 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Code-switched Speech and Language Processing
Apr 02, 2019Code-switching, the alternation of languages within a conversation or utterance, is a common communicative phenomenon that occurs in multilingual communities across the world. This survey reviews computational approaches for code-switched Speech and Natural Language Processing. We motivate why processing code-switched text and speech is essential for building intelligent agents and systems that interact with users in multilingual communities. As code-switching data and resources are scarce, we list what is available in various code-switched language pairs with the language processing tasks they can be used for. We review code-switching research in various Speech and NLP applications, including language processing tools and end-to-end systems. We conclude with future directions and open problems in the field.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019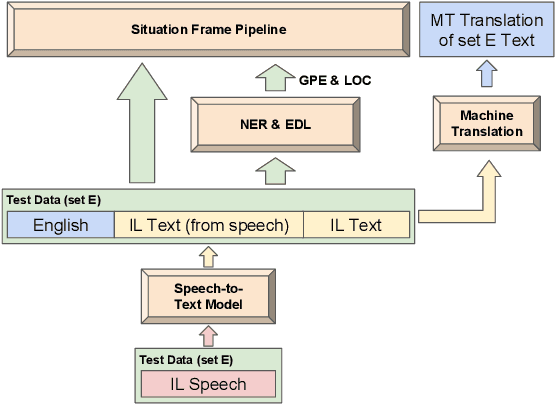
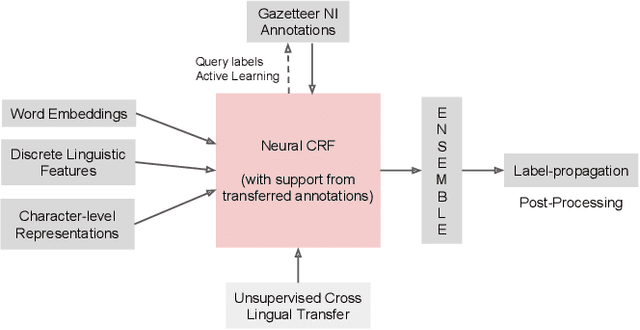
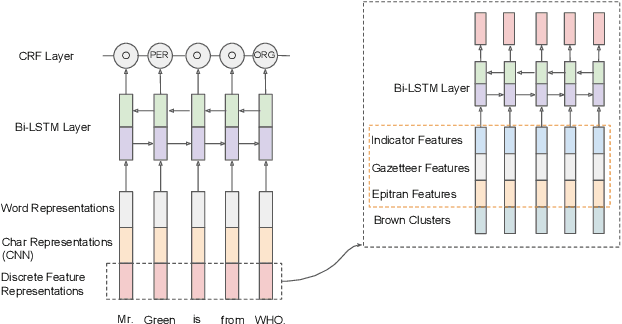
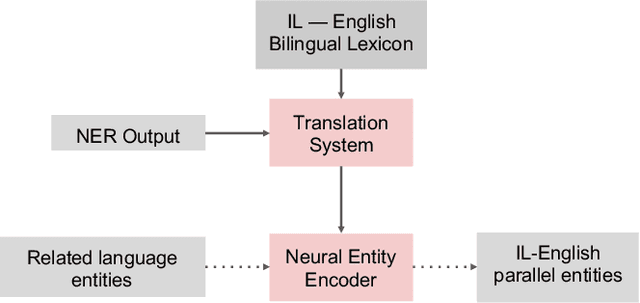
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).
Phoneme Level Language Models for Sequence Based Low Resource ASR
Feb 20, 2019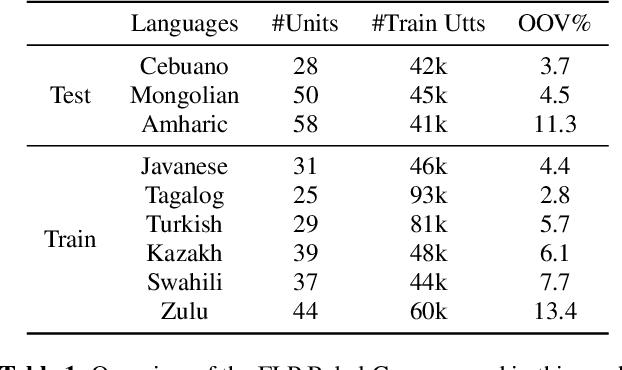
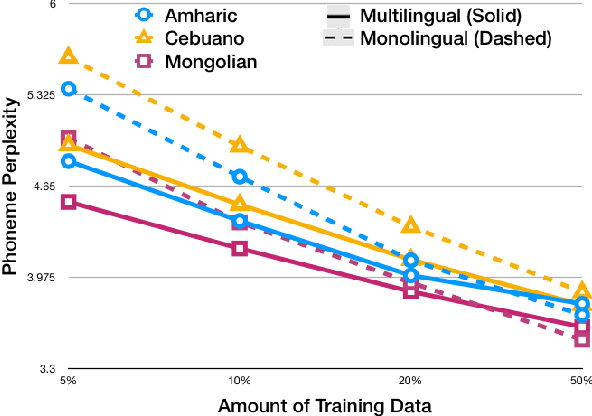
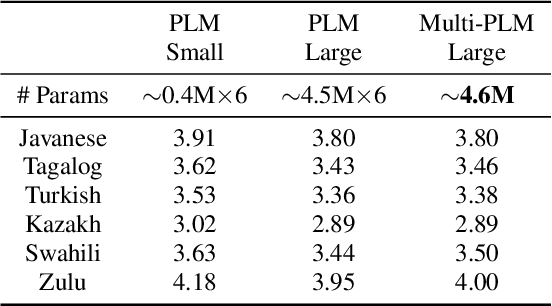
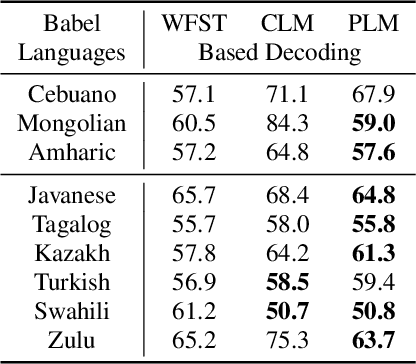
Building multilingual and crosslingual models help bring different languages together in a language universal space. It allows models to share parameters and transfer knowledge across languages, enabling faster and better adaptation to a new language. These approaches are particularly useful for low resource languages. In this paper, we propose a phoneme-level language model that can be used multilingually and for crosslingual adaptation to a target language. We show that our model performs almost as well as the monolingual models by using six times fewer parameters, and is capable of better adaptation to languages not seen during training in a low resource scenario. We show that these phoneme-level language models can be used to decode sequence based Connectionist Temporal Classification (CTC) acoustic model outputs to obtain comparable word error rates with Weighted Finite State Transducer (WFST) based decoding in Babel languages. We also show that these phoneme-level language models outperform WFST decoding in various low-resource conditions like adapting to a new language and domain mismatch between training and testing data.
The Second Conversational Intelligence Challenge (ConvAI2)
Jan 31, 2019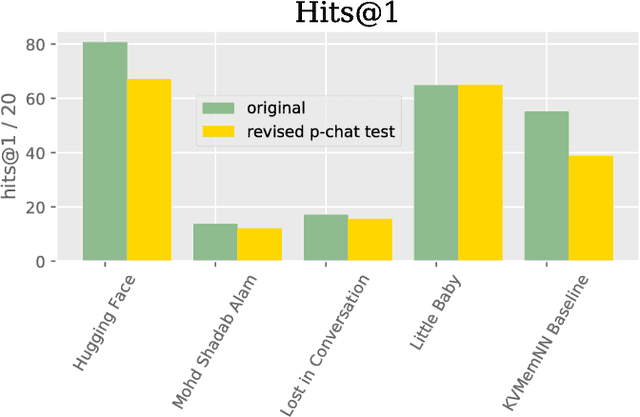

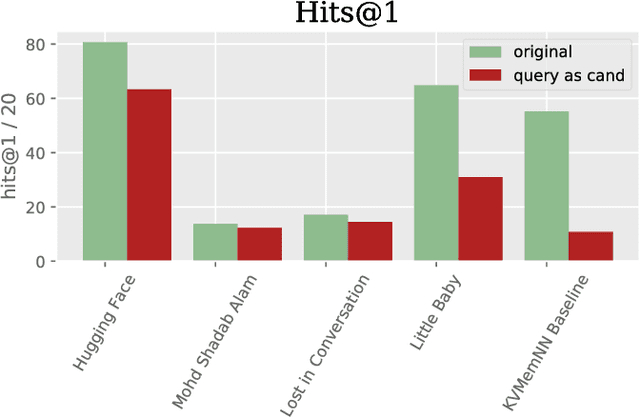
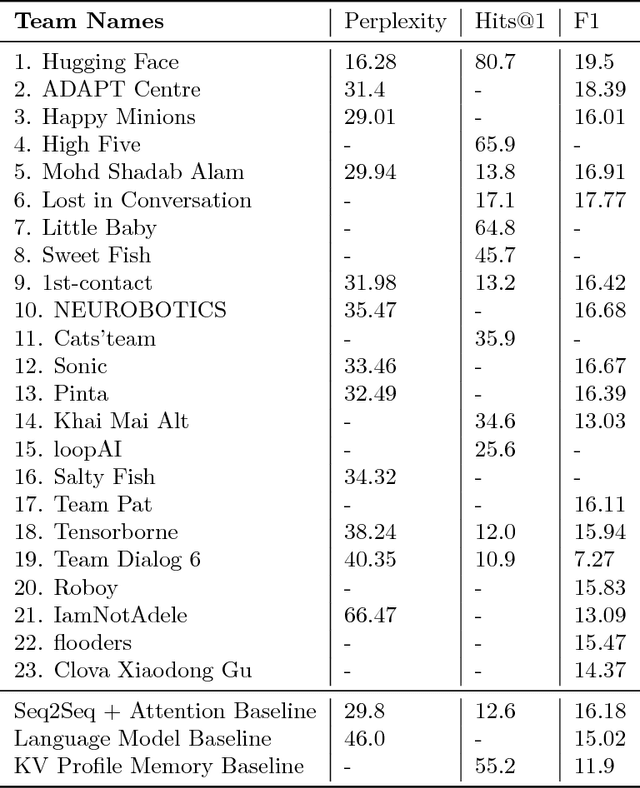
We describe the setting and results of the ConvAI2 NeurIPS competition that aims to further the state-of-the-art in open-domain chatbots. Some key takeaways from the competition are: (i) pretrained Transformer variants are currently the best performing models on this task, (ii) but to improve performance on multi-turn conversations with humans, future systems must go beyond single word metrics like perplexity to measure the performance across sequences of utterances (conversations) -- in terms of repetition, consistency and balance of dialogue acts (e.g. how many questions asked vs. answered).
Multimodal Polynomial Fusion for Detecting Driver Distraction
Oct 24, 2018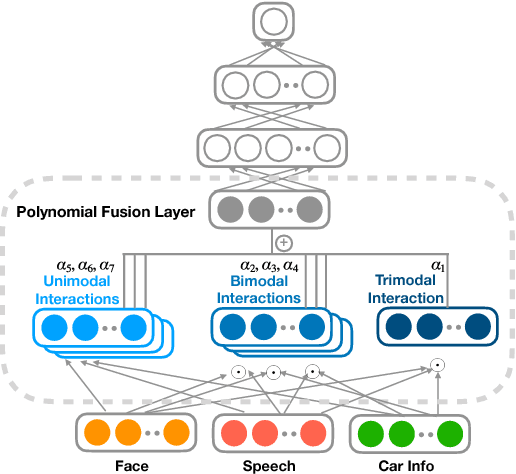
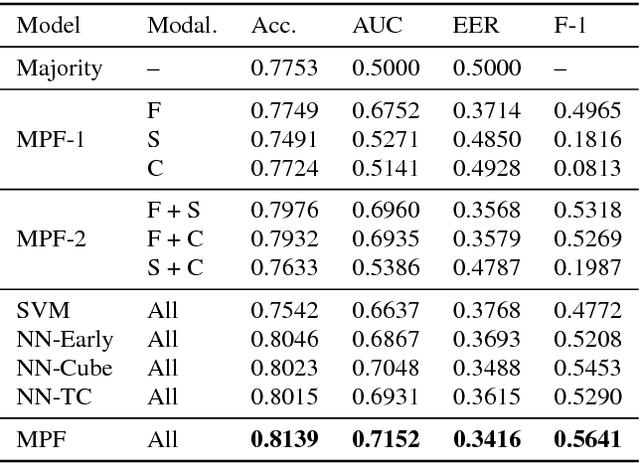
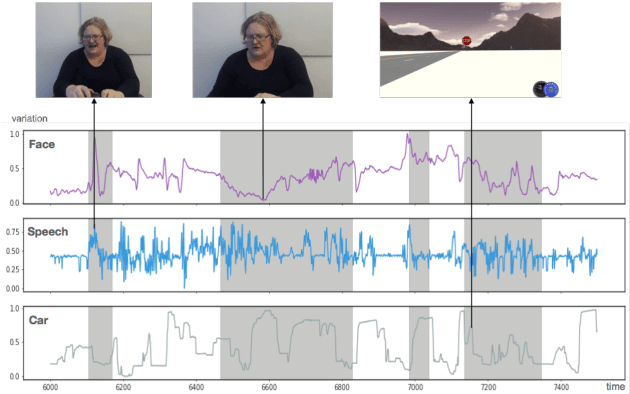
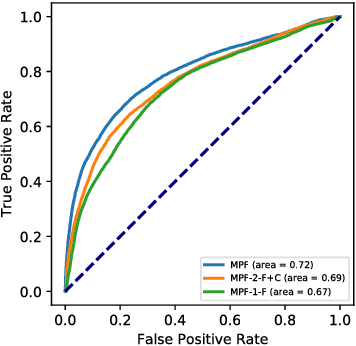
Distracted driving is deadly, claiming 3,477 lives in the U.S. in 2015 alone. Although there has been a considerable amount of research on modeling the distracted behavior of drivers under various conditions, accurate automatic detection using multiple modalities and especially the contribution of using the speech modality to improve accuracy has received little attention. This paper introduces a new multimodal dataset for distracted driving behavior and discusses automatic distraction detection using features from three modalities: facial expression, speech and car signals. Detailed multimodal feature analysis shows that adding more modalities monotonically increases the predictive accuracy of the model. Finally, a simple and effective multimodal fusion technique using a polynomial fusion layer shows superior distraction detection results compared to the baseline SVM and neural network models.
A Dataset for Document Grounded Conversations
Sep 19, 2018
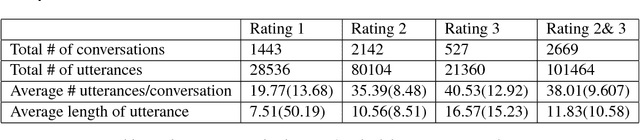
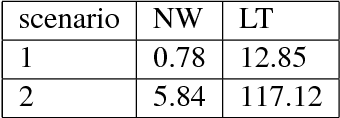
This paper introduces a document grounded dataset for text conversations. We define "Document Grounded Conversations" as conversations that are about the contents of a specified document. In this dataset the specified documents were Wikipedia articles about popular movies. The dataset contains 4112 conversations with an average of 21.43 turns per conversation. This positions this dataset to not only provide a relevant chat history while generating responses but also provide a source of information that the models could use. We describe two neural architectures that provide benchmark performance on the task of generating the next response. We also evaluate our models for engagement and fluency, and find that the information from the document helps in generating more engaging and fluent responses.
Style Transfer Through Multilingual and Feedback-Based Back-Translation
Sep 17, 2018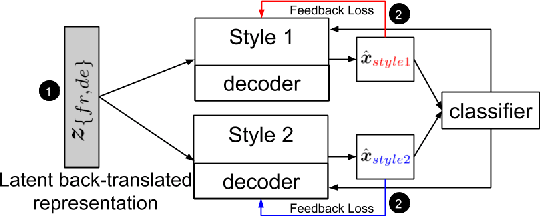
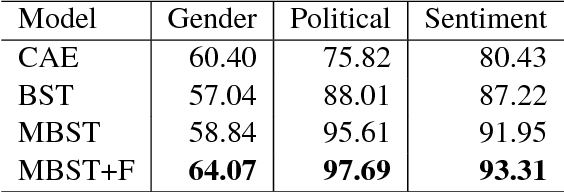

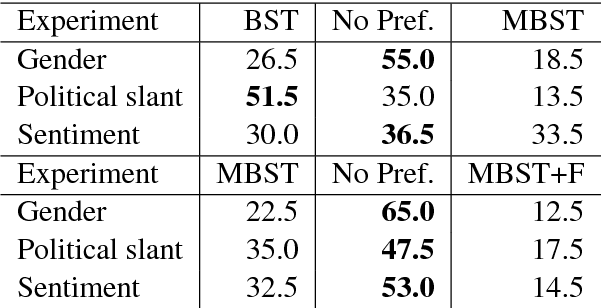
Style transfer is the task of transferring an attribute of a sentence (e.g., formality) while maintaining its semantic content. The key challenge in style transfer is to strike a balance between the competing goals, one to preserve meaning and the other to improve the style transfer accuracy. Prior research has identified that the task of meaning preservation is generally harder to attain and evaluate. This paper proposes two extensions of the state-of-the-art style transfer models aiming at improving the meaning preservation in style transfer. Our evaluation shows that these extensions help to ground meaning better while improving the transfer accuracy.
Data Augmentation for Neural Online Chat Response Selection
Sep 03, 2018


Data augmentation seeks to manipulate the available data for training to improve the generalization ability of models. We investigate two data augmentation proxies, permutation and flipping, for neural dialog response selection task on various models over multiple datasets, including both Chinese and English languages. Different from standard data augmentation techniques, our method combines the original and synthesized data for prediction. Empirical results show that our approach can gain 1 to 3 recall-at-1 points over baseline models in both full-scale and small-scale settings.
Generating Mandarin and Cantonese F0 Contours with Decision Trees and BLSTMs
Jul 04, 2018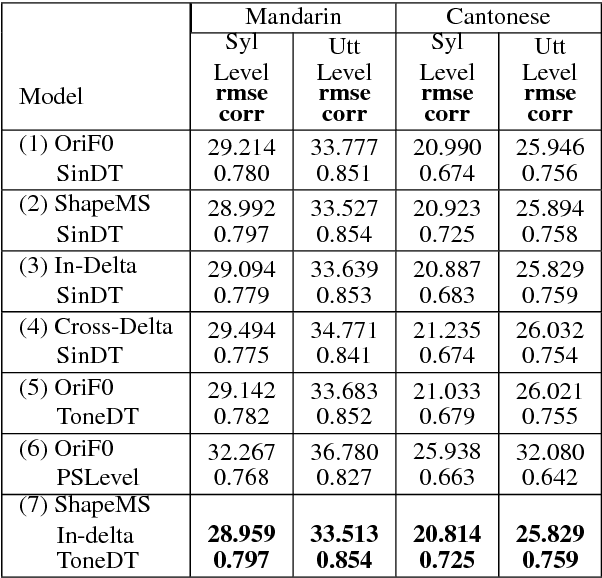
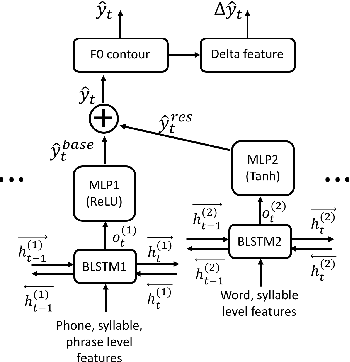
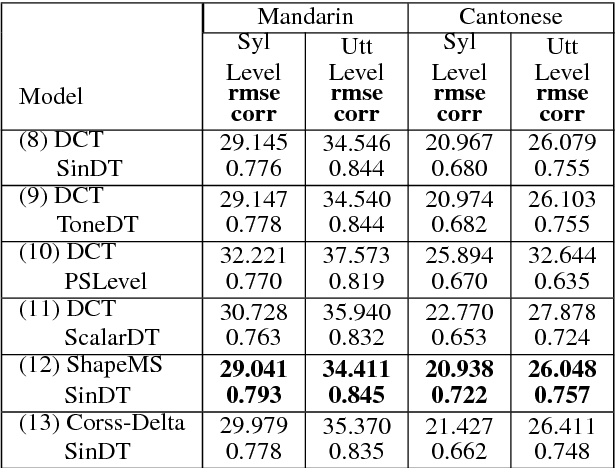
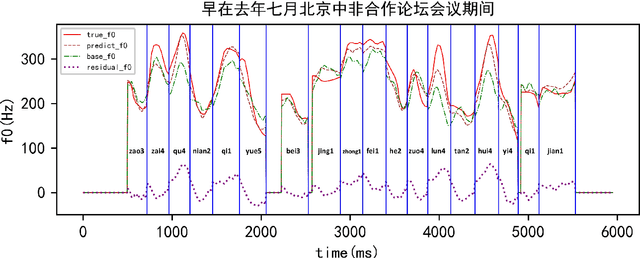
This paper models the fundamental frequency contours on both Mandarin and Cantonese speech with decision trees and DNNs (deep neural networks). Different kinds of f0 representations and model architectures are tested for decision trees and DNNs. A new model called Additive-BLSTM (additive bidirectional long short term memory) that predicts a base f0 contour and a residual f0 contour with two BLSTMs is proposed. With respect to objective measures of RMSE and correlation, applying tone-dependent trees together with sample normalization and delta feature regularization within decision tree framework performs best. While the new Additive-BLSTM model with delta feature regularization performs even better. Subjective listening tests on both Mandarin and Cantonese comparing Random Forest model (multiple decision trees) and the Additive-BLSTM model were also held and confirmed the advantage of the new model according to the listeners' preference.
Style Transfer Through Back-Translation
May 24, 2018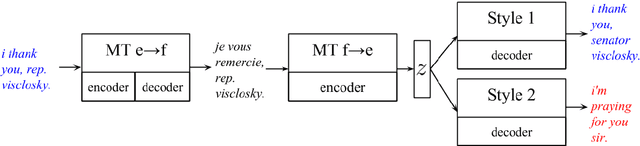
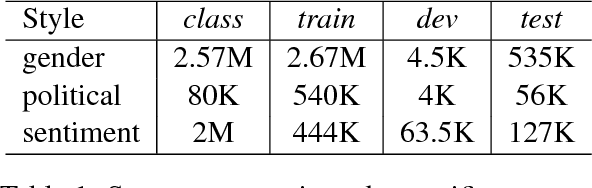
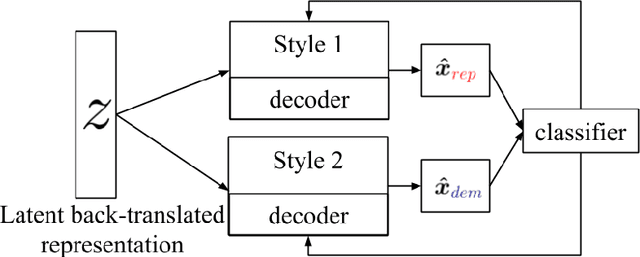
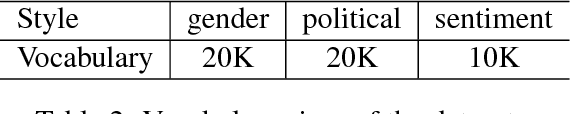
Style transfer is the task of rephrasing the text to contain specific stylistic properties without changing the intent or affect within the context. This paper introduces a new method for automatic style transfer. We first learn a latent representation of the input sentence which is grounded in a language translation model in order to better preserve the meaning of the sentence while reducing stylistic properties. Then adversarial generation techniques are used to make the output match the desired style. We evaluate this technique on three different style transformations: sentiment, gender and political slant. Compared to two state-of-the-art style transfer modeling techniques we show improvements both in automatic evaluation of style transfer and in manual evaluation of meaning preservation and fluency.