 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBT-DINO: Towards Foundation model based analysis of Digital Breast Tomosynthesis
Dec 15, 2025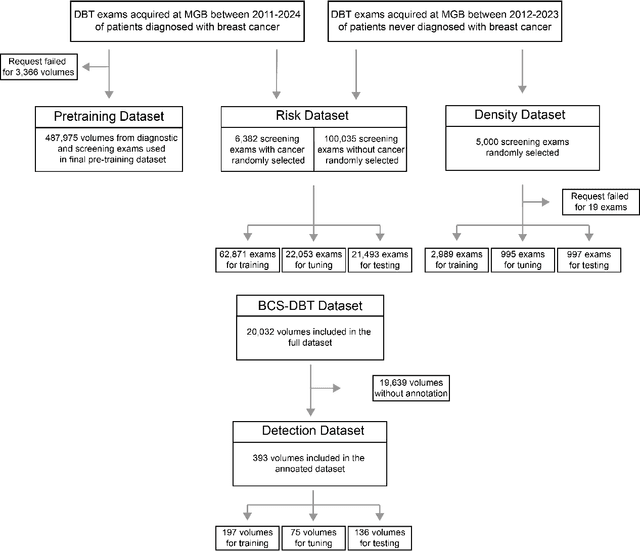
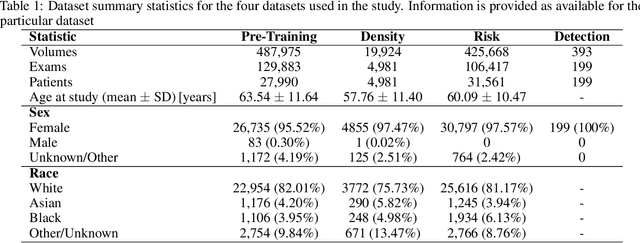
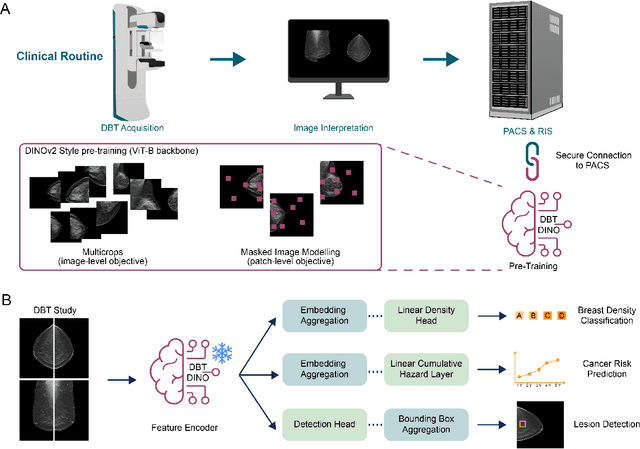

Foundation models have shown promise in medical imaging but remain underexplored for three-dimensional imaging modalities. No foundation model currently exists for Digital Breast Tomosynthesis (DBT), despite its use for breast cancer screening. To develop and evaluate a foundation model for DBT (DBT-DINO) across multiple clinical tasks and assess the impact of domain-specific pre-training. Self-supervised pre-training was performed using the DINOv2 methodology on over 25 million 2D slices from 487,975 DBT volumes from 27,990 patients. Three downstream tasks were evaluated: (1) breast density classification using 5,000 screening exams; (2) 5-year risk of developing breast cancer using 106,417 screening exams; and (3) lesion detection using 393 annotated volumes. For breast density classification, DBT-DINO achieved an accuracy of 0.79 (95\% CI: 0.76--0.81), outperforming both the MetaAI DINOv2 baseline (0.73, 95\% CI: 0.70--0.76, p<.001) and DenseNet-121 (0.74, 95\% CI: 0.71--0.76, p<.001). For 5-year breast cancer risk prediction, DBT-DINO achieved an AUROC of 0.78 (95\% CI: 0.76--0.80) compared to DINOv2's 0.76 (95\% CI: 0.74--0.78, p=.57). For lesion detection, DINOv2 achieved a higher average sensitivity of 0.67 (95\% CI: 0.60--0.74) compared to DBT-DINO with 0.62 (95\% CI: 0.53--0.71, p=.60). DBT-DINO demonstrated better performance on cancerous lesions specifically with a detection rate of 78.8\% compared to Dinov2's 77.3\%. Using a dataset of unprecedented size, we developed DBT-DINO, the first foundation model for DBT. DBT-DINO demonstrated strong performance on breast density classification and cancer risk prediction. However, domain-specific pre-training showed variable benefits on the detection task, with ImageNet baseline outperforming DBT-DINO on general lesion detection, indicating that localized detection tasks require further methodological development.
Deep Learning-based Prediction of Breast Cancer Tumor and Immune Phenotypes from Histopathology
Apr 25, 2024



The interactions between tumor cells and the tumor microenvironment (TME) dictate therapeutic efficacy of radiation and many systemic therapies in breast cancer. However, to date, there is not a widely available method to reproducibly measure tumor and immune phenotypes for each patient's tumor. Given this unmet clinical need, we applied multiple instance learning (MIL) algorithms to assess activity of ten biologically relevant pathways from the hematoxylin and eosin (H&E) slide of primary breast tumors. We employed different feature extraction approaches and state-of-the-art model architectures. Using binary classification, our models attained area under the receiver operating characteristic (AUROC) scores above 0.70 for nearly all gene expression pathways and on some cases, exceeded 0.80. Attention maps suggest that our trained models recognize biologically relevant spatial patterns of cell sub-populations from H&E. These efforts represent a first step towards developing computational H&E biomarkers that reflect facets of the TME and hold promise for augmenting precision oncology.
Is Open-Source There Yet? A Comparative Study on Commercial and Open-Source LLMs in Their Ability to Label Chest X-Ray Reports
Feb 19, 2024



Introduction: With the rapid advances in large language models (LLMs), there have been numerous new open source as well as commercial models. While recent publications have explored GPT-4 in its application to extracting information of interest from radiology reports, there has not been a real-world comparison of GPT-4 to different leading open-source models. Materials and Methods: Two different and independent datasets were used. The first dataset consists of 540 chest x-ray reports that were created at the Massachusetts General Hospital between July 2019 and July 2021. The second dataset consists of 500 chest x-ray reports from the ImaGenome dataset. We then compared the commercial models GPT-3.5 Turbo and GPT-4 from OpenAI to the open-source models Mistral-7B, Mixtral-8x7B, Llama2-13B, Llama2-70B, QWEN1.5-72B and CheXbert and CheXpert-labeler in their ability to accurately label the presence of multiple findings in x-ray text reports using different prompting techniques. Results: On the ImaGenome dataset, the best performing open-source model was Llama2-70B with micro F1-scores of 0.972 and 0.970 for zero- and few-shot prompts, respectively. GPT-4 achieved micro F1-scores of 0.975 and 0.984, respectively. On the institutional dataset, the best performing open-source model was QWEN1.5-72B with micro F1-scores of 0.952 and 0.965 for zero- and few-shot prompting, respectively. GPT-4 achieved micro F1-scores of 0.975 and 0.973, respectively. Conclusion: In this paper, we show that while GPT-4 is superior to open-source models in zero-shot report labeling, the implementation of few-shot prompting can bring open-source models on par with GPT-4. This shows that open-source models could be a performant and privacy preserving alternative to GPT-4 for the task of radiology report classification.