, e.g. graphical models, for the environment, and then the task for the RL agent is to learn the model parameters and find the optimal strategy based on these learnt parameters. Based on environment behavior, the agent can assume various types of generative models, e.g. Multi Armed Bandit for a static environment, or Markov Decision Process (MDP) for a dynamic environment. The advantage of these popular models is their simplicity, which results in tractable methods of learning the parameters and finding the optimal policy. The drawback of these models is again their simplicity: these models usually underfit and underestimate the actual environment behavior. For example, in robotics, the agent usually has noisy observations of the environment inner state and MDP is not a suitable model. More complex models like Partially Observable Markov Decision Process (POMDP) can compensate for this drawback. Fitting this model to the environment, where the partial observation is given to the agent, generally gives dramatic performance improvement, sometimes unbounded improvement, compared to MDP. In general, finding the optimal policy for the POMDP model is computationally intractable and fully non convex, even for the class of memoryless policies. The open problem is to come up with a method to find an exact or an approximate optimal stochastic memoryless policy for POMDP models.
* arXiv admin note: substantial text overlap with arXiv:1602.07764
Reinforcement Learning of POMDPs using Spectral Methods
May 29, 2016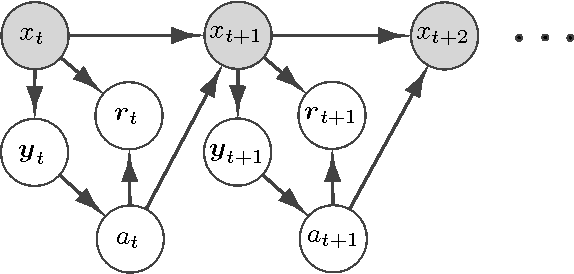
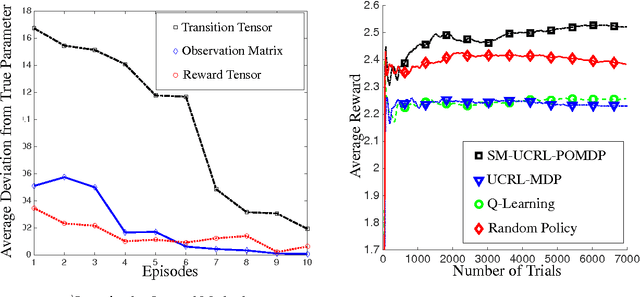
We propose a new reinforcement learning algorithm for partially observable Markov decision processes (POMDP) based on spectral decomposition methods. While spectral methods have been previously employed for consistent learning of (passive) latent variable models such as hidden Markov models, POMDPs are more challenging since the learner interacts with the environment and possibly changes the future observations in the process. We devise a learning algorithm running through episodes, in each episode we employ spectral techniques to learn the POMDP parameters from a trajectory generated by a fixed policy. At the end of the episode, an optimization oracle returns the optimal memoryless planning policy which maximizes the expected reward based on the estimated POMDP model. We prove an order-optimal regret bound with respect to the optimal memoryless policy and efficient scaling with respect to the dimensionality of observation and action spaces.
Incremental Spectral Sparsification for Large-Scale Graph-Based Semi-Supervised Learning
Jan 21, 2016


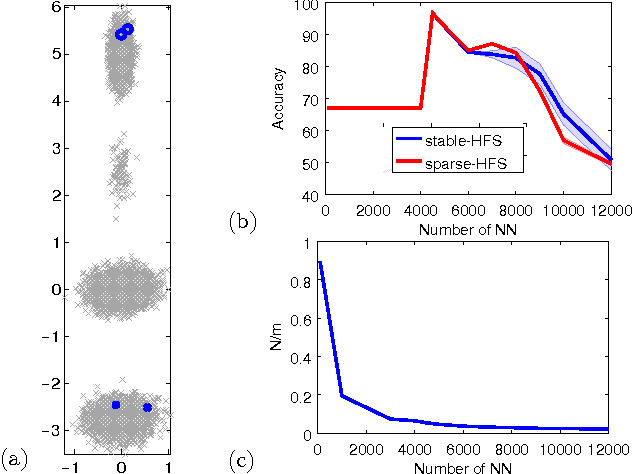
While the harmonic function solution performs well in many semi-supervised learning (SSL) tasks, it is known to scale poorly with the number of samples. Recent successful and scalable methods, such as the eigenfunction method focus on efficiently approximating the whole spectrum of the graph Laplacian constructed from the data. This is in contrast to various subsampling and quantization methods proposed in the past, which may fail in preserving the graph spectra. However, the impact of the approximation of the spectrum on the final generalization error is either unknown, or requires strong assumptions on the data. In this paper, we introduce Sparse-HFS, an efficient edge-sparsification algorithm for SSL. By constructing an edge-sparse and spectrally similar graph, we are able to leverage the approximation guarantees of spectral sparsification methods to bound the generalization error of Sparse-HFS. As a result, we obtain a theoretically-grounded approximation scheme for graph-based SSL that also empirically matches the performance of known large-scale methods.