 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatryoshka Gaussian Splatting
Mar 19, 2026The ability to render scenes at adjustable fidelity from a single model, known as level of detail (LoD), is crucial for practical deployment of 3D Gaussian Splatting (3DGS). Existing discrete LoD methods expose only a limited set of operating points, while concurrent continuous LoD approaches enable smoother scaling but often suffer noticeable quality degradation at full capacity, making LoD a costly design decision. We introduce Matryoshka Gaussian Splatting (MGS), a training framework that enables continuous LoD for standard 3DGS pipelines without sacrificing full-capacity rendering quality. MGS learns a single ordered set of Gaussians such that rendering any prefix, the first k splats, produces a coherent reconstruction whose fidelity improves smoothly with increasing budget. Our key idea is stochastic budget training: each iteration samples a random splat budget and optimises both the corresponding prefix and the full set. This strategy requires only two forward passes and introduces no architectural modifications. Experiments across four benchmarks and six baselines show that MGS matches the full-capacity performance of its backbone while enabling a continuous speed-quality trade-off from a single model. Extensive ablations on ordering strategies, training objectives, and model capacity further validate the designs.
Quartet of Diffusions: Structure-Aware Point Cloud Generation through Part and Symmetry Guidance
Jan 28, 2026We introduce the Quartet of Diffusions, a structure-aware point cloud generation framework that explicitly models part composition and symmetry. Unlike prior methods that treat shape generation as a holistic process or only support part composition, our approach leverages four coordinated diffusion models to learn distributions of global shape latents, symmetries, semantic parts, and their spatial assembly. This structured pipeline ensures guaranteed symmetry, coherent part placement, and diverse, high-quality outputs. By disentangling the generative process into interpretable components, our method supports fine-grained control over shape attributes, enabling targeted manipulation of individual parts while preserving global consistency. A central global latent further reinforces structural coherence across assembled parts. Our experiments show that the Quartet achieves state-of-the-art performance. To our best knowledge, this is the first 3D point cloud generation framework that fully integrates and enforces both symmetry and part priors throughout the generative process.
Features Emerge as Discrete States: The First Application of SAEs to 3D Representations
Dec 15, 2025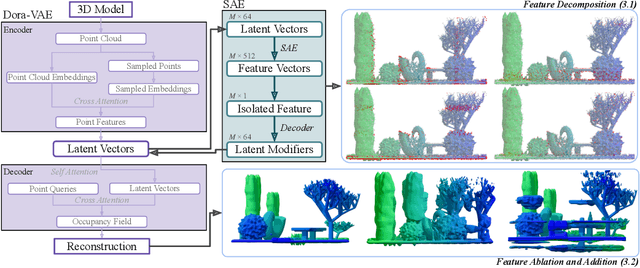

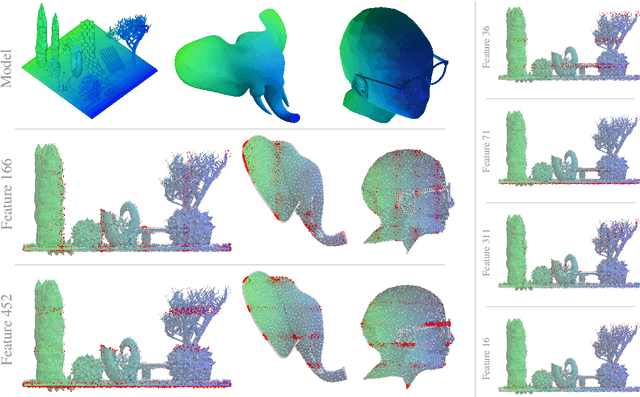
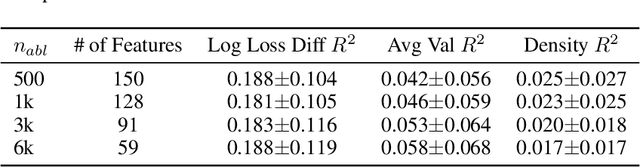
Sparse Autoencoders (SAEs) are a powerful dictionary learning technique for decomposing neural network activations, translating the hidden state into human ideas with high semantic value despite no external intervention or guidance. However, this technique has rarely been applied outside of the textual domain, limiting theoretical explorations of feature decomposition. We present the first application of SAEs to the 3D domain, analyzing the features used by a state-of-the-art 3D reconstruction VAE applied to 53k 3D models from the Objaverse dataset. We observe that the network encodes discrete rather than continuous features, leading to our key finding: such models approximate a discrete state space, driven by phase-like transitions from feature activations. Through this state transition framework, we address three otherwise unintuitive behaviors - the inclination of the reconstruction model towards positional encoding representations, the sigmoidal behavior of reconstruction loss from feature ablation, and the bimodality in the distribution of phase transition points. This final observation suggests the model redistributes the interference caused by superposition to prioritize the saliency of different features. Our work not only compiles and explains unexpected phenomena regarding feature decomposition, but also provides a framework to explain the model's feature learning dynamics. The code and dataset of encoded 3D objects will be available on release.